Meta-Research: Questionable research practices may have little effect on replicability
- Department of Psychology, University of Tübingen, Germany
- Department of Psychology, University of Otago, New Zealand
Abstract
This article examines why many studies fail to replicate statistically significant published results. We address this issue within a general statistical framework that also allows us to include various questionable research practices (QRPs) that are thought to reduce replicability. The analyses indicate that the base rate of true effects is the major factor that determines the replication rate of scientific results. Specifically, for purely statistical reasons, replicability is low in research domains where true effects are rare (e.g., search for effective drugs in pharmacology). This point is under-appreciated in current scientific and media discussions of replicability, which often attribute poor replicability mainly to QRPs.
Main text
Most sciences search for lawful data patterns or regularities to serve as the building blocks of theories (e.g., Bunge, 1967; Carnap, 1995; Popper, 2002). Generally, such data patterns must not be singular findings (i.e., chance findings) but instead be replicable by other researchers under similar conditions in order to be scientifically meaningful (Popper, 2002, p. 23). With this fundamental scientific premise as background, it is understandable that many researchers have become concerned that a surprisingly large number of published results cannot be replicated in independent studies and hence appear to represent chance findings or so-called false positive results (Baker and Penny, 2016; Ioannidis, 2005b; Pashler and Harris, 2012; Simmons et al., 2011; Zwaan et al., 2018). For example, only less than 30% of results in social psychology and about 50% in cognitive psychology appear to be reproducible (Open Science Collaboration, 2015). Similarly, the replication rate of 21 systematically selected experimental studies in the social sciences published between 2010 and 2015 in Nature and Science was estimated to be only about 62% (Camerer et al., 2018). Low replication rates have also been reported in medical research (Begley and Ellis, 2012; Ioannidis, 2005a; Prinz et al., 2011): for example, researchers at the biotechnology firm Amgen tried to confirm findings in 53 landmark studies in preclinical cancer research, but were able to do so for only six cases (Begley and Ellis, 2012). The Reproducibility Project: Cancer Biology was set up to further explore the reproducibility of preclinical cancer research (Errington et al., 2014).
Possible causes of low replication rates
Understanding the causes of these shockingly low replication rates has received much attention (e.g., Button and Munafò, 2017; Pashler and Harris, 2012; Schmidt and Oh, 2016), and various possibilities have been discussed. First, scientists may fabricate data to support their hypotheses. However, surveys indicate that this is probably not a major cause because the prevalence of scientific fraud is low—probably smaller than 2% (see Fanelli, 2009; Gross, 2016; Stroebe et al., 2012).
Second, Benjamin et al., 2018 recently argued that the traditional level of 5% is too large and thus produces too many false positives. These authors suggested changing the critical level to 0.5%, because this “would immediately improve the reproducibility of scientific research in many fields” (p. 6). Although this change would decrease the false positive rate, it would also increase the proportion of false negatives unless there were substantial increases in sample size (Fiedler et al., 2012).
Third, another important factor seems to be the typically low statistical power in psychological research (Button and Munafò, 2017; Stanley et al., 2018). Some have reported average power estimates as high as 50% to detect a correlation of 0.2 (corresponding to Cohen’s ) in the field of social-personality psychology (Fraley and Vazire, 2014). In a large survey of over 12,000 effect sizes, however, Stanley et al., 2018 reported that median power was about 36% and that only 8% of all studies had a power of about 80%. Even lower median power of about 21% has been reported for studies in the neurosciences (Button et al., 2013). Low power within a research area reduces replicability for purely statistical reasons, because it reduces the ratio of true positives to false positives.
Fourth, the percentage or “base rate” of true effects within a research area strongly influences the replication rate (Miller, 2009; Miller and Ulrich, 2016; Wilson and Wixted, 2018). When is small, the relative proportion of false positives within a given research domain will be high (Ioannidis, 2005b; Oberauer and Lewandowsky, 2019), and thus the replication rate will be low. This is easily seen: for the relative proportion of false positives is 100%. In contrast, for , no false positives can occur so this proportion is zero. Consequently, replication rates must be higher when the base rate is relatively high than when it is low. For example, Wilson and Wixted, 2018 have argued that the fields of cognitive and social psychology differ in the base rate of real effects that are investigated, which they call the “prior odds.” On the basis of the results obtained by the Open Science Collaboration, 2015, they estimated base rates of for cognitive psychology and for social psychology, and these estimates are consistent with the finding that the replication rate is lower for social than cognitive psychology. Alternative analyses of replication rates and prediction markets also suggest similarly low base rates of about 10% (Dreber et al., 2015; Johnson et al., 2017; Miller and Ulrich, 2016). More generally, it is reasonable to assume that base rates differ between discovery-oriented research and theory-testing research (Lewandowsky and Oberauer, 2020; Oberauer and Lewandowsky, 2019).
Finally, a certain percentage of false positive results is an unavoidable by-product of null hypothesis testing, and, more generally, of any uncertain dichotomous-choice situation in which one is required to choose between two alternatives, such as “accept” or “reject” a vaccine as beneficial in the fight against a certain infectious disease. In such situations, many have argued that replication rates are low because questionable research practices (QRPs) used by scientists chasing after statistically significant results produce an excess of false positive results beyond the usual nominal significance level of 5% (Ioannidis and Trikalinos, 2007; John et al., 2012; Simmons et al., 2011). Such practices violate not only the basic assumptions of the null hypothesis significance testing (NHST) framework but also those underlying decision making within the Bayesian framework, where researchers could analogously use QRPs to obtain large Bayes factors (Simonsohn, 2014).
Hence, a bias toward publication of significant results or large Bayes factors provides a strong incentive to use QRPs (Bakker et al., 2012), especially when competing for academic promotion (Asendorpf et al., 2013) or grant funding (Lilienfeld, 2017). A survey conducted by John et al., 2012 identified several such practices, and the most frequent ones can be grouped into four categories (a) A researcher may capitalize on chance by performing multiple studies and using selective reporting of a significant result. For example, the researcher may conduct several similar experiments until one finally yields the hoped-for significant result, and then the researcher only reports the results of the one study that ‘worked’, putting negative results into the file drawer (Rosenthal, 1979). There is convincing evidence that researchers conduct several studies to examine a hypothesis but only report those studies that yielded confirming results (Francis, 2014; Francis et al., 2014). (b) A researcher may measure multiple dependent measures and report only those that yield significant results. For example, a neuroscientist could record brain activity in hundreds of distinct brain areas and report the results only for those that were sensitive to a specific experimental manipulation (Vul et al., 2009). With 10 moderately correlated dependent measures (i.e., ) and one-tailed tests, for example, this strategy of multiple testing raises the rate of false positives from 5% to 34%. (c) A researcher may monitor data collection, repeatedly testing for significant results, and stop data collection when a significant result is attained. This strategy of data peeking can easily raise the rate of false positives up to 20% (Simmons et al., 2011). (d) Finally, selective outlier removal can also turn a nonsignificant result into a significant one (Ulrich and Miller, 1994). For example, if an initial analysis produces nonsignificant results, a researcher may try different criteria for excluding outliers in the hope of getting significant results after the data have been ‘cleaned’.
With all four of these QRPs as well as other ones, the researcher exploits the degrees of freedom present in the research process to achieve a statistically significant result—a practice that has been referred as “p-hacking” (Simonsohn et al., 2014a). This clearly inflates the rate of false positives, which would intuitively be expected to decrease replicability. What has received considerably less attention, however, is that p-hacking also increases the statistical power for detecting true effects, as noted recently by Witt, 2019—a side-effect of p-hacking that might be termed power inflation. Since increasing power also increases replication rates, the influence of QRPs on power tends to counteract its influence on Type 1 error rate with respect to overall replicability. A quantitative model is therefore needed to assess the size of p-hacking’s overall effect on replicability.
In this paper, we consider in detail the prevailing claim that QRPs are a major cause of low replicability. However, Francis, 2012a has noted the converse problem that in some circumstances QRPs can artificially increase replication rates. Specifically, this can happen when researchers use QRPs to significantly replicate their previous findings—usually with conceptual replications—to strengthen their theoretical position. Reanalyses of results from multi-experiment papers suggest that this does happen, because the rate of successful replication is unrealistically large in view of the studies’ power (e.g., Francis et al., 2014; Francis, 2012b). For example, when the power of a single experiment is 0.36, the probability that a series of five experiments would all result in positive outcomes is 0.365 = 0.006, so such a series of published findings would be too good to be true (i.e., an excess of positive results). Such a pattern would suggest the operation of one or more QRPs; for example, negative results may have been unreported, that is, put in the researcher’s file drawer. This situation could be called “motivated replication” and it is different from the situation in which an unbiased researcher tries to replicate a significant result, as in the Open Science Replication Project (Open Science Collaboration, 2015), We shall focus on the situation with unbiased replications and assess the extent to which QRPs can reduce the rate of these.
In the present study, we develop a quantitative model of replication rate that simultaneously takes into account , power, the base rate of true effects, and p-hacking. This model allows us to assess the relative contributions of these factors to the replication rate, with a focus on the influence of QRPs. In contrast, the combined effects of p-hacking on Type 1 error rate and power have not previously been modelled at all, and previous studies have generally considered the effects of these factors on replicability one at a time (e.g., , power, base rate), making it difficult to see their relative contributions. Knowledge of the relative contributions of these different factors would increase our understanding of why the observed replication rate is so low and thus be useful in guiding efforts to improve the situation. Because the various different p-hacking strategies reviewed above may have different impacts on the replication rate, we conducted separate analyses for each strategy.
Statistical analysis of the replication scenario
The analyses in this manuscript address replication scenarios in which researchers conduct direct replications of studies that reported a statistically significant positive outcome. An example is the Open Science Replication Project (Open Science Collaboration, 2015), in which many independent research teams conducted high-powered studies attempting to directly replicate published results. Figure 1 depicts these scenarios together with all statistically relevant parameters that must be taken into account when computing the rate of replicating significant results (Miller, 2009; Miller and Ulrich, 2016; Miller and Schwarz, 2011). First, each original study tests either a true effect (i.e., is true) or a null effect (i.e., is true), with base rate probabilities and , respectively, and these probabilities—sometimes called “pre-study probabilities” (Ioannidis, 2005b) or “prior odds” (Wilson and Wixted, 2018)—may vary across research fields (Wilson and Wixted, 2018). If the original study tests a true effect, its statistical power is and the Type 2 error probability is equal to . Thus, the compound probability of examining a true effect and rejecting the null hypothesis is ; this outcome is called a “true positive.” In contrast, if the original study tests a null effect, its Type 1 error probability is . Thus, the probability of testing a null effect and falsely rejecting is ; this outcome reflects a “false positive.” Note that, in keeping with accepted procedures for null hypothesis testing, we categorize studies as rejecting the null hypothesis or not based on an all-or-none comparison of computed p-values relative to an level cutoff. Such a discrete categorization is, for example, how most journals currently evaluate statistical results in publication decisions and how replication success or failure has mainly been operationalized in empirical studies of replication rates (Camerer et al., 2018; Open Science Collaboration, 2015).
Figure 1
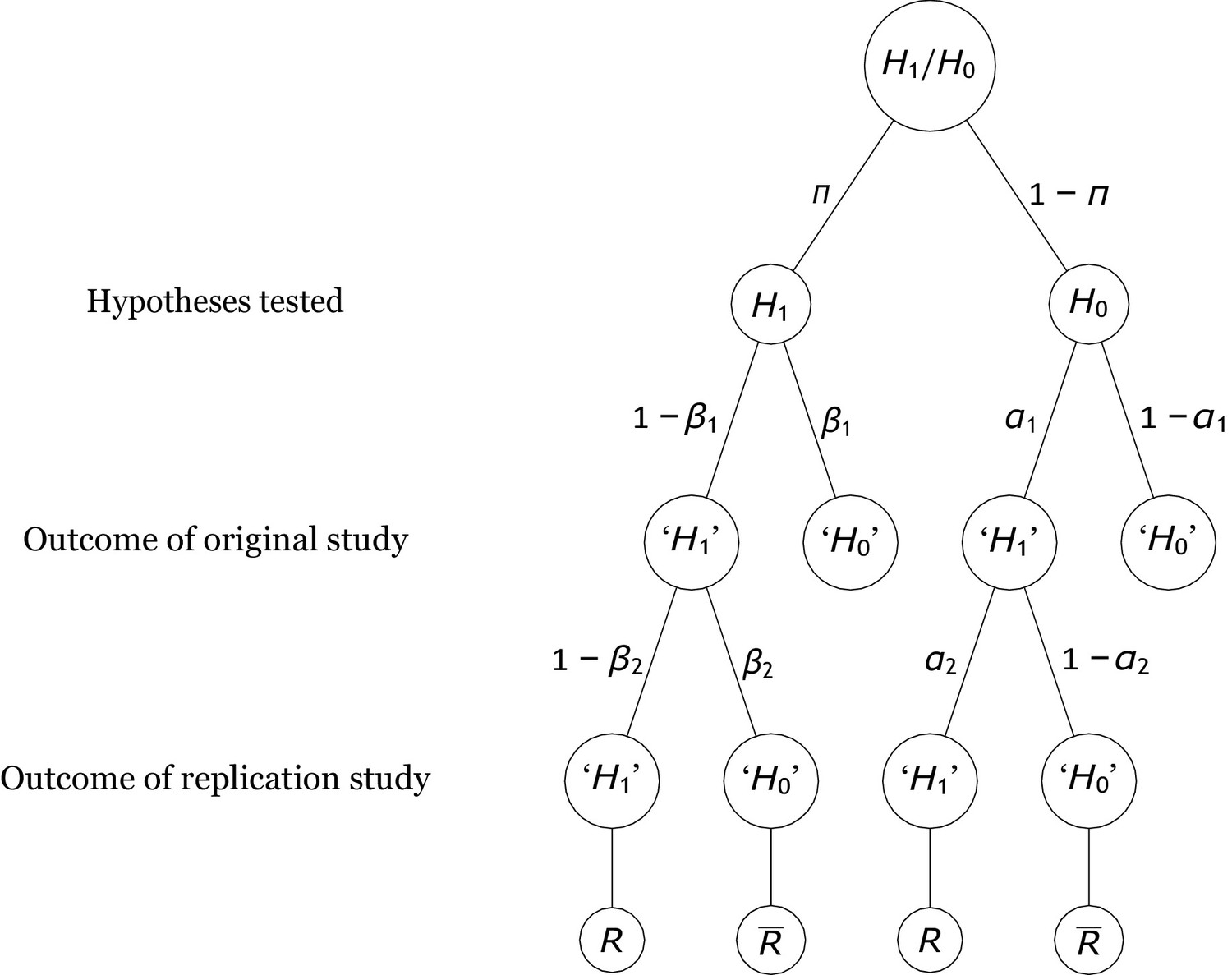
Probability tree of the replication scenario.
The base rates of examining an alternative hypothesis or a null hypothesis are and , respectively. The statistical power and the Type 1 error rate of the original study are and . There are four possible outcomes of an original study, with the researcher deciding to reject the null hypothesis (i.e., ‘’) in two outcomes and failing to reject it (i.e., ‘’) in the other two. If is true, the outcomes associated with these decisions are called true positives and false negatives. By contrast, if holds, they are called false positives and true negatives. Replication studies replicate original studies that reported a significant positive result. The statistical power and the Type 1 error probability of the replication study are and , respectively. The replication study may either reject (which denotes a successful replication of the original positive result, ) or fail to reject it (which denotes a failure to replicate the original result, ).
Only true positives and false positives enter into replication projects. The statistical power and Type 1 error probability of the replication studies might differ from those of the original study, especially because replication studies are usually designed to have much higher power than the original studies. Thus, the compound probability of examining a true effect that yields a significant effect in the original and in the replication study is , whereas the compound probability of examining a null effect and finding significance in both the initial study and the replication study is . From the above compound probabilities, the rate of replication of initially significant results, , can be computed as
(1)
Figure 2 illustrates this equation by showing how depends on , , and when the nominal alpha level and the statistical power of the replication studies are and . It can be seen in this figure that increases gradually with from a minimum of to a maximum of . For , the proportion of significant results can only represent false positives, so necessarily equals . For , in contrast, merely reflects the power of the replication study. As is also illustrated in this figure, grows faster when the power of the original studies is relatively large and their nominal alpha level is relatively small. Note that must gradually increase with from to even if the power in the original study were 100%. It is also instructive to note that worst-case p-hacking would imply and . In this case it follows from Equation 1 that approaches the line which runs from at to at .
Figure 2
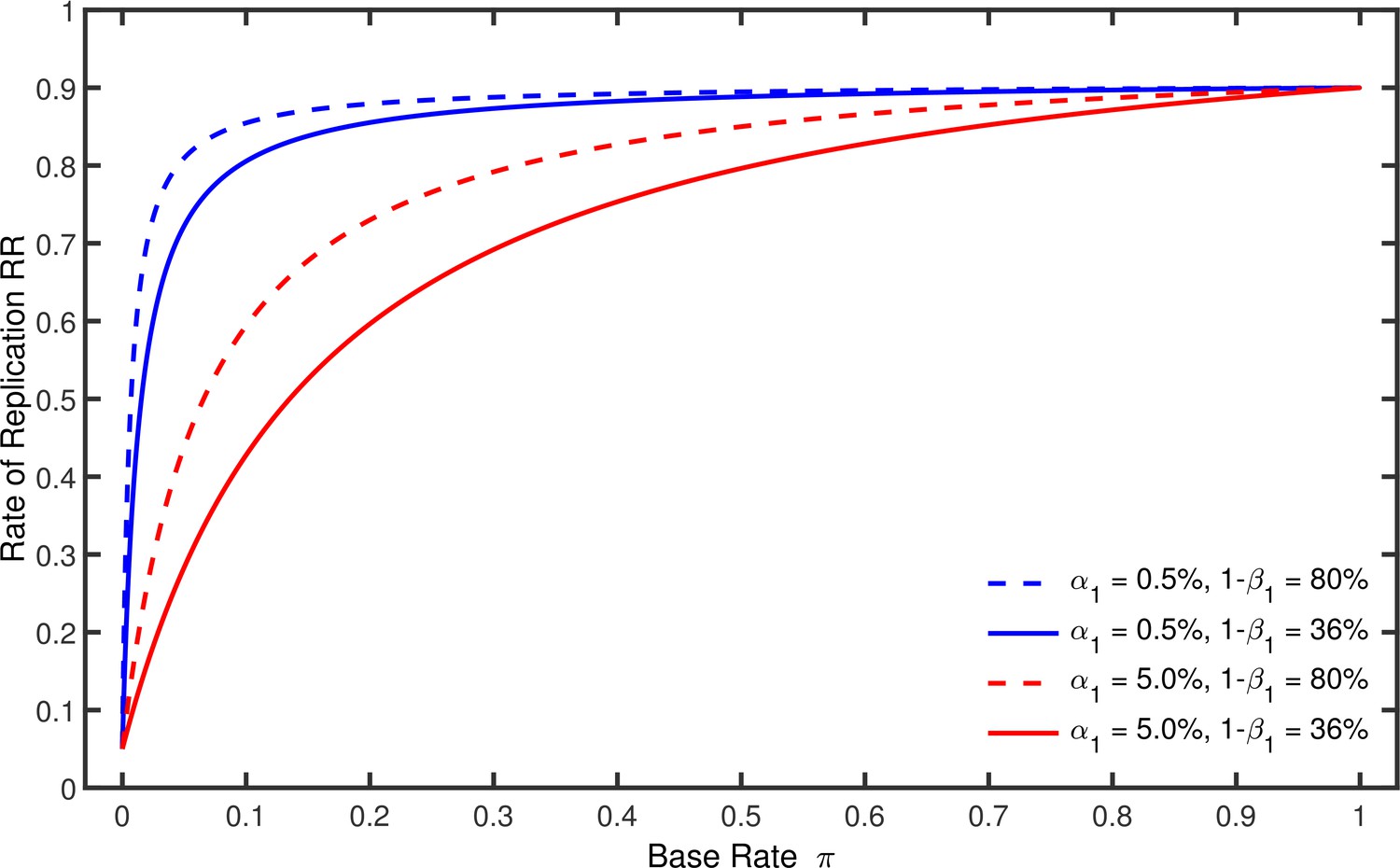
Rate of replication as a function of base rate .
Each line represents a different combination of the nominal alpha level and the statistical power used by the original studies. The nominal alpha level and the power of the replication studies were always % and %.
If p-hacking is performed in the original study, this would increase the Type 1 error rate above the nominal significance level (usually 5%) to, for example, 10% or even higher. Thus, when a researcher examines a null effect, p-hacking increases the proportion of false positives. The extent of this increase depends on the details of the p-hacking strategy that is used, as we examine in detail below for different strategies. However, and crucially for the analyses that will follow, when a true effect is present, p-hacking also increases the nominal power , for example, from 0.20 to 0.40 (i.e., power inflation, as mentioned above). With respect to the overall replication rate , this increase in power tends to compensate for the increased Type 1 error probability, making it difficult to determine intuitively how p-hacking would affect the replication rate . Fortunately, however, Equation 1 can be used to assess this issue quantitatively.
Besides assessing the effect of these factors on replicability, we will also report computations of the rate of false positives , which is the proportion of false positive results among all significant results within a research area (sometimes also called false discovery rate or false positive report probability)
(2)
In discussions about replicability—particularly replicability of published research findings—researchers often focus on this proportion (Button et al., 2013; Pashler and Harris, 2012) under the assumption that true positives are replicable but false positives are not. Therefore, it seems useful to include this rate in the analyses.
In the following, we model each of the four common p-hacking strategies that were described above. For each strategy, the inflated Type 1 error probability and the statistical power can be computed. These values are then inserted into Equation 1, which allows one to evaluate the effects of base rates and p-hacking on the replication rate, for both true and null effects. In addition, we examined the effects on of different levels of and statistical power, because—as mentioned above—several researchers have recently suggested lowering the level or increasing power in order to increase the replicability of scientific results (Benjamin et al., 2018; Button et al., 2013). This allows one to judge how these suggested measures would combat low replicability and to compare their effects with those of p-hacking and base rate.
Selective reporting of significant studies
It has been often suspected that researchers tend to selectively report studies that yield positive results, that is, results that are in accordance with the researcher’s hypothesis (e.g., John et al., 2012; Rosenthal, 1979; Simmons et al., 2011; Zwaan et al., 2018). As noted earlier, this tendency will increase the number of reported false positives if researchers publish only the significant outcomes. This section models this p-hacking strategy and examines how it would influence the replication rate.
As a specific example, suppose that a researcher runs a series of experiments, each of which uses a slight variation of the same basic paradigm. This researcher terminates the series when a significant result emerges in support of the researcher’s hypothesis, and in this case the researcher tries to publish that result. However, if no significant result is obtained after conducting experiments, the researcher abandons the project and concludes that the hypothesis is false. Thus, this researcher has studies providing opportunities to test the hypothesis, and it would be misleading about the overall level to publish only the significant outcome but not mention the non-significant attempts (Francis, 2014).
To model this scenario more concretely, assume that the researcher computes a z-value for the outcome of each experiment and considers the outcome to be statistically significant if any z-value exceeds a pre-specified criterion c (e.g., the critical z value of 1.96). In general, the probability of rejecting can be computed for with
(3)
because the outcomes of the experiments are statistically independent if a new sample is recruited each time.
Figure 3 and Figure 3—figure supplement 1 depict the probability of rejecting for two- and one-sample tests, respectively, as a function of , , and effect size . (Appendix 1 contains a detailed description of both tests.) In these examples, the group size is assumed to be (i.e., total for a two-sample test), a value that is typical for psychological research (Marszalek et al., 2011, Table 3), though there is evidence that sample sizes have increased recently in the field of social-personality psychology (Fraley and Vazire, 2014; Sassenberg and Ditrich, 2019). The lines for depict the effective Type 1 error probability. Of course, this probability is equal to for , but it increases with because of the greater number of opportunities for getting a significant result by chance when more studies are conducted. This increased Type 1 error probability is problematic because it tends to decrease replication rates (Benjamin et al., 2018). In the worst of these cases, the inflated Type 1 error rate attains a value of about 0.34 with and . As one expects, decreasing the nominal level from 5% to 0.5% substantially diminishes the Type 1 error probability and thus correspondingly diminishes the probability of obtaining a false positive (Benjamin et al., 2018). Even for the Type 1 error rate would only be about 0.04 with this smaller nominal level. It must be stressed, however, that a larger sample would be required for than for to achieve the same level of statistical power in both cases (Benjamin et al., 2018).
Figure 3 with 1 supplement see all
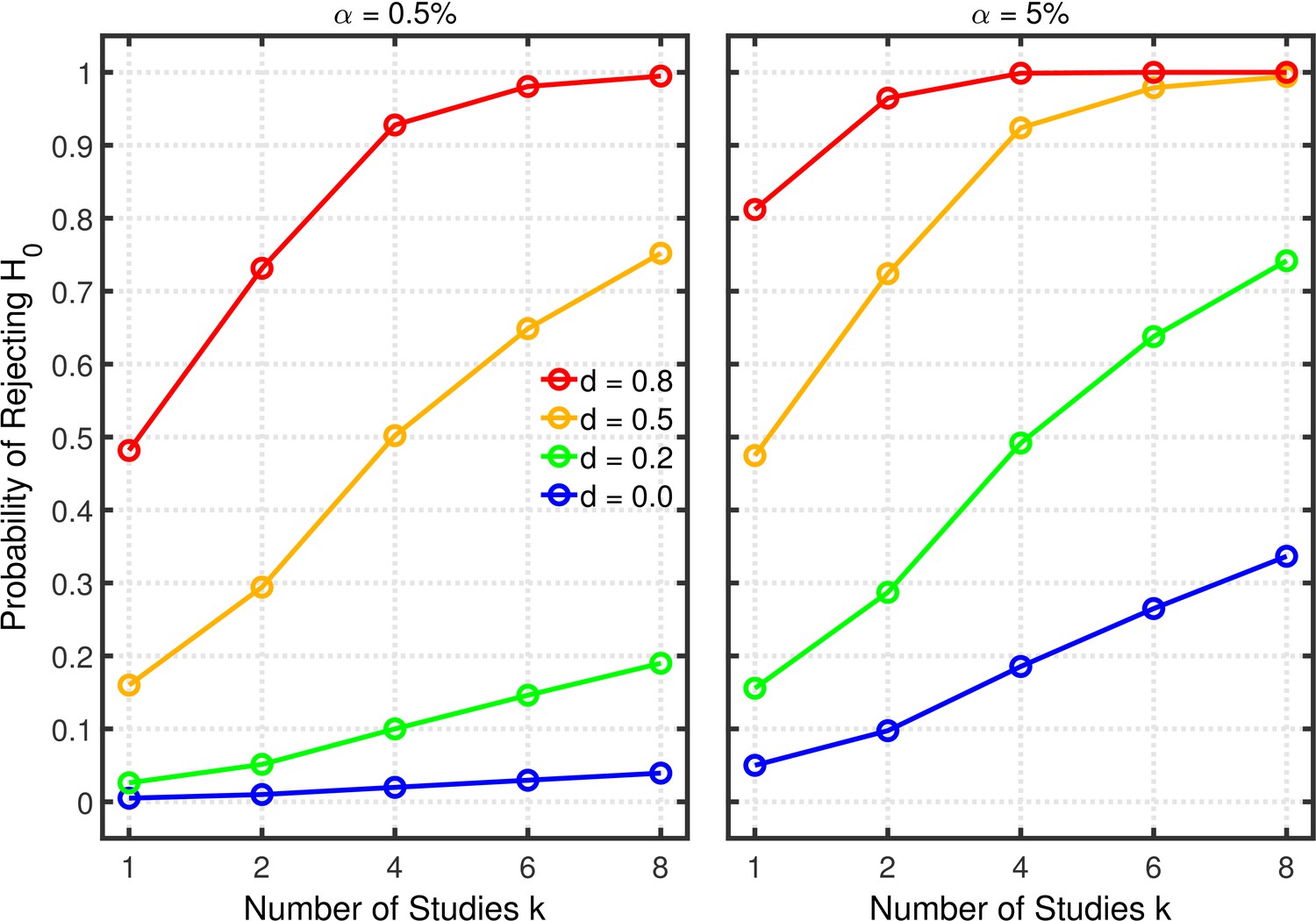
Selective reporting of significant studies.
Each panel depicts the probability of rejecting in at least one study as a function of the number of studies , nominal level, and effect size for a two-sample test with participants in each sample.
The lines for reveal the statistical power to reject when it is false. When researchers follow good scientific practice, the statistical power associated with each value of can be seen at . As is well known, power generally increases with , and it is larger with than with . For the present purposes, however, the most important aspect of the lines is the strong increase of statistical power with , which can be seen in both panels, especially when the single-experiment power is well below one. Since replication rates increase with power (Button et al., 2013; Button and Munafò, 2017), this power inflation will tend to compensate for the increased Type 1 error rate with respect to the overall influence of selective reporting on replication rate. It is therefore necessary to use a quantitative model to assess the net effect of this practice on the replication rate.
Using the above probabilities of rejecting , the proportion of false positives associated with this p-hacking scenario can be computed from Equation 2. Figure 4 and Figure 4—figure supplement 1 highlight the false positive rate as a function of , , and . Dashed lines show the rates for researchers engaged in p-hacking. For comparison, the solid lines depict the rates for researchers who follow good scientific practice by just running a single experiment and reaching a conclusion based on its outcome (i.e., ). The rates for these researchers were also computed with Equation 2 by inserting the nominal value of for and the single-experiment power for .
Figure 4 with 1 supplement see all
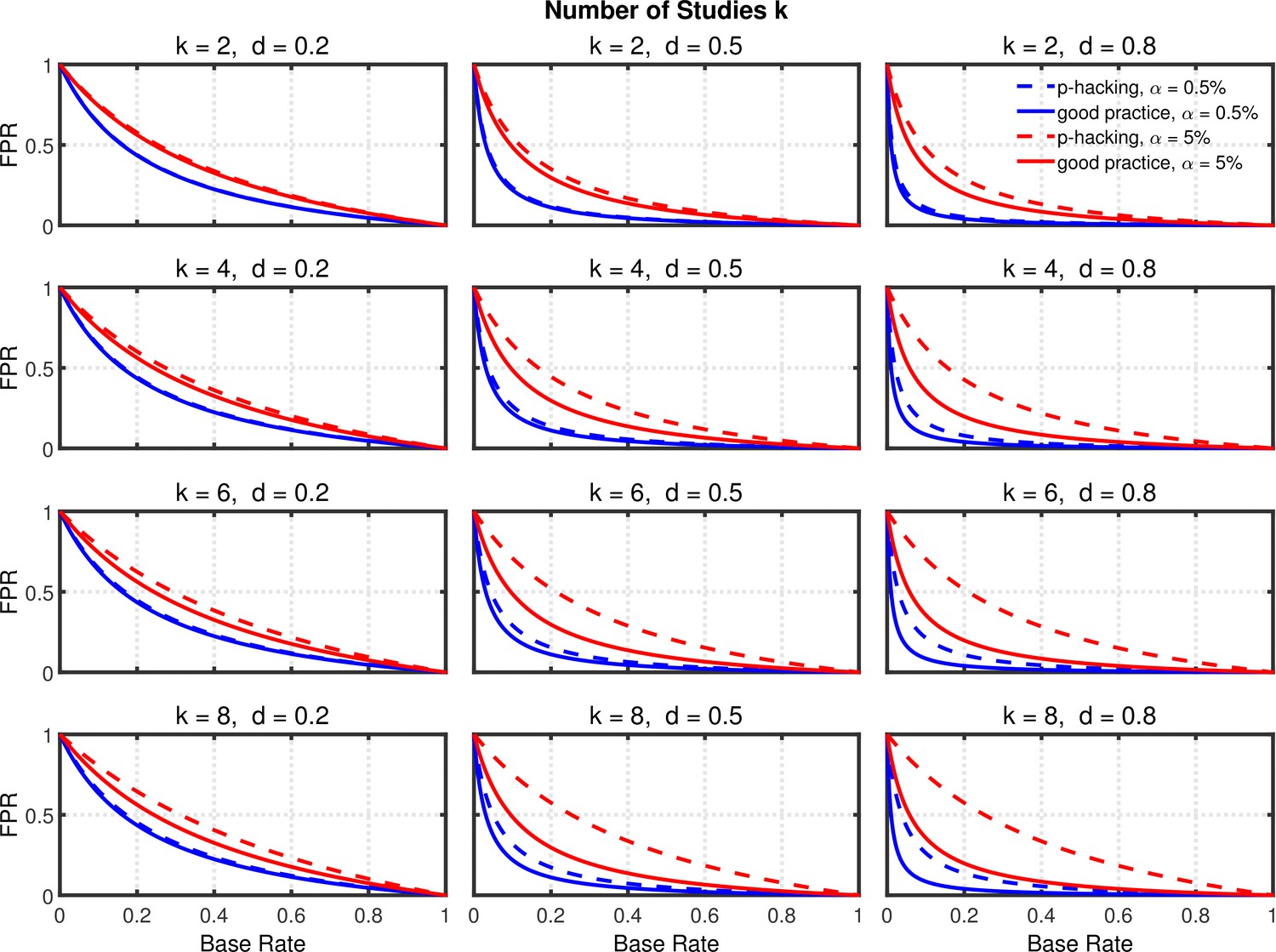
Selective reporting of significant studies.
False positive rate (FPR) as a function of base rate , number of studies , effect size , and nominal level (0.5% or 5%). The nominal level and power of the replication study are % and %. All results are based on per group. Dashed lines give the results for p-hacking whereas solid lines depict the results of researchers who act in accord with good scientific practice. Note that the solid lines are the same in all rows of a single column because these constant reference lines do not depend on .
Several effects can be observed in Figure 4 and Figure 4—figure supplement 1: (a) As one expects, the false positive rate decreases from one to zero with increasing , because the proportion of true effects among all significant effects becomes larger when increases (e.g., Ioannidis, 2005b; Wilson and Wixted, 2018). (b) Not surprisingly, the false positive rate becomes smaller when power increases due to larger (Ioannidis, 2005b). (c) Most interestingly and surprisingly, the increase in false positives produced by p-hacking is more pronounced with larger , where statistical power is higher. This is presumably because p-hacking cannot increase statistical power much when it is already high (i.e., when is large), so there is little power inflation to compensate for the increased Type 1 error rate. Nevertheless, the effect of p-hacking is far from dramatic for , although it can be quite prominent for larger values of , especially with small base rates.
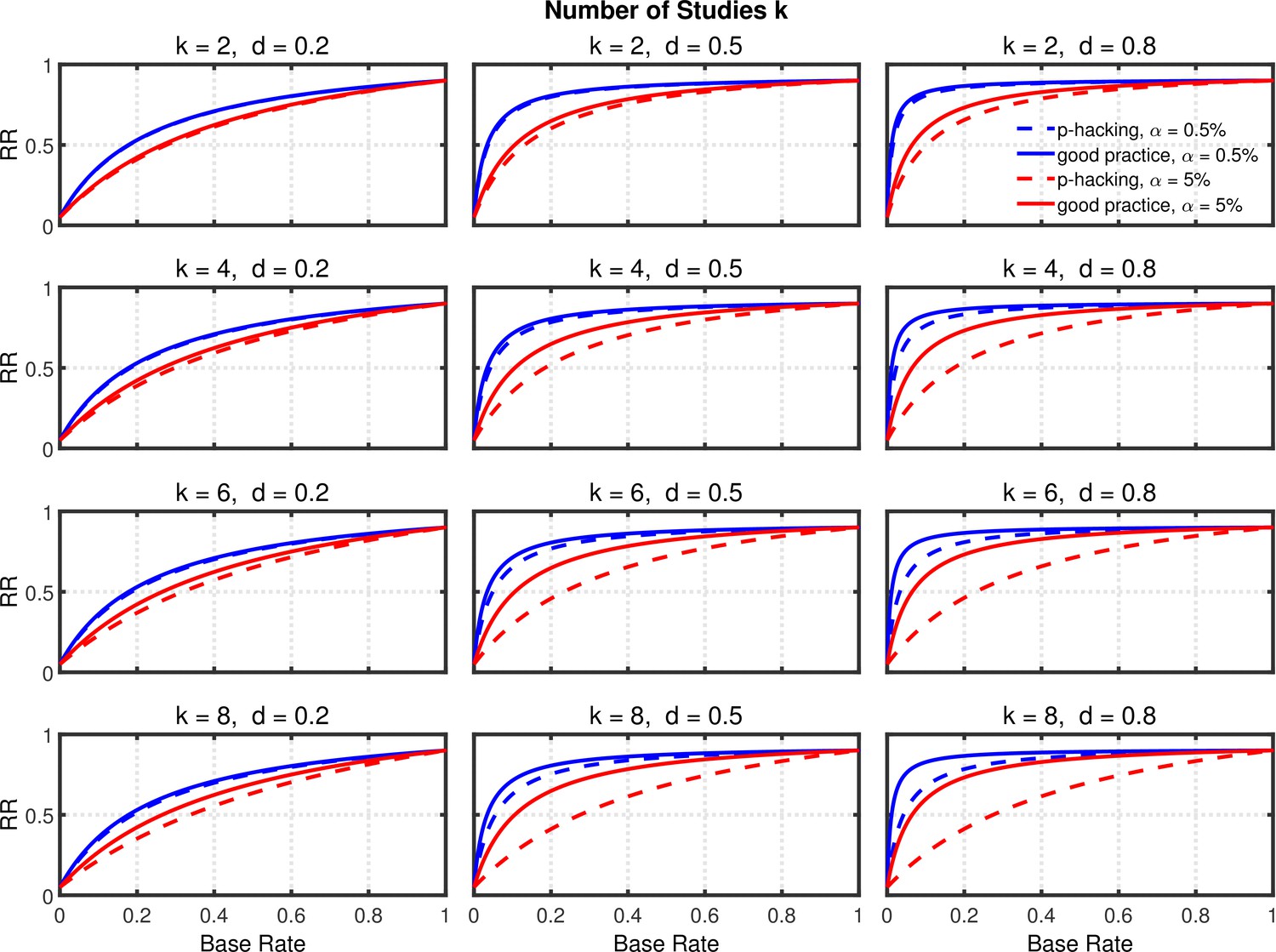
Figure 5 and Figure 5—figure supplement 2 depict replication rates computed using the same parameters as in the previous figures. In addition, Figure 5—figure supplement 1 and Figure 5—figure supplement 3 augment these figures and specifically focus on decrease in RR (i.e., “shrinkage”) caused by p-hacking. Three features of these computations are especially noticeable. (a) Successful replication depends strongly on the base rate. As one might expect, all rates converge to the statistical power of the replication study, because when all significant effects are real, the replication rate simply reflects the statistical power of the replication study, whether p-hacking was involved in the first study or not. (b) The effect of p-hacking is modest for high base rates, for the smaller level, and interestingly also for smaller effect sizes and hence for low statistical power. (c) As emphasized by Benjamin et al., 2018, the replication rate is considerably larger for than for , especially for small base rates.
Figure 5 with 3 supplements see all
Selective reporting of significant studies.
Replication rate (RR) as a function of base rate , number of studies , effect size , and nominal level (0.5% or 5%). The nominal level and power of the replication study are % and %. All results are based on per group. Dashed lines give the results for p-hacking whereas solid lines depict the results of researchers who act in accord with good scientific practice. Note that the solid lines are the same in all rows of a single column because these constant reference lines do not depend on k.
In summary, the above analysis casts doubt on the idea that this p-hacking strategy is a major contributor to low replicability, even though it seems to be one of the most frequent QRPs (e.g., John et al., 2012). Instead, it seems that using this strategy would have little effect on replicability except in research scenarios where true effects were rare but there was high power to detect them when they were present. The strongest trends suggest that a low base rate of true effects is the major cause of low replicability (Wilson and Wixted, 2018), since changes in base rate can cause replication rates to range across nearly the full 0–1 range.
Failing to report all dependent measures
Failing to report all of a study’s dependent measures seems to be another common QRP (Fiedler and Schwarz, 2016; John et al., 2012). In this section, we analyze how this practice would affect the rate of replicating statistically significant results. In order to model this scenario, we assume that a researcher conducts a study to test a certain hypothesis using control and experimental conditions. After data collection, however, the researcher only reports the outcomes of those dependent measures whose tests surpass the statistical significance threshold and thereby confirm the proposed hypothesis. As examples, multiple dependent measures are usually measured and statistically evaluated in neurosciences and medical research, raising concerns about Type 1 error rates in those fields (e.g., Hutton and Williamson, 2002; Vul et al., 2009).
We again employed z-tests to model this scenario. Let be the outcomes for all dependent measures of a single study, with each -value representing the result of the control/experimental comparison for a single measure. Therefore, the probability of obtaining at least one significant result is equal to
with c being the critical cutoff value (see Appendix 1 for computational details). Because such measures are usually correlated across participants, our model incorporates correlations among the values.
Figure 6 illustrates the effects on Type 1 error probability (i.e., lines with ) and statistical power (i.e., lines with ) associated with this type of p-hacking. For this illustration, the pair-wise correlations of the different dependent measures were set to 0.2 and the sample size (per group) was set to 20, which are seemingly typical values in psychological research (Bosco et al., 2015; Marszalek et al., 2011). As expected, both the Type 1 error rate and power increase with the number of dependent measures, approximately as was found with selective reporting.
Figure 6 with 1 supplement see all
Failing to report all dependent measures.
Each panel depicts the probability of rejecting as a function of the number of dependent measures , nominal level, and effect size for a two-sample test with participants per group and dependent measure intercorrelations of 0.2.
Figures 7 and 8, and Figure 8—figure supplement 1 show the rate of false positives, rate of replications, and the shrinkage of the replication rate, respectively, resulting from this type of p-hacking. These results are quite similar to those seen with the selective reporting scenario (see Figures 4 and 5, and Figure 5—figure supplement 1). In particular, both false positive rates and replication rates show strong expected effects of base rate and level, as well as a clear influence of effect size, d. The effects of p-hacking are again rather modest, however, especially when the effect size is small (i.e., ) so that increased power is especially helpful.
Figure 7 with 1 supplement see all
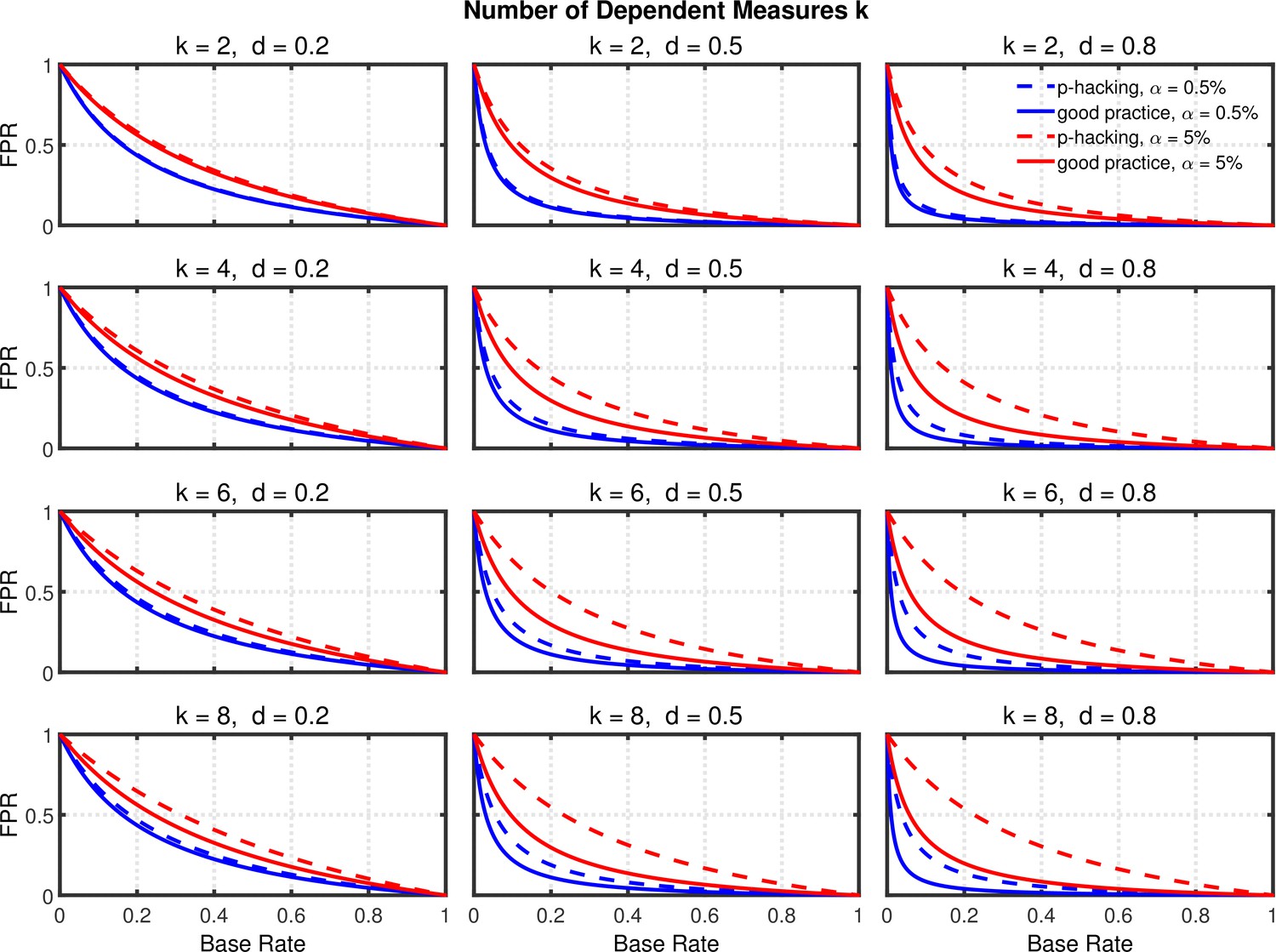
Failing to report all dependent measures.
False positive rate (FPR) as a function of base rate , number of dependent measures , effect size , and nominal level (0.5% or 5%). The nominal level and power of the replication study are % and %. All results are based on two-sample tests with per group and dependent measure intercorrelations of 0.2. Dashed lines give the results for p-hacking whereas solid lines depict the results of researchers who act in accord with good scientific practice. Note that the solid lines are the same in all rows of a single column because these constant reference lines do not depend on .
Figure 8 with 3 supplements see all
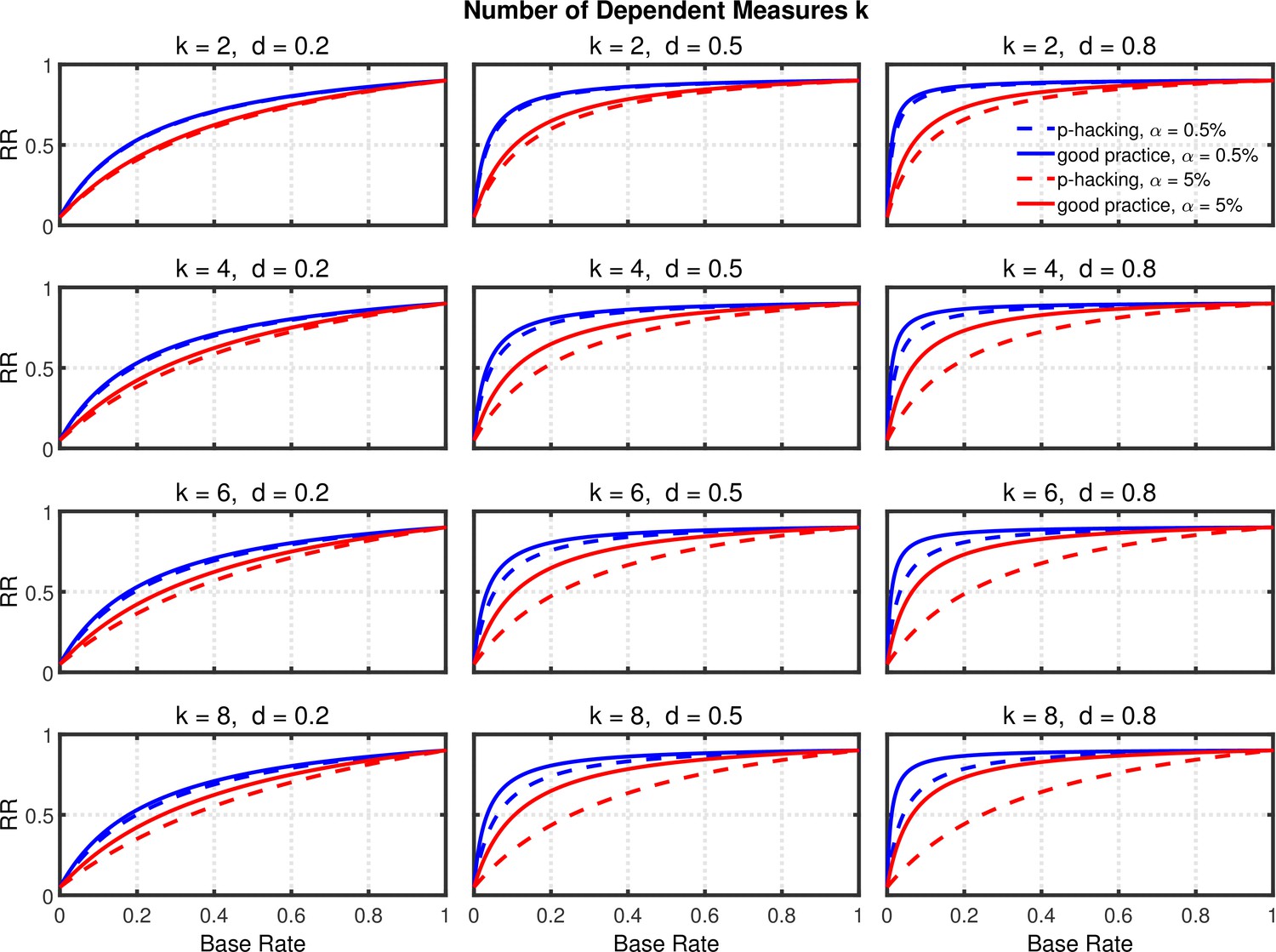
Failing to report all dependent measures.
Replication rate (RR) as a function of base rate , number of dependent measures , effect size , and nominal level (0.5% or 5%). The nominal level and power of the replication study are % and %. All results are based on two-sample tests with per group and dependent measure intercorrelations of 0.2. Dashed lines give the results for p-hacking whereas solid lines depict the results of researchers who act in accord with good scientific practice. Note that the solid lines are the same in all rows of a single column because these constant reference lines do not depend on .
It should be noted that the extent of both Type 1 error rate inflation and power enhancement depend on the correlations among the different dependent measures. A correlation of zero would yield results identical to those of the scenario with selective reporting in the previous section, because in this case the outcomes for multiple dependent measures are independent just like the outcomes of multiple independent studies. In contrast, larger correlations (e.g., larger than the 0.2 used in Figures 7 and 8 and Figure 8—figure supplement 1) weaken the effects of this p-hacking strategy, because the measures become increasingly redundant as the intercorrelations increase, and this lowers the possibility of capitalizing on chance. In other words, increasing the intercorrelations would decrease the inflation of both Type 1 error rate and power. Moreover, increased intercorrelations would decrease the false positive rate and increase the replication rate, that is, moving the dashed lines in Figures 7 and 8 toward the solid reference lines (see Figure 6—figure supplement 1, Figure 7—figure supplement 1, Figure 8—figure supplement 2, and Figure 8—figure supplement 3 for a parallel analysis with intercorrelations of 0.8).
Data peeking
Another frequently-used QRP is data peeking (Fiedler and Schwarz, 2016; John et al., 2012). This practice occurs when a researcher collects additional data after finding that the results of initially collected data have not yielded statistical significance. A researcher may even peek at the results several times and increase the sample with additional observations each time a nonsignificant result is obtained. Data collection is finally terminated only if the study yields no significant result after peeks. It is known that this practice increases the Type 1 error rate (Armitage et al., 1969; Francis, 2012a; McCarroll et al., 1992; Simmons et al., 2011; Strube, 2006). For example, Monte-Carlo simulations by Simmons et al., 2011 revealed that this strategy can increase the error rate up to 14.3% with a first peek at and four subsequent peeks (each time increasing the sample by 10 observations). However, this practice increases not only the Type 1 error rate but also the effective statistical power to reject a false (Strube, 2006), so a quantitative analysis is needed to determine its effect on replication rate.
An analysis similar to that of the preceding sections was conducted to examine how data peeking affects Type 1 error rates, power levels, false positive rates, and replication rates. Appendix 1 contains the computational details of this analysis, which follows an extension of Armitage's procedure (Armitage et al., 1969). In brief, the probability of rejecting with a maximum of peeks at successive sample sizes is again given by the multivariate normal distribution for z-tests
The correlations among the different values are determined by the amount of shared data used in computing them (e.g., all observations used in computing are also included in the computation of ).
Figure 9 depicts the probability of rejecting for various effect sizes and two-sample tests. The abscissa represents the maximal number of peeks at which a researcher would give up recruiting additional participants. For this example, it is assumed that data peeking occurs after 10, 15, 20, 25, 30, 35, 40, or 45 observations per group. Thus, a researcher with a maximum of peeks will check statistical significance the first time at and if the first peek does not reveal a significant result, the data will be examined a second and final time at . For , data will be examined a first time at and—depending on the outcome of the first peek—a second time at ; if the second peek also does not reveal a significant result, a final peek occurs at .
Figure 9 with 1 supplement see all
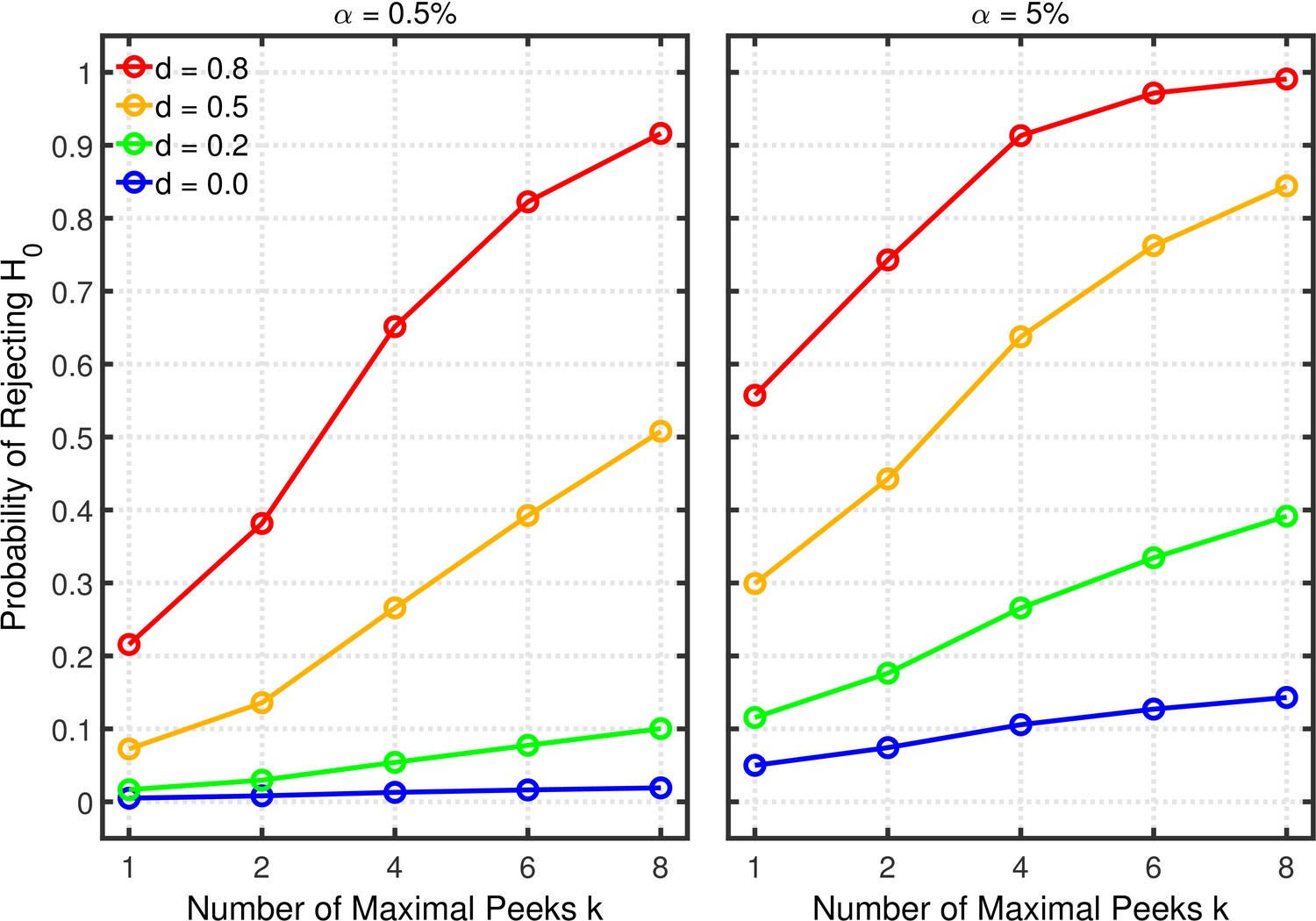
Data peeking.
Each panel depicts the probability of rejecting as a function of the number of maximal peeks , nominal level, and effect size for a two-sample test.
Figure 9 shows quantitatively how the probability of rejecting increases with the maximum number of peeks. In particular, the increase can be quite strong in situations with only moderate power (e.g., and ) due to the extra chances of detecting the true effect. In contrast to the multiple dependent measures with intercorrelations of 0.2 as discussed in the previous section, the Type 1 error rate inflation is smaller in the present case, because are more strongly correlated under this scenario (cf. the correlation matrix in Appendix 1).
Given the probabilities of rejecting , the replication rate and false positive rate are again computed using Equations 1 and 2, respectively. The results with respect to the false positive rate (Figure 9—figure supplement 1) and the replication rate (Figure 10 and Figure 10—figure supplement 1) are quite similar to those of the preceding scenarios. We compare this p-hacking strategy with researchers who conform to good scientific practice and thus examine the data only once at a preplanned n. In order to enable a conservative comparison with p-hackers, we used a preplanned n corresponding to the maximum number of observations a p-hacker would try when using the indicated number of peeks (i.e., this preplanned group size would be for the comparison with , for the comparison with , etc.). As can be seen, the pattern of results is quite comparable to the previous scenarios. Overall, the data peeking strategy again seems to have little effect on replication rate except in research scenarios where true effects are infrequent and there is high power to detect them when they do occur, just as with selective reporting.
Figure 10 with 1 supplement see all
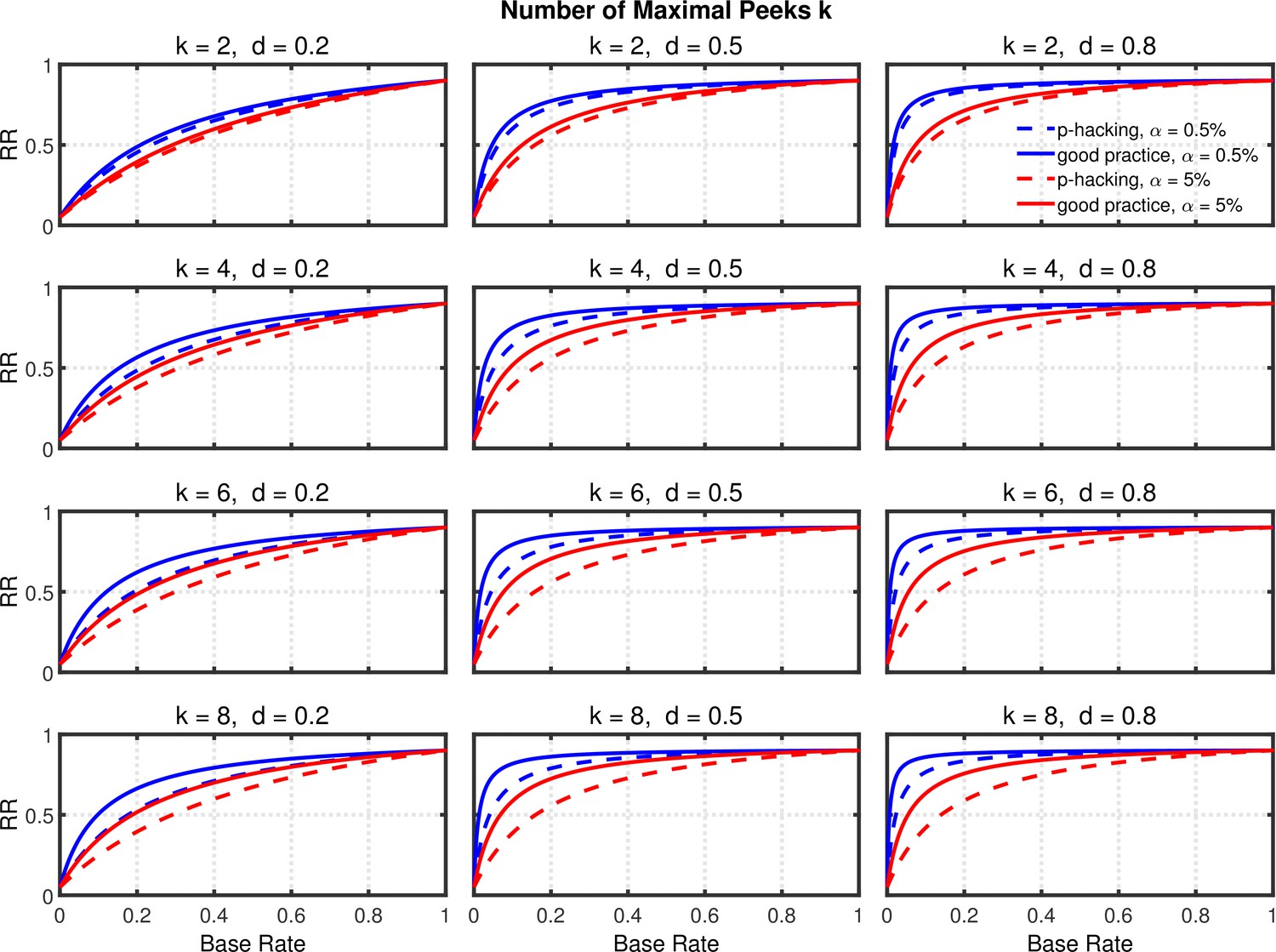
Data peeking.
Replication Rate (RR) as a function of base rate , number of maximal data peeks , and nominal level (0.5% or 5%). The nominal level and power of the replication study are and . Dashed lines give the results for p-hacking whereas solid lines depict the results of researchers who act in accord with good scientific practice. Note that the solid lines are the same in all rows of a single column because these constant reference lines do not depend on .
Selective outlier removal
Another QRP identified by John et al., 2012 is to analyze the same overall data set several times, each time excluding “outlier” data points identified by different criteria. The researcher may be tempted to conclude that a real effect has been found if any analysis yields a significant result, but this practice inflates the Type 1 error rate, because each of the analyses provides a further opportunity to obtain a significant result by chance. On the positive side, though, this practice again increases power, because each of the analyses also provides a further opportunity for detecting a real effect.
Because the effects of this type of p-hacking are not computable, we conducted Monte-Carlo simulations to see how multiple attempts at outlier removal would affect the Type 1 error rate, power, rate of false positives, and replication rate. Specifically, we examined the common practice of excluding scores more than a given number of standard deviations from the sample mean. We simulated researchers who carried out a sequence of at most five separate analyses on a single data set. The first three analyses included only scores within 3, 2.5, and 2 standard deviations of the mean, respectively, because these limits are most commonly employed in psychological research (Bakker and Wicherts, 2014). The fourth analysis used the Tukey, 1977 “fences” method by including all scores within the range , where and are the 25 and 75% percentile points of the data set. The fifth analysis used a nonparametric test, which could potentially be used as an analysis in an attempt to minimize the influence of outliers even further.
We simulated experiments for both one- and two-sample tests, but only report the latter because the two simulations produced extremely similar results. There was a sample size of per group using standard normally distributed scores and true effect sizes of , 0.2, 0.5, and 0.8. Researchers were modelled as using either or 5%, one-tailed. The nonparametric test was the Mann-Whitney test, and this test was used only if none of the previous analyses had produced significant results. We simulated 10,000 experiments with outliers by adding a random noise value to 5% of the data values, where these noise values came from a normal distribution with and . This simulation method has often been adopted to model contamination effects of outliers (e.g., Bakker and Wicherts, 2014; Zimmerman, 1998).
Figure 11 shows the probabilities of rejecting . As with the other p-hacking methods, this probability increases with the number of analyses conducted, increasing the probability of a Type 1 error when and increasing power when . Figures 12 and 13 show the false positive and replication rates; Figure 13—figure supplement 1 depicts the shrinkage of the replication rate. Interestingly, in some cases these measures even indicate slightly better results (i.e., lower false positive rates and higher replication rates) when researchers perform multiple analyses to remove the effects of possible outliers than when they do not. Most importantly, however, the present scenario also reveals that the major impact on the replication rate seems to come from the base rate.
Figure 11 with 1 supplement see all
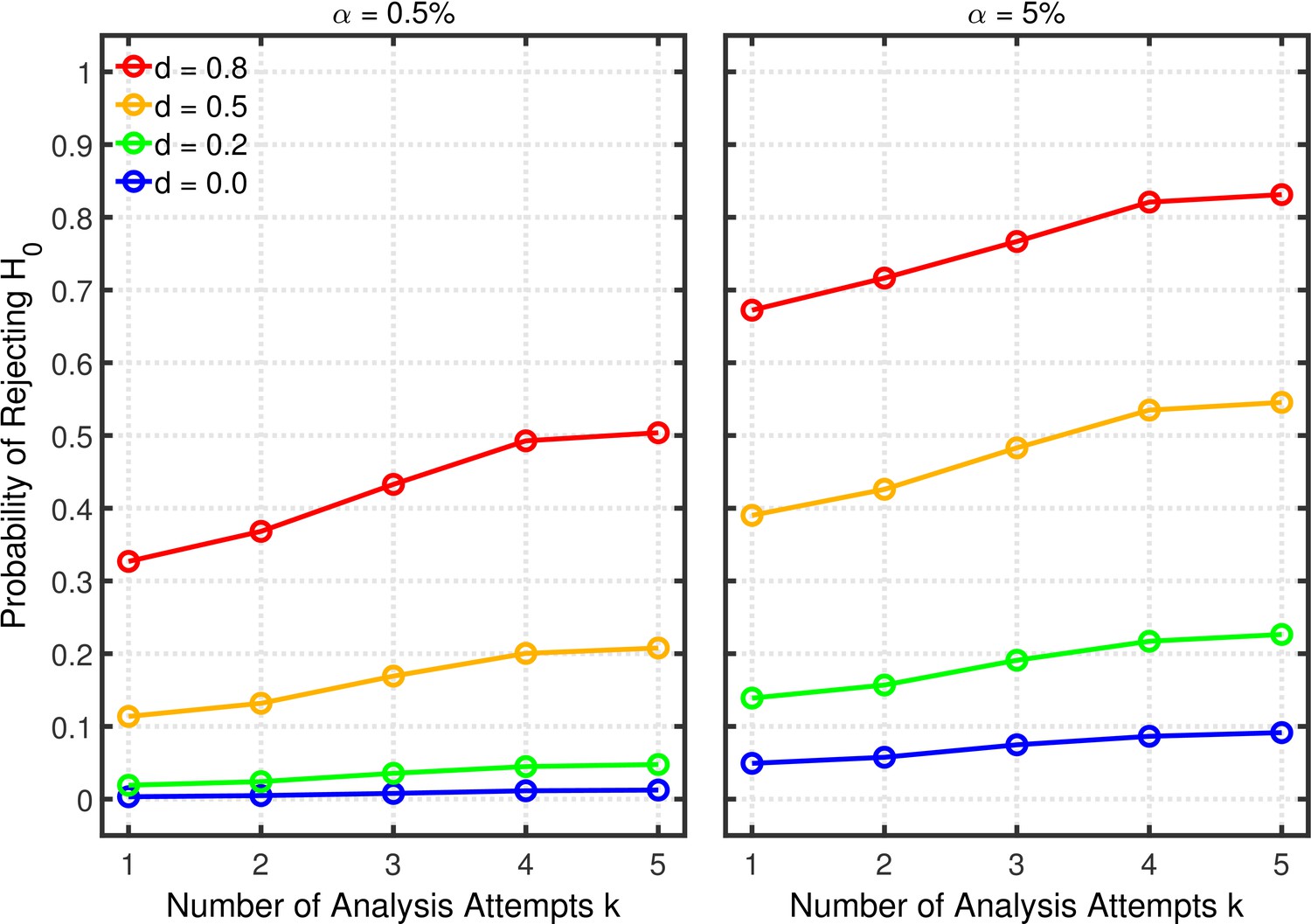
Selective outlier removal.
Estimated probability of rejecting as a function of the number of outlier rejection methods attempted for various effect sizes , and nominal level (0.5% or 5%). Probability estimates were based on 10,000 simulated experiments. Simulated data included 5% outliers.
Figure 12 with 1 supplement see all
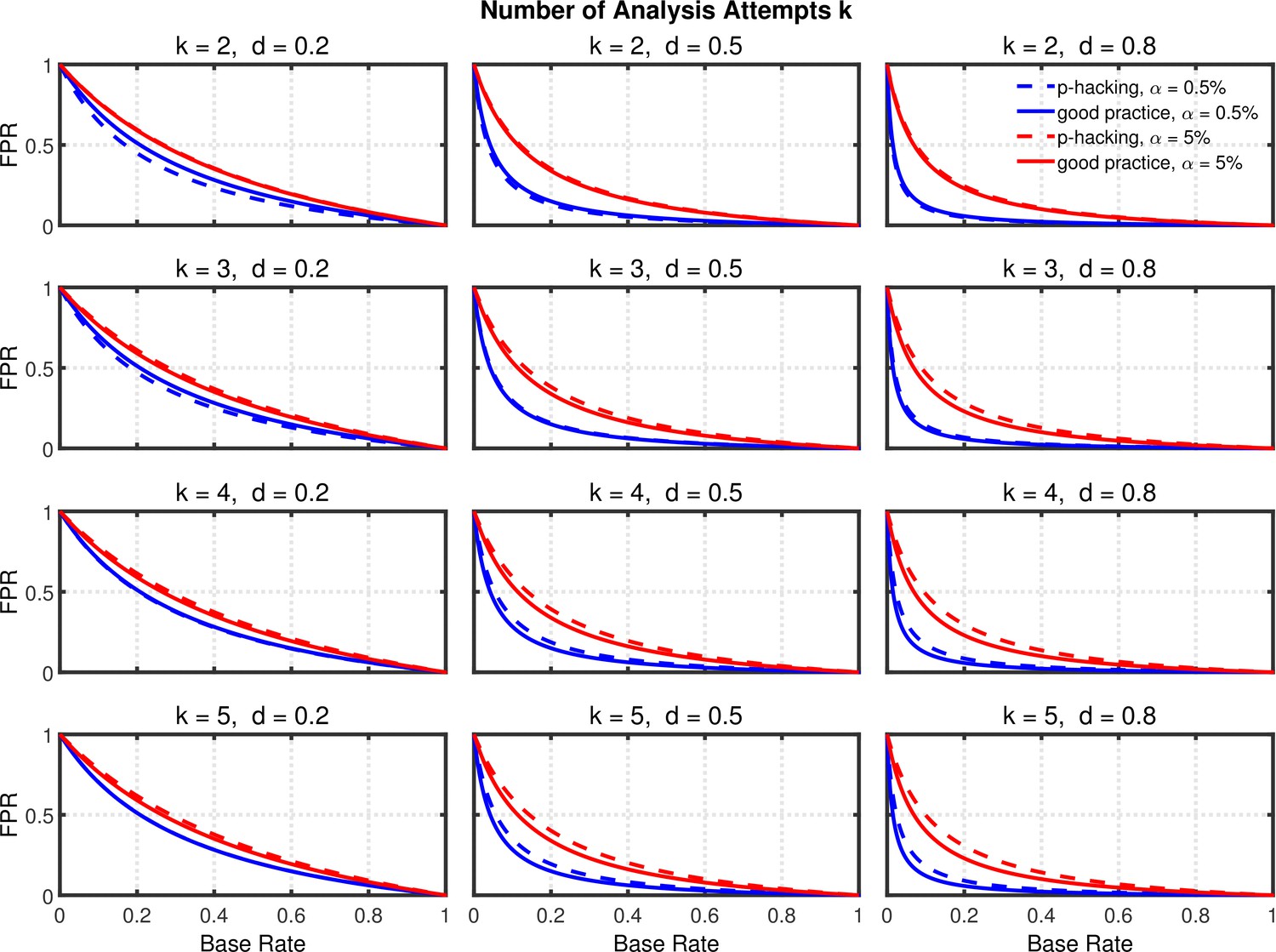
Selective outlier removal.
False positive rate (FPR) as a function of the number of outlier rejection methods attempted, effect size , and nominal level (0.5% or 5%). The nominal level and power of the replication study is and . Dashed lines gives the results for p-hacking whereas solid lines depict the results for researchers who act according to good scientific practice. Simulated data included 5% outliers.
Figure 13 with 3 supplements see all

Selective outlier removal.
Replication rate (RR) as a function of the number of outlier rejection methods attempted, effect size , and nominal level (0.5% or 5%). The nominal level and power of the replication study is and . Dashed lines gives the results for p-hacking whereas solid lines depict the results for researchers who act according to good scientific practice. Simulated data included 5% outliers.
The present simulations assume that researchers try to remove outliers (i.e., apply a three-sigma rule) before they perform a t-test. Alternatively, however, researchers might first conduct a t-test on all data without excluding any extreme data points. If this test did not reveal statistical significance, they would then eliminate extreme data points before conducting one or more further t-tests. Under this alternative scenario, our simulations indicate that multiple analyses can produce notably better replication rates than the single analysis with all data points, apparently because the exclusion of outliers noticeably improves power relative to the analysis without exclusions. Moreover, the standard deviation of our outlier distribution was small compared to simulations of similar outlier scenarios (e.g., Bakker and Wicherts, 2014; Zimmerman, 1998). Our conclusion, of course, is that researchers should carefully examine their data for possible outliers before conducting any statistical tests, not that they should perform multiple tests with different outlier screening criteria—thereby inflating their Type 1 error rates—in order to maximize power.
Naturally, the story is different when no outliers are present in the data set. Making multiple attempts to remove outliers in this case would actually always increase the false positive rate and lower the replication rate (see Figure 11—figure supplement 1, Figure 12—figure supplement 1, Figure 13—figure supplement 2, and , Figure 13—figure supplement 3 for a parallel simulation with no outliers). In fact, extreme data points in data sets without outliers appear to be especially diagnostic for testing the equality of locations between populations, as the Tukey pocket test demonstrates (Tukey, 1959), so throwing away extreme observations that are not outliers reduces the information in the data set.
General discussion
The ongoing reproducibility crisis concerns virtually all sciences and naturally prompts questions about how replication rates can be improved. Several measures have been advocated as ways to raise reproducibility, such as (a) preregistration of studies (Nosek et al., 2018), (b) increasing the transparency of research by making data and research materials publicly available (e.g., Nosek et al., 2015), (c) reducing (Benjamin et al., 2018), (d) increasing statistical power (Button and Munafò, 2017), (e) improving statistical training (Asendorpf et al., 2013), (f) adopting Bayesian approaches (Etz and Vandekerckhove, 2016), and even (g) overhauling standard scientific methodology (Barrett, 2020). The variety of these proposed measures demonstrates that replication failures can result from a multitude of causes that may come into play at various steps along the “entire analysis pipeline” (Leek and Peng, 2015).
The present article focused on the statistical consequences of QRPs with respect to replication rate. The impacts of the various statistical factors affecting replication rate (i.e., , power, , p-hacking) have typically been examined in isolation, which does not allow a complete assessment of their mutual influence and often leads to suggestions that are difficult to implement simultaneously, such as lowering and increasing power. In order to develop a better quantitative picture of the different influences on replicability, we modelled several apparently-frequent p-hacking strategies to examine their impacts on replication rate.
Our quantitative analyses suggest that p-hacking’s effects on replicability are unlikely to be massive. As noted previously, p-hacking inflates the effective Type 1 error rate (e.g., Simmons et al., 2011), which tends to reduce replicability, but our analyses indicate that the corresponding increase in power (i.e., power inflation) substantially compensates for this inflation. Compared to the strong effect of the base rate on replicability, the reduction in replication rate caused by p-hacking appears rather small. Unsurprisingly, the impact is larger when p-hacking is more extensive (i.e., rather than ). Moreover, p-hacking affects the replication rate most when the base rate is small. This makes sense, because p-hacking is harmful primarily when is true, which is more common with small base rates. The net influence of p-hacking on replicability appears to be smallest with small effect sizes, which is presumably the situation where p-hacking is most likely to be used. With small effects, the power increases associated with p-hacking are especially helpful for replicability. Finally and somewhat surprisingly, p-hacking tends to have a smaller effect on replicability when the nominal level is 0.5% rather than 5%.
Of course, these conclusions are restricted to the limited extent of p-hacking (i.e., ) that we examined, and more extensive p-hacking—or combining multiple p-hacking strategies—would presumably have larger effects on replicability. Nonetheless, we think that eight is a reasonable upper bound on the number of p-hacking attempts. The extent of p-hacking remains a controversial issue, with some arguing and providing evidence that ambitious p-hacking is too complicated and thus not plausible (Simonsohn et al., 2015). Unfortunately, the exact extent of p-hacking is difficult to determine and might strongly depend on the field of research. For example, in areas with small effect sizes, p-hacking might be more extensive than in fields with medium or large effect sizes. But even without knowing the true p-hacking rates, our analyses are valuable because they clearly show that evidence of massive p-hacking is needed before one can conclude that it is a major contributor to the replication crisis. In addition, when estimating the actual effect of p-hacking on observed replication rates (e.g., Open Science Collaboration, 2015), it is important to note that the effects shown in our figures are upper bounds that would only be approached if nearly all researchers employed these p-hacking methods. If only 10% of researchers use these methods, then the overall effects on empirical replication rates would be only 10% as large as those suggested by our model. Even the highest estimates of the prevalence of QRPs are only approximately 50% (John et al., 2012), and these may be serious overestimates (Fiedler and Schwarz, 2016).
Our quantitative analysis also assumed high-powered replication studies, that is, %. This replication power was chosen as the best-scenario value close to the average replication power claimed by the Open Science Collaboration, 2015. However, the power of the replication studies might not have been as high as they claimed. In particular, selective reporting of significant studies tends to overestimate true effect sizes, especially when these are small (Hedges, 1984; Lane and Dunlap, 1978; Ulrich et al., 2018), so the effect size estimates used in the power computations of the Open Science Collaboration, 2015 may have been too large. As a consequence, their actual power levels may have been lower than the estimated 90%. To check whether our conclusions would still be valid with lower replication power, we reran our computations using a replication power of 50%. These computations revealed that p-hacking would even be slightly less harmful to replication rates with 50% rather than 90% replication power.
Our analyses were based on groups size of (Marszalek et al., 2011). Recent meta-analyses, however, have indicated an increase in sample size especially in social-personality research (Fraley and Vazire, 2014; Sassenberg and Ditrich, 2019). Therefore, one may ask whether our main conclusions still apply for larger samples. First, as discussed in the introduction, the replication rate increases gradually with base rate whether the statistical power of the original study is low or even 100%. Therefore, even large sample studies cannot avoid low replication rates when the base rate is small. Second, because the statistical power increases with both sample size and effect size, increasing the effect size mimics what would happen if one increases the sample size. In fact, additional computations with larger samples (i.e., group size of 50) revealed no meaningful changes that would alter our conclusions.
Another limitation concerning our conclusions is that our list of p-hacking strategies was not exhaustive. For example, we did not examine the possibility that researchers might try several covariates until a significant result is obtained (e.g., Simonsohn et al., 2014b). As another example, suppose a researcher conducts a multi-factor analysis of variance (ANOVA) that invites the examination of multiple main effects and interactions, any one of which might be cherry picked as a “finding” in the absence of a specific a priori hypothesis. For instance, a three-factorial ANOVA allows the examination of seven potential effects (i.e., three main effects and four interactions). Assuming that all seven sources and their error terms are independent, the probability of at least one significant result when holds in all cases is —about 30% with —which would simply emulate the multiple studies scenario that we analysed in this article. Thus, analyses similar to the present ones would be needed to analyze the consequences of these other strategies, but it would be surprising if the results were drastically different.
We supplemented the analyses reported in this manuscript by two further analyses (see Appendix 2), each of which approached the replication issue from a different angle.One supplementary analysis assessed the effect of p-hacking on power while controlling for the overall Type 1 error rate. The outcome of this analysis demonstrated that some p-hacking strategies can actually produce higher statistical power than good practice at each level of Type 1 error. This superiority can be explained by the fact that p-hacking sometimes involves the collection of additional data (e.g., as with data peeking or measuring additional variables), and in these cases the additional data can cause statistical power to increase faster than the Type 1 error rate. The other supplementary analysis compared the overall research payoff associated with good practice versus data peeking using the payoff model of Miller and Ulrich, 2016. This analysis showed that the expected total payoff can actually be larger with data peeking than with good practice, evidently because data peeking tends to make more efficient use of limited sample sizes when true effects are common.
If p-hacking is not a major contributor to low replicability, then what is? In keeping with previous analyses (Dreber et al., 2015; Johnson et al., 2017; Miller, 2009; Miller and Ulrich, 2016; Wilson and Wixted, 2018), our results suggest that low base rates of true effects—not too-large levels, too-low power, or p-hacking—are most likely to be the major causes of poor replicability, so researchers concerned about replicability should pay special attention to the issue of base rates. Clearly, low base rates can lead to disappointingly low replication rates even in the absence of p-hacking (e.g., Figures 5, 8, 10 and 13, “good practice”). It follows from our analyses that research fields with inherently low base rates simply cannot improve their replication rates much by focusing exclusively on methodological issues. There are multiple lines of evidence that base rates are low in many fields (particularly those with low replication rates; e.g., Dreber et al., 2015; Johnson et al., 2017; Miller and Ulrich, 2016; Miller and Ulrich, 2019; Wilson and Wixted, 2018), and it will be especially challenging to increase replicability in those fields.
In principle, researchers can increase base rates by testing hypotheses that are deduced from plausible, evidence-based theories rather than by looking for effects that would be particularly surprising and newsworthy. However, practical constraints may often make it difficult to increase base rates, especially in research areas where a deeper theoretical understanding is lacking (e.g., in the search for an effective vaccine against an infectious disease). In such areas, a haphazard approach to hypothesis selection may be the only option, which naturally implies a low base rate. In combination with publication bias and p-hacking, this low base rate may make it particularly challenging to establish scientific claims as facts (Nissen et al., 2016).
Looking beyond replication rates, meta-scientists should consider exactly what measure of research productivity they want to optimize. For example, if the goal is to minimize false positives, they should use small levels and eliminate p-hacking. If the goal is to minimize false negatives, however, they should do exactly the opposite. The major problem in statistical decision making is that one cannot maximize all of the desirable goals at the same time. Thus, focusing on only one goal—even that of maximizing replicability—will not yield an optimal research strategy. Identifying the optimal strategy requires considering all of the goals simultaneously and integrating them into a composite measure of research productivity. One way to do this is to analyze the probabilities and payoffs for a set of possible research outcomes and to identify research parameters maximizing the expected research payoff (Miller and Ulrich, 2016). This analysis must also take into account how limited research resources would be used under different strategies. Other things being equal, for example, fewer resources would be needed for replication studies with than with , simply because initial studies would produce fewer significant outcomes as candidates for replication.
Conclusion
We modelled different causes (alpha level, power, base rate of true effects, QRPs) of low replication rates within a general statistical framework. Our analyses indicate that a low rate of true effects—not p-hacking—is mainly responsible for low replication rates—a point that is often under-appreciated in current debates about how to improve replicability. Of course, we do not wish to transmit the message that p-hacking is tolerable just because it might increase power when a researcher examines a true effect. As has often been discussed previously (Simmons et al., 2011), p-hacking should always be avoided because it inflates Type 1 error rates above stated levels and thus undermines scientific progress. Rather, our message is that scientists and others concerned about low replication rates should look beyond p-hacking for its primary causes. The current analyses suggest that even massive campaigns against p-hacking (e.g., researcher education, pre-registration initiatives) may produce only modest improvements in replicability. To make large changes in this important scientific measure, it will likely be necessary to address other aspects of the scientific culture. Unfortunately, that may not happen if attention and blame are focused too narrowly on p-hacking as a major cause of the current problems in this area.
Appendix 1
The analysis of p-hacking in the main article is based on one- and two-sample z-tests. Although researchers usually employ one- and two-sample t-tests rather than z-tests, we studied the latter tests because of their greater mathematical tractability. This should not have a big impact on the results, because z-tests closely resemble the results of the corresponding t-tests for realistic sample sizes.
One-sample z-Test
This test proceeds from a random sample of n observations from . Each observation is a single measure taken from each of the subjects. Let . Thus and . In order to test the null hypothesis , one uses the test statistic
which follows a standard normal distribution under the null hypothesis. For example, with a one-tailed test this hypothesis is rejected if exceeds the critical value that is associated with a pre-specified level. Moreover, the effect size of this test is
There is an alternative application of the one-sample test that is worth mentioning. In this case represents a difference score for the s-th subject, and the dependent measures and are most likely correlated across subjects. Consequently, the variance of is given by
If we let and be the correlation between and , the preceding expression simplifies to
Note that for a moderate correlation, i.e., , the standard deviation of becomes and thus the test statistic under of this alternative is
with effect size equal to . Therefore, this alternative view of the one-sample test is equivalent to the aforementioned single-variable view.
Two-sample z-Test
The two-sample z-test proceeds from two independent samples and . To simplify matters, equal sample sizes are assumed. Without loss of generality, the first sample is a random draw from and the second sample from . Let and ; consequently, and . Thus the associated z-value of the statistic for testing is
In addition, the effect size of this test is
Multiple dependent measures
This section explains how to compute the probability of rejecting when a researcher assesses dependent measures for statistical significance. Assume that each of these dependent measures is converted into a z-value, that is,
(1)
resulting in the random vector ; g is equal to σ for a one-sample test and equal to for a two-sample test. This vector has a multivariate distribution . The mean of each z-value is given by
(2)
and the variance of each z-value must be one; equals 1 and for one- and two-sample tests, respectively.
The covariance matrix for the one-sample z-test can be derived as follows. Let the correlation coefficient of and be equal to . Then the covariance of and is
Consequently, the off-diagonal elements in are equal to and those of the main diagonal are equal to 1.
For the two-sample test, the derivation of proceeds as follows
As a result, is identical to the covariance matrix of the one-sample test.
The rejection probability
(3)
can be evaluated using routine mvncdf of MATLAB 2019a or function pmvnorm of the R package mvtnorm (Genz, 1992; Genz and Bretz, 1999; Genz and Bretz, 2002).
Computing the probability of rejecting with multiple peeks
This section shows how to compute the probability of rejecting with a maximum of peeks for one- or two-sample z-tests. Our procedure extends the standard approach originally suggested by Armitage et al., 1969; (see also Proschan et al., 2006, p. 78), which can be used to compute the probability of rejecting for a one-sided test of a true null hypothesis. The extension also allows one to compute the probability of rejecting when the null hypothesis is false (a somewhat similar mathematical approach is provided in Proschan et al., 2006).
Assume that data are first checked for statistical significance (i.e., first “peek”) when observations have been collected for a one-sample design or in each group for a two-sample design. If no statistically significant result is observed, the per-group sample size will be increased to and again checked for statistical significance. This strategy is repeated until a significant result is obtained or terminated after peeks when there has been no significant result at any peek. Thus, the sequence denotes the different sample sizes at which the researcher tests the null hypothesis. In order to compute the probability of rejecting with multiple peeks, we let be the z-values associated with the various sample sizes . For a one-sided test the probability of rejecting with a maximum of peeks is given by
(4)
where is the cumulative distribution function of the random vector that follows a multivariate normal with and covariance matrix . In addition, the cutoff c corresponds to the % percentile of the standard normal.
Under , the expected means of are for . In contrast, under these means are
(5)
with for a one-sample test and for a two-sample test.
The covariance matrix is completely specified by the vector . It can be shown that the -th element for of this matrix is given by
(6)
In order to prove this equation, one makes use of the distributive property of covariances,
For example, with peeks at , one obtains
Again with and , one can evaluate Equation 4 using routine mvncdf of MATLAB 2019a or function pmvnorm of the R package mvtnorm (Genz, 1992; Genz and Bretz, 1999; Genz and Bretz, 2002).
Appendix 2
A comparison of research payoffs
Using the quantitative models of p-hacking developed in the main article, good practice and p-hacking can also be compared with respect to global measures of research effectiveness, in addition to the comparisons of Type 1 error rates, false positives, and replication rates. As an illustration, this section compares good practice versus the particular p-hacking strategy of data peeking based on the overall research payoff model of Miller and Ulrich, 2016.
The payoff model assumes that a researcher tests a fixed total number of participants across a large number of studies (e.g., ), with each study testing either a true or a false null hypothesis (i.e., or ). Each study produces one of four possible decision outcomes: a true positive (TP) in which is correctly rejected, a false positive (FP) in which is incorrectly rejected (i.e., Type 1 error), a true negative (TN) in which is correctly retained, or a false negative (FN) in which is incorrectly retained (i.e., Type 2 error). According to the model, each outcome is associated with a given scientific payoff for the research area as a whole (i.e., , , , , in arbitrary units). The expected net payoff for any given research strategy (e.g., data-peeking, good practice) is the weighted sum of the individual outcome payoffs, with weights corresponding to the expected number of studies within that strategy multiplied by the probabilities of the different outcomes [i.e., , , , ]. The numbers of studies and outcome probabilities for researchers using good practice can be computed using standard techniques (e.g., Miller and Ulrich, 2016), and they can be computed for data-peeking researchers using the outcome probabilities computed as described in the main article.
Appendix 2—figure 1 illustrates expected net payoffs for a simple scenario in which positive results are either helpful or harmful to the scientific field (i.e., , ), whereas negative results are basically uninformative (i.e., ), and several aspects are of interest. First, as was noted by Miller and Ulrich, 2016, the expected net payoff increases strongly with the base rate of true effects, simply because the higher base rate increases the likelihood of obtaining true positive results. With a low base rate of true effects, the expected payoff can even be negative if the base rate is so low that FPs are more common than TPs. Second, as was emphasized by Miller and Ulrich, 2019, payoffs can be larger for than for , especially when the base rate of true effects is not too small. This happens because the greater power provided by the larger level outweighs the associated increase in Type 1 errors. Third, payoffs depend little on sample size, again because of a trade-off: Although larger samples provide greater power, which tends to increase payoff, they also reduce the number of studies that can be conducted with the fixed total number of participants, which tends to reduce payoff.
Appendix 2—figure 1
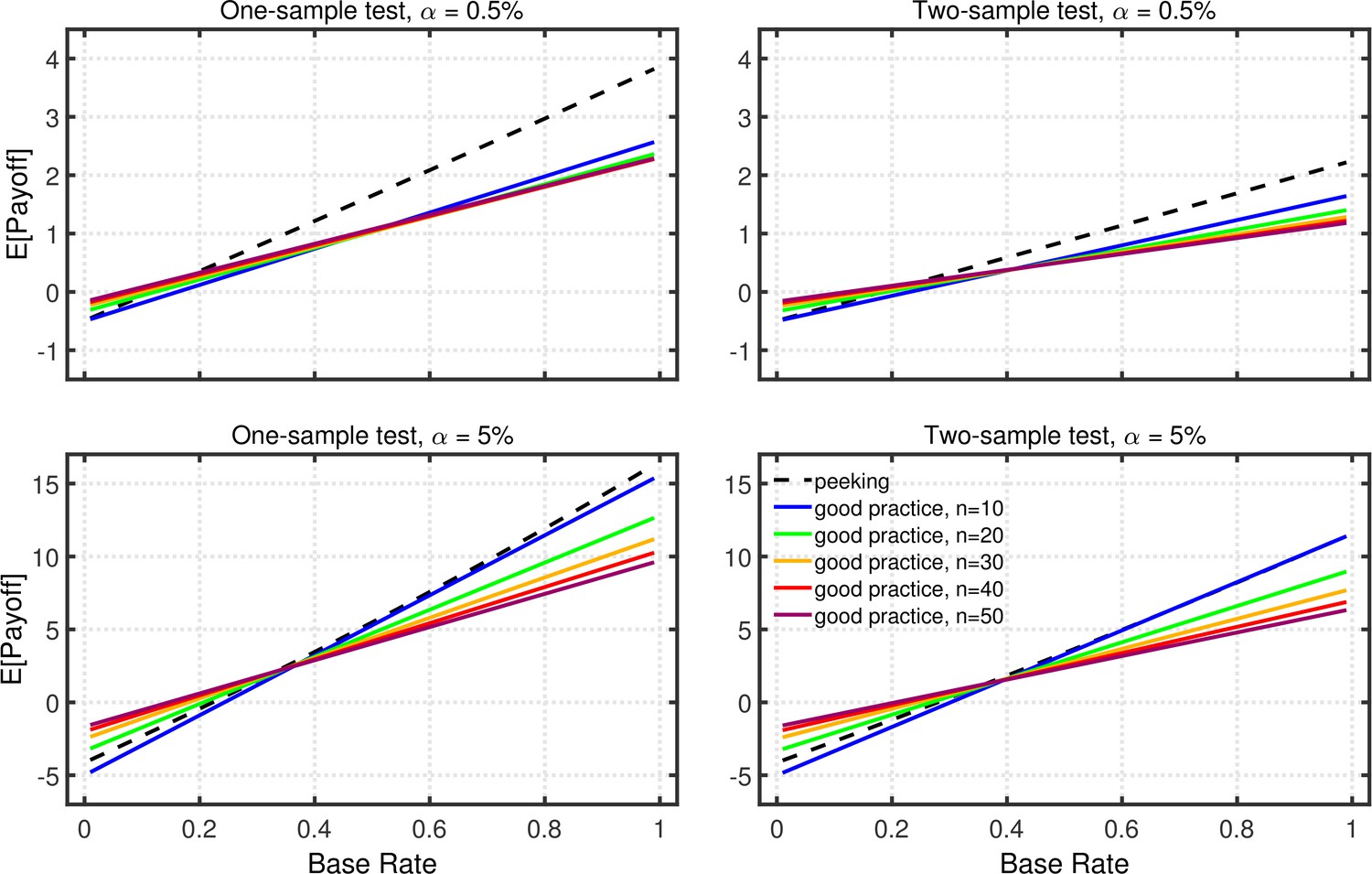
Expected payoff as a function of base rate and sample size.
The dashed lines give the expected payoffs for researchers using data peeking at sample sizes of 10, 15, 20, 25, and 30. The solid lines give the expected payoffs for researchers who act in accord with good scientific practice and only check the data once, at the indicated sample size. The panels on the left side reflect the results for one-sample tests, whereas those on the right for two-sample tests. The upper and lower panels give the results for a nominal one-tailed levels of 0.5 and 5%, respectively, with different vertical scales used because of the different ranges of payoffs for the two levels. All results are based on an effect size of , individual outcome payoffs of , , , and , and a total sample size of . The results are similar for two-tailed testing (not shown).
In the present context, however, the most interesting aspect of Appendix 2—figure 1 is that the expected payoff can be larger with p-hacking by data peeking than with good practice. As was noted earlier, data peeking inflates the Type 1 error rate but also increases power, and these two consequences of peeking have counteracting effects on total payoff due to the opposite weighting of TPs and FPs (i.e., , ). When the base rate of true effects is large enough, the positive effects of increased power outweigh the negative effects of increased Type 1 errors. Moreover, with relatively large base rates (e.g., ), this can be true even when the cost of an FP is much larger than the gain associated with a TP (e.g., , ). Thus, under certain circumstances, data peeking would arguably be more effective than using the good-practice approach of fixing sample size in advance (e.g., Frick, 1998).
Type 1 error rate versus power
Because there is an inherent trade-off between Type 1 error rate and power (i.e., larger Type 1 error rates tend to produce greater power), it is also useful to compare good practice and p-hacking procedures in a manner that takes both of these variables into account simultaneously. Similar comparisons are standard tools for determining the most powerful test (e.g., Mood et al., 1974), under the assumption that a better procedure yields higher power for a given Type 1 error rate.
Appendix 2—figure 2 shows examples of such comparisons, plotting power versus Type 1 error rate for good practice and for each of the p-hacking procedures. To trace out the each line in this figure, the nominal level of each procedure was varied between 0.001–0.2 in steps of 0.001. For good practice, the Type 1 error rate is simply the nominal level, and power is computed using standard methods for that , a given effect size , a given sample size, and a one- or two-sample design. The analogous Type 1 error rates and power values for each of the p-hacking procedures can be computed using the models described in the main article. For the p-hacking methods, the Type 1 error rates are greater than the nominal 0.001–0.2 levels (i.e., Type 1 error rate inflation), and the curves for the different p-hacking methods are therefore stretched and shifted to the right. For example, with a nominal —the maximum used in these calculations—the actual Type 1 error rate for multiple studies p-hacking is nearly 0.7.
Perhaps surprisingly, Appendix 2—figure 2 shows that several of the p-hacking procedures have greater power than good practice at each actual Type 1 error rate. As an example, consider multiple studies p-hacking with as shown in the figure. Taking inflation into account, a nominal level of 0.01 produces a Type 1 error rate of approximately 0.05. For and one-sample testing, this nominal level yields power of 0.33. In contrast, using good practice with a nominal level of 0.05, which of course produces the same Type 1 error rate of 0.05, the power level is only 0.23. Thus, a multiple studies researcher using the stricter nominal level of 0.01 would have the same rate of Type 1 errors as the good practice researcher and yet have higher power. As a consequence of its higher power and equal Type 1 error rate, multiple studies would also produce a higher replication rate than good practice for any fixed base rate of true effects. Thus, under certain circumstances, the p-hacking procedures would arguably be more effective than the good-practice approach.
Appendix 2—figure 2
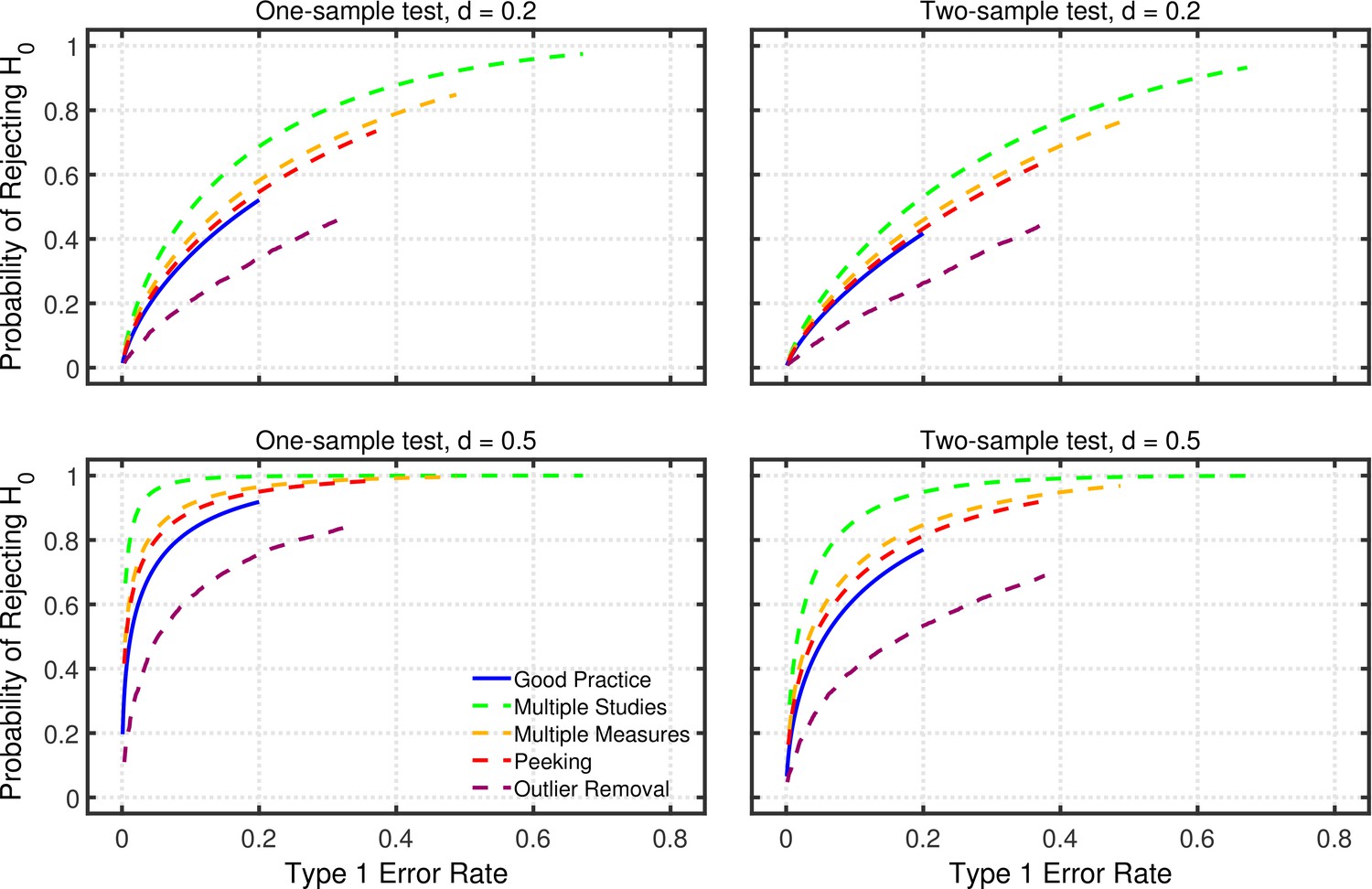
Power as a function of Type 1 error rate.
Power for one-tailed testing as a function of Type 1 error rate for researchers using good practice or one of the four p-hacking procedures considered in the main article: multiple studies (), multiple DVs ( with intercorrelations of 0.2), data peeking after , 15, 20, 25, and 30, or multiple analyses (). Computations were based on a sample size of (per group) for all procedures other than data-peeking.
In retrospect, it seems obvious that some types of p-hacking would produce higher power than good practice, because they involve collecting more data. In these examples good practice involved testing 20 participants in the example one-sample design, whereas multiple studies p-hacking allowed testing up to 100 participants. Data peeking also involved testing more participants—up to a maximum of 30—when that was necessary to obtain significant results. Collecting multiple DVs also provides more data because there are more scores per participant. Only multiple analysis p-hacking involves collecting the same amount of data as good practice, and this type of p-hacking yields less power than good practice at a given Type 1 error rate.
Data availability
There are no empirical data because mathematical modelling was employed to assess the impact of various factors on the replication of significant results.
References
-
Repeated significance tests on accumulating dataJournal of the Royal Statistical Society. Series A 132:235–244.https://doi.org/10.2307/2343787
-
Recommendations for increasing replicability in psychologyEuropean Journal of Personality 27:108–119.https://doi.org/10.1002/per.1919
-
The rules of the game called psychological sciencePerspectives on Psychological Science 7:543–554.https://doi.org/10.1177/1745691612459060
-
Redefine statistical significanceNature Human Behaviour 2:6–10.https://doi.org/10.1038/s41562-017-0189-z
-
Correlational effect size benchmarksJournal of Applied Psychology 100:431–449.https://doi.org/10.1037/a0038047
-
Power failure: why small sample size undermines the reliability of neuroscienceNature Reviews Neuroscience 14:365–376.https://doi.org/10.1038/nrn3475
-
BookPowering Reproducible ResearchIn: Lilienfeld S. O, Waldman I. D, editors. Psychological Science Under Scrutiny: Recent Challenges and Proposed Solutions. Wiley Online Library. pp. 22–23.https://doi.org/10.1002/9781119095910.ch2
-
The long way from α-error control to validity proper: problems with a short-sighted false-positive debatePerspectives on Psychological Science 7:661–669.https://doi.org/10.1177/1745691612462587
-
Questionable research practices revisitedSocial Psychological and Personality Science 7:45–52.https://doi.org/10.1177/1948550615612150
-
Publication bias and the failure of replication in experimental psychologyPsychonomic Bulletin & Review 19:975–991.https://doi.org/10.3758/s13423-012-0322-y
-
Too good to be true: Publication bias in two prominent studies from experimental psychologyPsychonomic Bulletin & Review 19:151–156.https://doi.org/10.3758/s13423-012-0227-9
-
The frequency of excess success for articles in Psychological SciencePsychonomic Bulletin & Review 21:1180–1187.https://doi.org/10.3758/s13423-014-0601-x
-
A better stopping rule for conventional statistical testsBehavior Research Methods, Instruments, & Computers 30:690–697.https://doi.org/10.3758/BF03209488
-
Numerical computation of multivariate normal probabilitiesJournal of Computational and Graphical Statistics 1:141–149.https://doi.org/10.1007/978-3-319-33507-0_13
-
Numerical computation of multivariate t -probabilities with application to power calculation of multiple contrastsJournal of Statistical Computation and Simulation 63:103–117.https://doi.org/10.1080/00949659908811962
-
Comparison of methods for the computation of multivariate t probabilitiesJournal of Computational and Graphical Statistics 11:950–971.https://doi.org/10.1198/106186002394
-
Scientific misconductAnnual Review of Psychology 67:693–711.https://doi.org/10.1146/annurev-psych-122414-033437
-
Bias in meta-analysis due to outcome variable selection within studiesJournal of the Royal Statistical Society: Series C 49:359–370.https://doi.org/10.1111/1467-9876.00197
-
An exploratory test for an excess of significant findingsClinical Trials: Journal of the Society for Clinical Trials 4:245–253.https://doi.org/10.1177/1740774507079441
-
On the reproducibility of psychological scienceJournal of the American Statistical Association 112:1–10.https://doi.org/10.1080/01621459.2016.1240079
-
Estimating effect size: bias resulting from the significance criterion in editorial decisionsBritish Journal of Mathematical and Statistical Psychology 31:107–112.https://doi.org/10.1111/j.2044-8317.1978.tb00578.x
-
Low replicability can support robust and efficient scienceNature Communications 11:1–12.https://doi.org/10.1038/s41467-019-14203-0
-
Psychology's replication crisis and the grant culture: Righting the shipPerspectives on Psychological Science 12:660–664.https://doi.org/10.1177/1745691616687745
-
Sample size in psychological research over the past 30 yearsPerceptual and Motor Skills 112:331–348.https://doi.org/10.2466/03.11.PMS.112.2.331-348
-
Sequential ANOVAs and type I error ratesEducational and Psychological Measurement 52:387–393.https://doi.org/10.1177/0013164492052002014
-
What is the probability of replicating a statistically significant effect?Psychonomic Bulletin & Review 16:617–640.https://doi.org/10.3758/PBR.16.4.617
-
Optimizing research payoffPerspectives on Psychological Science 11:664–691.https://doi.org/10.1177/1745691616649170
-
Addressing the theory crisis in psychologyPsychonomic Bulletin & Review 26:1596–1618.https://doi.org/10.3758/s13423-019-01645-2
-
Is the replicability crisis overblown? Three arguments examinedPerspectives on Psychological Science 7:531–536.https://doi.org/10.1177/1745691612463401
-
Believe it or not: how much can we rely on published data on potential drug targets?Nature Reviews Drug Discovery 10:712–713.https://doi.org/10.1038/nrd3439-c1
-
The file drawer problem and tolerance for null resultsPsychological Bulletin 86:638–641.https://doi.org/10.1037/0033-2909.86.3.638
-
Research in social psychology changed between 2011 and 2016: larger sample sizes, more self-report measures, and more online studiesAdvances in Methods and Practices in Psychological Science 2:107–114.https://doi.org/10.1177/2515245919838781
-
The crisis of confidence in research findings in psychology: Is lack of replication the real problem? Or is it something else?Archives of Scientific Psychology 4:32–37.https://doi.org/10.1037/arc0000029
-
Posterior-hacking: Selective reporting invalidates Bayesian results alsoSSRN Electronic Journal 1:2374040.https://doi.org/10.2139/ssrn.2374040
-
p-Curve: A key to the file-drawerJournal of Experimental Psychology: General 143:534–547.https://doi.org/10.1037/a0033242
-
p-Curve and effect size: Correcting for publication bias using only significant resultsPerspectives on Psychological Science 9:666–681.https://doi.org/10.1177/1745691614553988
-
Better p-curves: making p-curve analysis more robust to errors, fraud, and ambitious p-hacking, a reply to Ulrich and Miller (2015)Journal of Experimental Psychology: General 144:1146–1152.https://doi.org/10.1037/xge0000104
-
What meta-analyses reveal about the replicability of psychological researchPsychological Bulletin 144:1325–1346.https://doi.org/10.1037/bul0000169
-
Scientific misconduct and the myth of self-correction in sciencePerspectives on Psychological Science 7:670–688.https://doi.org/10.1177/1745691612460687
-
SNOOP: A program for demonstrating the consequences of premature and repeated null hypothesis testingBehavior Research Methods 38:24–27.https://doi.org/10.3758/BF03192746
-
A quick, compact, two-sample test to Duckworth’s specificationsTechnometrics : A Journal of Statistics for the Physical, Chemical, and Engineering Sciences 1:31–48.https://doi.org/10.2307/1266308
-
Effect size estimation from t-statistics in the presence of publication biasZeitschrift für Psychologie 226:56–80.https://doi.org/10.1027/2151-2604/a000319
-
Effects of truncation on reaction time analysisJournal of Experimental Psychology: General 123:34–80.https://doi.org/10.1037/0096-3445.123.1.34
-
Puzzlingly high correlations in fMRI studies of emotion, personality, and social cognitionPerspectives on Psychological Science 4:274–290.https://doi.org/10.1111/j.1745-6924.2009.01125.x
-
The prior odds of testing a true effect in cognitive and social psychologyAdvances in Methods and Practices in Psychological Science 1:186–197.https://doi.org/10.1177/2515245918767122
-
Invalidation of parametric and nonparametric statistical tests by concurrent violation of two assumptionsThe Journal of Experimental Education 67:55–68.https://doi.org/10.1080/00220979809598344
-
Making replication mainstreamBehavioral and Brain Sciences 41:01–61.https://doi.org/10.1017/S0140525X17001972
Decision letter
-
Peter RodgersSenior and Reviewing Editor; eLife, United Kingdom
-
William Hedley ThompsonReviewer; Stanford University, United States
-
Gregory FrancisReviewer; Purdue University, United States
In the interests of transparency, eLife publishes the most substantive revision requests and the accompanying author responses.
Thank you for submitting your article "Meta Research: Replication of Significant Results - Modeling the Effects of p-Hacking" to eLife. Your article has been reviewed by three peer reviewers, and the evaluation has been overseen by the eLife Features Editor (Peter Rodgers). The following individuals involved in review of your submission have agreed to reveal their identity: William Hedley Thompson (Reviewer #2); Gregory Francis (Reviewer #3).
Summary:
The authors present an argument and simulations illustrating the impact of the replication rate of four different questionable research practices. I found the argument both interesting and convincing. The article also raises important points about interpreting replicability that are very much misunderstood by many practicing scientists. However, improvements could be made to clarify certain assumptions and aspects of the argument.
Essential revisions:
1) Equation (1) succinctly related replication rate (RR) to power and alpha. In some sense, almost everything follows from this equation. The details about how different QRPs affect alpha and beta are secondary (but useful) analyses. A further discussion of equation (1) might be worthwhile regardless of how alpha and beta take their values (through QRPs or otherwise).
2) It was not clear to me how the value for β2 was selected. Based on the figure captions, I think it was just set to be β2=0.9, so 90% power. But the problem introduced by QRPs is that they tend to inflate standardized effect sizes. So, a replication of a QRP-influenced study might estimate power based on the effect size reported in the original study. Doing so will often lead to gross underestimation of power for the replication study (even though the replicator thinks they have 90% power, they might actually have 50% power). Also common, the replicator uses the same sample size as the original study, which again tends to lead to low power if the original study used QRPs. It is through these mechanisms that QRPs for an original study contribute to a low replicability rate (provided the replication study uses good practices).
3) As I read it, the headline result seemed to be that p-hacking doesn't have a large impact on replication, and therefore the explanation for surprisingly low replication must lie elsewhere. Unfortunately, the support for this claim hinges on the degree of p-hacking that one envisions, and it seems to me that the degree of p-hacking envisioned here is rather mild. My own experience suggests that most p-hacking flows from investigators' ignorance about what constitutes p-hacking, and in such cases, investigators can easily p-hack to a much greater degree than the simulations here suggest. I suspect that p-hacking investigators can easily conduct dozens if not hundreds of tests for every result ultimately published, which is a much more severe form of p-hacking than the simulations here envision. In these cases, p-hacking very well may be an important cause of non-reproducible results, thus overturning the major finding of this paper.
To be sure, the manuscript is abundantly aware that the degree to which p-hacking generates non-reproducible results depends on the degree of p-hacking, and both the results and text make that clear. So, I don't think the manuscript is 'wrong'. But, I fear that if one really wants to know how much p-hacking contributes to non-reproducible results, one has to know the extent to which p-hacked studies are indeed p-hacked.
-From the Features Editor: The article needs to explore levels of p-hacking higher than those explored in the current version and, if necessary, to revise the discussion and conclusions in the light of what these new analyses find.
Also, please consider discussing and citing the following paper:
Simonsohn et al 2015, http://dx.doi.org/10.1037/xge0000104
4) I also found the last simulation - meant to investigate the effect of removing outliers - unconvincing. As I understand it, the simulation generated hypothetical data sets that were the contaminated by outliers with a standard deviation ten-fold greater than the actual data generating process. It seems to me that this is a poor model for capturing outliers, because the outliers in this case are so anomalous that they corrupt the performance of the good-practice analysis. Thus we wind up with the head-scratching result that selective outlier removal improves FDR and RR. I don't think this set-up captures the actual hazards of selective outlier removal, and wouldn't put much stock in its results. To summarize, the simulation set-up needs to be more realistic and/or better justified.
5) A possible discussion point regarding the assumptions of the RR value. An interesting assumption in the RR value is that null/non-significant results are not replicated. And lowering the alpha threshold for statistical significance will increase the number of false negatives. So a possible outcome of focusing on improving RR with alpha thresholds that more false negatives go undetected and not replicated?
6) The authors use a group size of 20 (so total n=40) but sample size appears to be a key variable that will impact some of these measures (e.g. outlier exclusion). The researchers motivate their value by citing Marszalek, Barber, Kohlhart, & Holmes, 2011, Table 3.
First, I think the authors may be referring to table 1 to get the value of 40 (I am unable to locate the value in Table 3)?
Second, others (e.g. Fraley & Vazire 2014, 10.1371/journal.pone.0109019), found the average sample size (in social-personality) psychology research to be higher (here: 104). How dependent are the results and conclusions on the limited sample size? (especially for outlier exclusion). Also how dependent are the outlier exclusion results if more/less of the data points our outliers (currently 5% of data).
7) In Figure 3,4,6,9,11,12 and the associated text, there is no quantification about how much the "p-hacking" approach is worse and unprecise language is used, e.g. "is modest for high base rates" and the reader has to deduce the differences from the many-paneled figures. I think adding some summary numbers to the text (or an additional figure) to show the differences between methods would be useful (e.g. state RR difference when the base rate is 0.2 and 0.5 (with d=0.5, k=5) or maybe the total difference between the curves). This would be especially helpful when contrasting the differences between the "p-hacking" and "good practice" differences for the different thresholds where the reader has to deduce two differences from the graph and then compare those deduced differences in their heads.
8) One quite surprising result here was that selective outlier removal seems to increase the RR and perhaps needs a little more discussion. At the moment, a reader could read the paper and conclude that performing selective outlier removal is something that should be done to improve the RR. Is this the authors' position? If not, perhaps this should be explicitly stated.
9) The supplemental material (and a few places in the main text) suggest that QRPs might actually be favorable for scientific investigations because they increase the replicability rate. The text describes the situation properly, but I fear some readers will get the wrong impression. The favorable aspects very much depend on what a scientist wants (to avoid) out of their analyses. The supplemental material makes some claims about inflation and setting of Type I error rates and power that seem to contradict the Neyman-Pearson lemma. If not, then the multiple-studies researcher must using a larger sample size, so there are costs involved. This might be worth discussing.
10) In the Discussion the text suggests it will be difficult to increase replicability in fields with low base rates. To the contrary, I think it is easy: just increase the base rate. Scientists should do a better job picking hypotheses to test. They should not waste time testing hypotheses that would be surprising or counterintuitive. The text then goes onto discuss about how campaigns to reduce p-hacking may be ineffective. I get the point, but a field with a low base rate of hypotheses should have a low replication rate. Increasing replicability is not (or, should not) be the goal of scientific investigations.
11) The authors are familiar with some of my work on this topic (they cite several of my papers). There, the problem is not a low replication rate, but a "too high" replication rate. The problem is that if both original and replication scientists are using QRPs, then the replication rate is too high, compared to what would be expected with "good practice" analyses/experiments. In my view, this is the more serious problem with current practice, because it implies that the Type I error rate is higher than "good practice". This suggests that scientists are not doing what they intended to do. This different viewpoint struck me while reading the introduction of the paper. There it is noted that some people suggest that QRPs lead to low replication rates. But this claim never really made sense (at least not without more discussion) because QRPs increase the probability of rejecting the null; so QRPs increase the replication rate. Indeed, if the simulations were revised so that both the original and replication scientists used QRPs, there would be quite an increase in the replication rate, even when the true effect is 0.
https://doi.org/10.7554/eLife.58237.sa1Author response
[We repeat the points in the decision letter in italic, and give our responses in Roman.]
Essential revisions:
1) Equation (1) succinctly related replication rate (RR) to power and alpha. In some sense, almost everything follows from this equation. The details about how different QRPs affect alpha and beta are secondary (but useful) analyses. A further discussion of equation (1) might be worthwhile regardless of how alpha and beta take their values (through QRPs or otherwise).
We agree and hence we have further discussed Equation 1 by illustrating its major features in a figure (Figure 2).
2) It was not clear to me how the value for β2 was selected. Based on the figure captions, I think it was just set to be β2=0.9, so 90% power. But the problem introduced by QRPs is that they tend to inflate standardized effect sizes. So, a replication of a QRP-influenced study might estimate power based on the effect size reported in the original study. Doing so will often lead to gross underestimation of power for the replication study (even though the replicator thinks they have 90% power, they might actually have 50% power). Also common, the replicator uses the same sample size as the original study, which again tends to lead to low power if the original study used QRPs. It is through these mechanisms that QRPs for an original study contribute to a low replicability rate (provided the replication study uses good practices).
We agree that estimated effect sizes are overestimated by replicators in such scenarios, especially when non-significant results are put into the file drawer. The power of 90% was picked as the best-scenario value close to the average replication power (i.e. 92%) claimed by the OSF project, although we acknowledge that their actual power levels may have been lower for the reasons mentioned by the reviewer. In any case, we have rerun our computations with the above suggested power of 50% and checked if our conclusions are still valid under this condition. For example, Author response image 1 shows the rate of replication for a replication power of 50% instead of 90% (as in Figure 5 of the manuscript). It can be seen in this new figure that p-hacking would even be slightly less harmful to replication rates with low-powered replication studies than with high-powered replications. Thus low-powered replication studies would not change the conclusions of our paper. We now mention this point in the Discussion.
Author response image 1
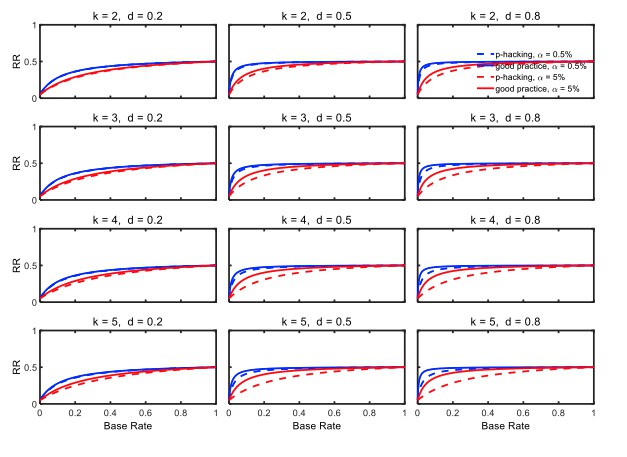
3) As I read it, the headline result seemed to be that p-hacking doesn't have a large impact on replication, and therefore the explanation for surprisingly low replication must lie elsewhere. Unfortunately, the support for this claim hinges on the degree of p-hacking that one envisions, and it seems to me that the degree of p-hacking envisioned here is rather mild. My own experience suggests that most p-hacking flows from investigators' ignorance about what constitutes p-hacking, and in such cases, investigators can easily p-hack to a much greater degree than the simulations here suggest. I suspect that p-hacking investigators can easily conduct dozens if not hundreds of tests for every result ultimately published, which is a much more severe form of p-hacking than the simulations here envision. In these cases, p-hacking very well may be an important cause of non-reproducible results, thus overturning the major finding of this paper.
To be sure, the manuscript is abundantly aware that the degree to which p-hacking generates non-reproducible results depends on the degree of p-hacking, and both the results and text make that clear. So, I don't think the manuscript is 'wrong'. But, I fear that if one really wants to know how much p-hacking contributes to non-reproducible results, one has to know the extent to which p-hacked studies are indeed p-hacked.
-From the Features Editor: The article needs to explore levels of p-hacking higher than those explored in the current version and, if necessary, to revise the discussion and conclusions in the light of what these new analyses find.
Also, please consider discussing and citing the following paper:
Simonsohn et al 2015, http://dx.doi.org/10.1037/xge0000104
We cannot rule out the possibility that some investigators p-hack to a more considerable degree than we have assumed in our computations. The extent of p-hacking remains a controversial issue, with some arguing and providing evidence that ambitious p-hacking is too complicated and thus not plausible (Simonsohn et al., 2015, p. 1149), and even that the frequency of any p-hacking has probably been overestimated (Fiedler & Schwarz, 2016). Unfortunately, the exact extent of p-hacking is difficult to determine and might strongly depend on the field of research. For example, in areas with small effect sizes, p-hacking might be more extensive than in fields with medium or large effect sizes. But even without knowing the true p-hacking rates, our analyses are still valuable, because they clearly show that evidence of massive p-hacking is needed before one can conclude that p-hacking is a major contributor to the replication crisis. Nevertheless, for most p-hacking methods we now consider more extensive p-hacking to address this point (k to a maximum of 8). Because we cannot see how one could perform so many different selective outlier removal attempts, however, we did not consider more extensive p-hacking with this strategy. We also included this point in the General Discussion.
4) I also found the last simulation - meant to investigate the effect of removing outliers - unconvincing. As I understand it, the simulation generated hypothetical data sets that were the contaminated by outliers with a standard deviation ten-fold greater than the actual data generating process. It seems to me that this is a poor model for capturing outliers, because the outliers in this case are so anomalous that they corrupt the performance of the good-practice analysis. Thus we wind up with the head-scratching result that selective outlier removal improves FDR and RR. I don't think this set-up captures the actual hazards of selective outlier removal, and wouldn't put much stock in its results. To summarize, the simulation set-up needs to be more realistic and/or better justified.
The simulation scenario that we used to contaminate normally distributed scores has previously been employed for assessing the efficacy of outlier elimination methods (e.g., Bakker & Wicherts, 2014; Zimmerman, 1998). For example, Bakker & Wicherts and also Zimmermann sampled normally distributed scores from N(d,1), d=0, 0.2, 0.5, 0.8 with probability 0.95 and contaminated these scores with outliers that were drawn with probability 0.05 from a normal distribution with a standard deviation of 20—even larger than our standard deviation of 10 that the reviewer regards as unrealistically large. Nonetheless, in order to check how the results would change with a less extreme contamination distribution as suggested by the reviewer, we changed the standard deviation of the outlier distribution to 5. We found pretty similar results, that is, the primary factor limiting the replication rate remains the base rate (see Author response image 2 which can be compared to Figure 16 in the main text with a standard deviation of 10). Besides, the Z-score method for identifying outliers is commonly used in psychology as the meta-analysis by Bakker & Wicherts has revealed; their meta-analysis also shows that absolute thresholds values for the Z scores of 2.0, 2.5 and 3.0 are common in psychological research. Thus, our simulations capture standard methods of data analysis. In the revision, we have stressed this point.
Author response image 2
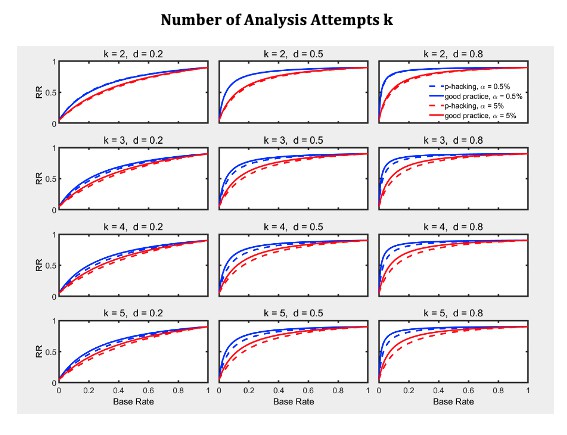
5) A possible discussion point regarding the assumptions of the RR value. An interesting assumption in the RR value is that null/non-significant results are not replicated. And lowering the alpha threshold for statistical significance will increase the number of false negatives. So a possible outcome of focusing on improving RR with alpha thresholds that more false negatives go undetected and not replicated?
Like others modeling replication rates, we assume that researchers only try to replicate significant results. As the reviewer notes, there will be fewer of these when alpha is lowered—whether a true effect is present or H0 is true—and this effect of alpha can clearly be seen in the probability of rejecting H0 (e.g., Figure 3). Naturally, our computations of RR take this effect into account, so the effects of alpha on RR can easily be seen (e.g., Figure 5). As the reviewer rightly notes, however, reducing alpha has an additional effect that is not evident in RR: namely, fewer replication studies will be needed, because fewer positive effects will be found. We have now mentioned this fact in the General Discussion, and we thank the reviewer for the suggestion.
6) The authors use a group size of 20 (so total n=40) but sample size appears to be a key variable that will impact some of these measures (e.g. outlier exclusion). The researchers motivate their value by citing Marszalek, Barber, Kohlhart, & Holmes, 2011, Table 3.
First, I think the authors may be referring to table 1 to get the value of 40 (I am unable to locate the value in Table 3)?
Second, others (e.g. Fraley & Vazire 2014, 10.1371/journal.pone.0109019), found the average sample size (in social-personality) psychology research to be higher (here: 104). How dependent are the results and conclusions on the limited sample size? (especially for outlier exclusion). Also how dependent are the outlier exclusion results if more/less of the data points our outliers (currently 5% of data).
Yes, we inferred this value from Table 3 (as indicated in the previous version) but not from Table 1, as the Reviewer seems to believe. Table 3 gives the group sample size.
First, the mean of the medians in Table 3 of Marszlek et al. (2011) is 18.9. The corresponding group size in the Open Science Replication Project (considering studies with significant t-tests) is 27.5 and thus not considerably off our value of 20. It is likely that sample sizes in published articles became larger or were already larger in the field of social psychology and personality (see Sassenberg & Ditrich, 2019, Advances in Methods and Practices in Psychological Sciences). Note that sample and effect size determine the statistical power of the original study. Thus if we would employ a larger group size, this would merely increase the statistical power to an unrealistically high level --- the estimated median power level has been 36% for psychological studies and is even lower in the neurosciences. In order to keep the power of the original studies at a realistic level, we would have to reduce the effect sizes in our computations. We refrained from doing this because the effect sizes of 0.2, 0.5, and 0.8 seem appropriate theoretical choices for demonstrating the effect of p-hacking on the replication rate with small, medium, and large effects. Nevertheless, we have addressed the issue of group size in the General Discussion.
Second, Fraley and Vazire (2014) have reported an average sample size of 104 in their meta-analysis of articles published in social-personality psychology. Unfortunately, this size refers to the total sample size and not to group size. For example, consider a 2 x 2 between factorial design, then each group would be comprised of 21 subjects. Nevertheless, their article contained additional information that we found worth mentioning – for example, they estimated the average power in this area as 50% with an average effect size of d = 0.43, and that the false positive rate is (at least ) 28% for a base rate of 20%. These values fit well with our analyses. The revised paper includes Fraley and Vazire.
Third, we have rerun the simulations on outlier exclusion with group sizes of 50 (i.e., sample sizes of 100) using the new scenario (see also our response to Comment 8 below). Author response image 3 shows the result (which should be compared to Figure 16 in the main text with a group size of 20). It is clear that there are no major changes in the effects of p-hacking, alpha, or base rate, even though overall replicability has increased because of the greater power associated with larger samples.
Author response image 3
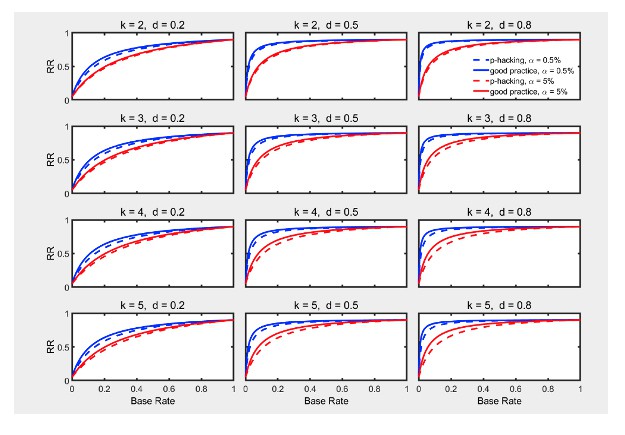
7) In Figure 3,4,6,9,11,12 and the associated text, there is no quantification about how much the "p-hacking" approach is worse and unprecise language is used, e.g. "is modest for high base rates" and the reader has to deduce the differences from the many-paneled figures. I think adding some summary numbers to the text (or an additional figure) to show the differences between methods would be useful (e.g. state RR difference when the base rate is 0.2 and 0.5 (with d=0.5, k=5) or maybe the total difference between the curves). This would be especially helpful when contrasting the differences between the "p-hacking" and "good practice" differences for the different thresholds where the reader has to deduce two differences from the graph and then compare those deduced differences in their heads.
We like the suggestion to include an additional figure that quantifies the shrinkage of the replication rate for various level of p-hacking. In the revised paper we have added such figures along with some text that describes the resulting shrinkage.
8) One quite surprising result here was that selective outlier removal seems to increase the RR and perhaps needs a little more discussion. At the moment, a reader could read the paper and conclude that performing selective outlier removal is something that should be done to improve the RR. Is this the authors' position? If not, perhaps this should be explicitly stated.
This is certainly not our position, although our simulations indicate that selective outlier removal can improve the replication rate and lower the false positive rate. In response to this comment, we have reconsidered our outlier removal simulation. In the previous version of the manuscript, the simulated researchers always started with “no removal” and then tried more and more removal. However, “no removal” is not the best method if there are outliers. It seems perhaps a more conventional practice to remove outliers before applying a statistical test (see the meta-analysis by Bakker & Wicherts, 2014 that we cite now). Under this alternative scenario, subsequent “removals” might especially be prone to Type I error inflation and thus lower the replication rate. We have rerun our simulations under this scenario. The results indicate that multiple removals would lower the replication rate. Author response table 1 shows how we have changed the sequence of outlier removal attempts for the simulations in the revised paper. We have also modified the text in the manuscript accordingly.
Author response table 1.
We have also explicitly stated that outlier checks should be made before statistical testing and that multiple testing with different outlier criteria is unacceptable because of the increased Type 1 error rate, regardless of RR.
9) The supplemental material (and a few places in the main text) suggest that QRPs might actually be favorable for scientific investigations because they increase the replicability rate. The text describes the situation properly, but I fear some readers will get the wrong impression. The favorable aspects very much depend on what a scientist wants (to avoid) out of their analyses. The supplemental material makes some claims about inflation and setting of Type I error rates and power that seem to contradict the Neyman-Pearson lemma. If not, then the multiple-studies researcher must using a larger sample size, so there are costs involved. This might be worth discussing.
First, in the revision we have emphasized further that we do not suggest that QRPs might actually be favorable (e.g., see the Conclusions). Even in the section on outlier removal, we have now stressed that researchers should carefully examine their data before conducting any statistical tests in order to avoid inflating the Type 1 error rate. Second, the analysis in Appendix subsection “Type 1 error rate versus power” suggests that p-hacking can produce a larger power compared to good practice for the same level of Type I error. However, as the reviewer has correctly noted and as we have stated there, much larger sample sizes are the price of the potential superiority of this QRP. So the benefit actually comes from the larger samples involved with this QRP, not the QRP per se.
10) In the Discussion the text suggests it will be difficult to increase replicability in fields with low base rates. To the contrary, I think it is easy: just increase the base rate. Scientists should do a better job picking hypotheses to test. They should not waste time testing hypotheses that would be surprising or counterintuitive. The text then goes onto discuss about how campaigns to reduce p-hacking may be ineffective. I get the point, but a field with a low base rate of hypotheses should have a low replication rate. Increasing replicability is not (or, should not) be the goal of scientific investigations.
We have sympathy with this comment and agree that researchers should prefer to test hypotheses deduced from a plausible theory. However, we also see practical constraints that make it difficult to increase base rates, contrary to the reviewer’s suggestion that this would be easy. For example, consider research in clinical pharmacology aiming at discovering better medicines, such as the search for an effective vaccine against an infectious disease. Although we are not pharmacologists, we can imagine that the search for such a vaccine can be very haphazard. Pharmacological research often tests many ineffective drugs before an effective one is discovered. In such areas, the base rate could necessarily be low and only increased by a better theoretical understanding of the disease and how drugs interact with it. When such understanding is difficult to achieve, some black-box approach and the associated low base rate may be the only option. This more philosophical issue is beyond the aim of our paper, which focuses on the question of why significant results often do not replicate, but we now comment on the potential difficulty of increasing base rate in the Discussion.
11) The authors are familiar with some of my work on this topic (they cite several of my papers). There, the problem is not a low replication rate, but a "too high" replication rate. The problem is that if both original and replication scientists are using QRPs, then the replication rate is too high, compared to what would be expected with "good practice" analyses/experiments. In my view, this is the more serious problem with current practice, because it implies that the Type I error rate is higher than "good practice". This suggests that scientists are not doing what they intended to do. This different viewpoint struck me while reading the introduction of the paper. There it is noted that some people suggest that QRPs lead to low replication rates. But this claim never really made sense (at least not without more discussion) because QRPs increase the probability of rejecting the null; so QRPs increase the replication rate. Indeed, if the simulations were revised so that both the original and replication scientists used QRPs, there would be quite an increase in the replication rate, even when the true effect is 0.
We agree that an excess of positive results due to QRPs—in both original studies and replication attempts—is another potential problem that could influence the replication rate. As the reviewer notes, the replication rate will be unrealistically high if QRPs are used to induce a significant result in the replication data. This situation, however, is different from the situation in which an unbiased researcher tries to replicate the results of an original study without using QRPs, and this is the situation producing the empirically low replication rates that have alarmed many researchers. We have now made clear that our analysis focuses on this latter replication situation.
https://doi.org/10.7554/eLife.58237.sa2Article and author information
Author details
Funding
No external funding was received for this work.
Acknowledgements
We thank Eric-Jan Wagenmakers and all reviewers for helpful comments.
Publication history
- Received: April 24, 2020
- Accepted: September 14, 2020
- Accepted Manuscript published: September 15, 2020 (version 1)
- Version of Record published: October 15, 2020 (version 2)
Copyright
© 2020, Ulrich and Miller
This article is distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use and redistribution provided that the original author and source are credited.
Metrics
-
- 8,565
- views
-
- 487
- downloads
-
- 17
- citations
Views, downloads and citations are aggregated across all versions of this paper published by eLife.
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
Meta-Research: Questionable research practices may have little effect on replicability
eLife 9:e58237.
https://doi.org/10.7554/eLife.58237





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}