
Abstract
The present review summarizes research investigating how words are identified parafoveally (and foveally) in reading. Parafoveal and foveal processing are compared when no other concurrent task is required (e.g., in single-word recognition tasks) and when both are required simultaneously (e.g., during reading). We first review methodologies used to study parafoveal processing (e.g., corpus analyses and experimental manipulations, including gaze-contingent display change experiments such as the boundary, moving window, moving mask, and fast priming paradigms). We then turn to a discussion of the levels of representation at which words are processed (e.g., orthographic, phonological, morphological, lexical, syntactic, and semantic). Next, we review relevant research regarding parafoveal processing, summarizing the extent to which words are processed at each of those levels of representation. We then review some of the most controversial aspects of parafoveal processing, as they relate to reading: (1) word skipping, (2) parafoveal-on-foveal effects, and (3) n + 1 and n + 2 preview benefit effects. Finally, we summarize two of the most advanced models of eye movements during reading and how they address foveal and parafoveal processing.
Similar content being viewed by others

Introduction
Obtaining and processing visual information is critical to a wide variety of tasks, especially reading a passage of text. We make eye movements in order to move the fovea (which corresponds to the central 2° of the visual field) to the location we wish to process. As distance from fixation increases, acuity drops off rapidly in the parafoveal region (from the foveal region up to 5° of visual angle from fixation; see Fig. 1). For most tasks that require rapid processing of details, foveal information is essential (Rayner, 1998, 2009). Because of this, detection of a salient eccentric stimulus will almost invariably trigger an eye movement toward the region of interest, ensuring that its image falls on the fovea and can be processed in detail. Even though foveal information is tremendously important for analyzing an image, viewers in tasks like visual search and scene perception also need to use information from the parafovea, although its resolution is considerably poorer. Reading, however, is a very different task from scene perception or visual search, and the way parafoveal information is used during silent reading may be very different from the way it is used in tasks that involve exploring or searching the visual field. Parafoveal information is undoubtedly used to provide information as to where the eyes should move next (as in scene-based tasks). However, words in a text must be identified and analyzed at many different levels of representation. The extent to which that is done parafoveally affects processing of those words once they are ultimately fixated.

The foveal, parafoveal, and peripheral regions when three characters make up 1° of visual angle. The eye icon and dotted line represent the location of fixation
In this review, we will summarize how parafoveal information is used in reading, how parafoveal processing compares with foveal processing, and how foveal and parafoveal processing interact to make reading efficient. After providing a description of the levels of representation of words in reading and what is required of the reader in order to accomplish the task, we will discuss some common paradigms (mostly using eye tracking to monitor eye movements during reading and manipulate various aspects of the text depending on the location of the reader’s gaze) that are used to study parafoveal processing during reading. Next, we will summarize experimental findings illustrating what aspects of words are processed parafoveally. Finally, we will discuss two of the most prominent models of eye movements during reading and how they deal with parafoveal processing.
Eye movements during reading
It is well known that during reading, we make a series of ballistic eye movements, saccades, which are separated by fixations (periods of time when the eyes are relatively still); it is during fixations that new information is acquired from the text, since no useful information can be acquired while the eyes are moving, due to saccadic suppression (Matin, 1974). Fixations typically last about 200–250 ms, although there is considerable variability across readers (Rayner, 1978b, 1998, 2009); saccades typically last 20–50 ms (depending on how far the eyes move) and progress about seven to nine letter spaces,Footnote 1 with some variability. Readers directly fixate only about 70% of the words in the text, skipping the other 30%. About 10%–15% of saccades are regressions back to previously read text.
Because our primary focus in this review is on parafoveal processing, we will not discuss in any detail the nature of foveal processing during eye movements in reading. However, it is important to understand that the primary determinant of how long the eyes remain fixated seems to be how easy or difficult the fixated word is to process. Thus, fixation time on a word is very much influenced by factors such as word frequency (how commonly the word is encountered in the language), age of acquisition (the age at which the word was learned), word predictability (how predictable a word is, given the prior context), word length, neighborhood size (how many words can be formed by changing one letter in the word), and so on (for reviews, see Hyönä, 2011; Rayner, 1998, 2009). Clearly, the primary goal of the reader is to process the fixated word to ascertain its meaning. The fact that readers do not need to fixate all of the words in a sentence in order to comprehend it indicates that, in some cases, they are able to process two words (and maybe three words if they are all short words) in a single fixation. We shall return to the issue of word skipping later, but it is important to realize that while the strongest predictor of word skipping is word length (Brysbaert, Drieghe, & Vitu, 2005; Brysbaert & Vitu, 1998), skipping does not just involve short words. Of course, readers are much more likely to skip short 2–3 letter words than longer 9–12 letter words (Rayner & McConkie, 1976), but sometimes longer words are skipped if they are predictable from the prior context (Rayner, Slattery, Drieghe, & Liversedge, 2011). Clearly, in such cases, the skipped word must have been processed parafoveally. But even when words are not skipped, readers seem to obtain some useful information from parafoveal words. The question of to what extent this is possible will be the focus of our review. First, however, we take a step back and ask the question of whether it is possible, in principle, to identify a parafoveal word in isolation.
Can words be identified at all in the parafovea?
As was mentioned above, the purpose of eye movements is to bring the area of interest to the fovea, where processing is most efficient. This raises the question of whether any meaningful linguistic information can be obtained from parafoveal visual input apart from establishing the mere existence of a stimulus in a certain location. The answer to this question is clearly yes. Bouma (1970, 1973) found that subjects were able to name isolated letters, letters within words, and complete words that were presented for 100 ms at different eccentricities in the parafovea and that this ability was constrained mainly by visual acuity (i.e., by the eccentricity of the stimulus) and crowding (i.e., the presence of other stimuli around the target stimulus; Bouma, 1973). Thus, subjects were able to use parafoveal information about a word to access the word’s phonology—which is necessary to name it aloud. Importantly, subjects were better at naming words than pronounceable nonwords, suggesting that they not only had processed information about the letters, but also had accessed the words’ lexical entries.
Lee, Legge, and Ortiz (2003) presented evidence suggesting that lexical information about a word is of the same quality when obtained from the fovea or parafovea but that the extraction of that information occurs more slowly in the parafovea than in the fovea. They found that frequency effects in a lexical decision task were apparent at short exposure durations (25–50 ms) in foveal vision and only at longer exposure durations (100 ms and later) in parafoveal vision. Similarly, Rayner and Morrison (1981) found that it is much easier to identify a parafoveal word when the subject can make an eye movement to it and that subjects prefer to move their eyes rather than stay on a fixation point in such tasks. The latency to make an eye movement to the word in such tasks is 30–100 ms shorter than the average fixation duration (250 ms) in reading (Rayner, 1978a, 1978b).
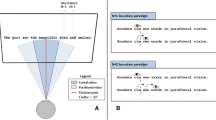
These experiments (and others; see Rayner, 1998) suggest that it is possible to obtain and use parafoveal information when the task is limited to naming isolated parafoveal words. In reading, however, parafoveal information about the upcoming word obtained during a fixation must be retained through the subsequent saccade and integrated with the foveal processing of the same word during the next fixation in order to facilitate its identification. The best way to test to what degree this can be accomplished is to use a gaze-contingent naming paradigm (Rayner, 1978c), in which subjects are asked to move their eyes to a word displayed in the parafovea (to either the left or the right of fixation) and name it (see Fig. 2). In this paradigm, the experimenter sets an invisible boundary between the starting fixation point and the target word. While the subject’s eyes are on the fixation point, the parafoveal stimulus is a preview word (or nonword) that, once the subject’s eyes cross the boundary, changes to a target word, which is named (lexical decision and categorization responses have also been used). The relationship between the preview and target can be manipulated, and the experimenter compares the speed of processing the target (e.g., naming latency) when the preview is related to it, as compared with when it is unrelated to it. Studies using this paradigm have revealed that phonological and orthographic information is obtained parafoveally and integrated with subsequent foveal information (Balota & Rayner, 1983; Henderson, Dixon, Petersen, Twilley, & Ferreira, 1995; Rayner, 1978c; Rayner, McConkie, & Ehrlich, 1978; Rayner, McConkie, & Zola, 1980) and that orthographic information is not based purely on visual similarity (i.e., write was facilitated as much by the parafoveal presentation of WRITE as by write). Furthermore, and consistent with the view that visual information is not integrated across saccades, Rayner, McConkie, and Zola (1980) found that changing the case of the letters in a word during a saccade did not disrupt naming. They also did not find evidence that semantic information was obtained parafoveally.

Example of the gaze-contingent naming paradigm. A subject maintains fixation on a central cross until a preview word appears in the parafovea. Once the word appears, the subject makes a saccade toward it, and it changes the target (named) word
Parafoveal information and the reading process
Given the results of the experiments above, the central question about parafoveal processing becomes clear. The fact that subjects can obtain information from the parafovea when that is the only task required of them is quite easy to establish and not particularly surprising. Rather, the central question is the following: How do foveal and parafoveal processing interact when both types of information are useful and available simultaneously (which is the case during reading)? Reading a sentence, instead of an isolated word, adds complexity to the word identification process: At any given moment before a reader arrives at the end of a sentence, there are several words waiting to be identified. Thus, we cannot assume that we would find that the same type of parafoveal information that is found in single-word identification is obtained during reading, when a reader’s fovea will almost always contain a different word that must be processed with higher priority. Part of the reason why reading is much more complex than isolated word naming is that, in reading, linguistic information is compressed into a line of text that follows a strict serial order. This means that parafoveal information (e.g., information about a nonfixated word) may not only be irrelevant to identification of the foveated word, but may actually hinder it by activating a competitor of that word. On the other hand, the efficiency of reading can be greatly increased if readers start to identify the upcoming parafoveal word before they fixate it. Because of this, readers have to allocate their attention carefully in order to obtain parafoveal information to a degree that is useful, but not harmful.
When one is reading, words are represented on many levels of analysis, and reading can be thought to proceed from low to high levels of representation. Consider how a foveal word is identified. First, visual information is obtained, and the orthography (letter identity and word length), phonology (sounds), and morphology (units of meaning, grammatical gender, etc.) of the word are analyzed. Then the lexical representation (the abstract representation of the word form) is accessed. Finally, the semantic (word meaning) and syntactic (grammatical role) representations of the word are accessed and integrated into the meaning of the sentence. The reader not only must use visual, orthographic, phonological, and morphological information to identify individual words, but also must keep track of the currently fixated word and the preceding words, their meanings, syntactic properties, and resulting thematic roles. It is quite likely that, given all this necessary processing for a foveal word, readers will often not have many resources left to identify a parafoveal word (exceptions will be discussed below).
Experimental paradigms and phenomena used to study parafoveal processing
There are many ways to study reading, but most of the studies reported here used eye movements to make inferences about cognitive processing during reading. Of the studies that use eye movement data, there are two general types: corpus analyses and experimental manipulations. Corpus analyses use many dependent variables or reading measures on almost every word in a sentence and a large number of predictor variables to fit regression models to the data (for classic examples of such studies, see Kennedy & Pynte, 2005; Kliegl, Nuthmann, & Engbert, 2006; Pynte & Kennedy, 2006). The advantage of these analyses is that they involve large amounts of data (since there is one observation per subject per word),Footnote 2 which provide enough statistical power to analyze the influence of several predictors at once. The disadvantage is that the stimuli may not be very well controlled and the analyses may overestimate the effect of a predictor or attribute to it the effects of some underlying predictor that is not entered into the model (for further discussion, see Drieghe, 2011; Kliegl, 2007; Rayner, Pollatsek, Drieghe, Slattery, & Reichle, 2007). In contrast, studies using experimental manipulations have subjects read sentences designed by the experimenter to have specific properties; most often, this manipulation is of one or two target words. This type of experiment has the advantage that the stimuli are much more controlled but does not have as much statistical power as corpus analyses, due to a smaller number of observations.
With both experimental manipulations and corpus analyses, three phenomena are quite relevant to understanding parafoveal processing. These are skipping effects, parafoveal-on-foveal (PoF) effects, and preview benefit effects. Skipping effects are well documented and not overly controversial. However, in some sense, they are not well understood, because experimenters cannot easily control whether a reader skips a word. Certain types of PoF effects, on the other hand, are hotly debated, both as to their existence and, if they do exist, as to their cause. Preview benefit effects are better understood than PoF effects, but there are controversies as well. We will briefly describe these effects here and discuss them in more detail later in the article. In this section, we will also introduce some important paradigms that have been used to examine parafoveal processing during reading.
Skipping effects
As was noted earlier, during reading, approximately a third of the words in the text are skipped (Rayner, 1998, 2009). In light of this pervasive finding, it is almost impossible to argue that the skipped word was not identified parafoveally (Rayner, White, Kambe, Miller, & Liversedge, 2003). However, it is important to note that the majority of words that are skipped are short and many of them are closed-class words, such as to, for, in, the, and so forth (see Blanchard, Pollatsek, & Rayner, 1989; Brysbaert & Vitu, 1998; O’Regan, 1979, 1980; Rayner & McConkie, 1976; Rayner, Sereno, & Raney, 1996), or highly predictable from the prior context (Ehrlich & Rayner, 1981; Hyönä, 1995; Rayner & Well, 1996; Rayner, Slattery, et al., 2011), although the effect of predictability is not modulated by word length information obtained from the parafovea (Drieghe, Brysbaert, Desmet, & De Baecke, 2004; Juhasz, White, Liversedge, & Rayner, 2008). In these cases, it is unclear exactly what information contributed to the decision to skip the word: The skipping decision could have been a result of actual semantic processing or of orthographic information simply confirming one of a constrained set of lexical candidates. The latter idea fits in well with the finding that readers are more likely to skip words (as compared with nonwords; Blanchard et al., 1989; White, Warren, & Reichle, 2011; Yen, Tsai, Tzeng, & Hung, 2008), suggesting that lexical status contributes to the decision to skip a word. Additionally, skipping, especially of short words, can also be caused by simple oculomotor error resulting in mislocated fixations (Nuthmann, Engbert, & Kliegl, 2005). In some cases, an unusual feature of the parafoveal word may have an attraction effect that either prevents skipping of the upcoming word if it is unusual itself or increases the probability of skipping the upcoming word if the unusual feature is to the right of it (Hyönä, 1995). Oculomotor error can also explain why readers sometimes skip random sequences of letters (Drieghe, Rayner, & Pollatsek, 2005). It is possible that the processes leading to a skipping decision differ depending on the properties of the word being skipped. Finally, Kliegl and Engbert (2005) observed that, as compared with nonskipping cases, fixations prior to skipping high frequency words were shorter and fixations prior to skipping low frequency words were longer. This might be considered a PoF effect (see below).
Parafoveal-on-foveal effects
PoF effects occur when the difficulty of processing a parafoveal word affects how long the eyes stay on the foveal word. In theory, these effects could be either facilitatory or inhibitory. Obviously, for parafoveal processing to affect foveal processing, the parafoveal word must, to some extent, be processed concurrently with the foveal word. While low-level PoF effects such as the effect of unusual parafoveal letter strings, especially at the beginning of a parafoveal word, are well established, whether higher-level processes such as lexical or semantic processing can lead to PoF effects is controversial (Hyönä & Bertram, 2004). Both types of PoF effects will be discussed in more detail below.
Preview benefit effects
One major advantage of experimental manipulations over corpus analyses is that, because the location of the eyes can be measured online, the text can be manipulated as the subject is reading. This is a great advantage to researchers studying parafoveal processing during reading, since it allows them to control the properties of the parafoveal word. In the gaze-contingent boundary paradigm (Rayner, 1975b), the experimenter places an invisible boundary to the left of the target word, the preview of which is manipulated (similar to the parafoveal naming studies mentioned above; see Fig. 3). While a reader’s gaze is to the left of the boundary, the target word is replaced with a preview that may share all (identical control condition) or very few properties of the target word (e.g. an unrelated word or random letters). When the reader’s eyes cross the boundary location, the preview word automatically changes to the target word. The display change occurs during a saccade when vision is effectively suppressed and, therefore, is generally not seen by the reader. If the target is processed faster (as evidenced by shorter fixation times) when the preview is related, as compared with when it is unrelated, to the target word, this is considered a preview benefit. Numerous experiments (discussed below) have documented preview benefit effects, and White et al. (2011) recently showed that they occur independently of position in the sentence (occurring for sentence-initial, -internal, and -final words).

Example of the boundary paradigm. When the subject’s eyes cross an invisible boundary before a critical word in the sentence, it changes from the preview to the target
Recently, Reingold, Reichle, Glaholt, and Sheridan (in press) manipulated the frequency of target words (high vs. low) as well as their availability for parafoveal processing during fixations on the pretarget word such that there was either a valid or an invalid preview. The influence of the frequency by preview validity manipulation on the distributions of fixation durations was examined. They used a survival analysis technique that provided precise estimates of the timing of the first discernible influence of word frequency on the fixation on the target word. Using this technique, they found a significant influence of word frequency on fixation duration in normal reading (valid preview) as early as 145 ms from the start of fixation. The time course of frequency effects was strongly influenced by preview validity, with the frequency effect being apparent much later in processing when there was not a valid preview. These results demonstrate the crucial role of parafoveal processing in enabling direct lexical control of fixation times.
While experiments designed to study preview benefit may seem unnatural (when we read, words do not normally change in front of our eyes), they must reflect some aspect of the underlying process of reading; there would be no preview benefit if the preview had not been processed parafoveally. As was noted above, most subjects are not aware that any of the words are changing in such paradigms, so it is unlikely that the experimental manipulation would alter their reading behavior. Furthermore, because the preview does not change to the target until the subject makes a saccade toward it, it is reasonable to assume that the reader would not process it differently than any other parafoveal word in the experimental sentence or, indeed, in a nonexperimental situation. The majority of what is known about the type of information obtained from parafoveal words has involved using this paradigm, so an entire section in this article is dedicated to summarizing evidence from preview benefit studies. First, though, we discuss several other paradigms that are used to study parafoveal processing.
Moving-window/moving-mask experiments
Other gaze-contingent techniques can be used to examine the use of foveal and parafoveal information during reading. One indication of how much readers rely on foveal and parafoveal information is how well they can read when only one of the two sources of information is available. To do this, McConkie and Rayner (1975; see also Rayner & Bertera, 1979) introduced a paradigm in which they restricted readers to being able to see only the word in the fovea and a specific area around it (see Fig. 4). In this moving-window paradigm, the eyes are monitored, and accurate information is provided within the window area, with the text outside the window replaced by other letters (typically with xs or random letters).

Example of the moving-window experiment with a two-word window. On each fixation, the fixated word and one word to the right are revealed, while all other letters are replaced with xs
Research using the moving-window paradigm has revealed that readers of English typically have a perceptual span (i.e., the area from which they obtain useful information) extending from 3–4 letter spaces to the left of fixationFootnote 3 (McConkie & Rayner, 1976; Rayner, Well, & Pollatsek, 1980) to 14–15 letter spaces to the right of fixation (McConkie & Rayner, 1975; Rayner & Bertera, 1979; see Rayner, 1998, 2009, for further reviews). Another way to describe the size of the perceptual span is that it extends from the beginning of the currently fixated word to three words to the right of fixation for readers of English (Rayner, Castelhano, & Yang, 2009; Rayner, Slattery, & Bélanger, 2010; Rayner, Well, Pollatsek, & Bertera, 1982). As long as the letters of the fixated word and the following word are available and the rest of the letters are replaced with visually similar letters (and the spaces between words are left intact), readers are typically unaware that anything is strange about the text, and reading is only about 10% slower than without a window (Rayner et al., 1982). If three words (the currently fixated and next two words to the right) are available, reading is generally equivalent to normal (Rayner, Slattery, & Bélanger, 2010; Rayner et al., 1982). Thus, clearly some information is utilized from outside the fovea. Interestingly, the asymmetry is reversed for readers of Hebrew, which is printed right to left (Pollatsek, Bolozky, Well, & Rayner, 1981). Readers of Hebrew also have a smaller perceptual span, since the average word length in Hebrew is shorter. Similarly, Inhoff and Liu (1998) found that Chinese readers have a perceptual span of one character to the left and three characters to the right of fixation, consistent with the high information density of Chinese characters. Likewise, readers of Japanese have a smaller span (Ikeda & Saida, 1978). While comparisons between these experiments may give the impression that Hebrew or Chinese readers obtain less information on a fixation (i.e., have smaller perceptual spans, physically), the spans are equivalent when the number of words is considered, instead of the number of characters.
The perceptual span can also be influenced by the foveal load (how easy or difficult the fixated word is to process; Henderson & Ferreira, 1990; Kennison & Clifton, 1995) and by the reader’s working memory span. Below, we will discuss the effect of foveal load in more detail. Osaka and Osaka (2002) demonstrated in a moving-window experiment that readers with higher working memory spans were less disrupted by small windows than were those with smaller working memory spans. Thus, although more availability of parafoveal information (e.g., larger window sizes in moving-window experiments) leads to better reading fluency, this dependency on parafoveal information can be (to some extent) compensated for by higher working memory spans.
Other interesting findings are that (1) beginning readers (Häikiö, Bertram, Hyönä, & Niemi, 2009; Rayner, 1986) and dyslexic readers (Rayner, Murphy, Henderson, & Pollatsek, 1989) have smaller spans than do skilled readers; (2) faster readers (around 330 wpm) have a larger perceptual span than do slower readers (around 200 wpm); the slower readers’ span reached asymptote with a window comprising the fixated word and one word to the right of fixation (Rayner, Slattery, & Bélanger, 2010); (3) older readers (mean age of over 70 years) have a smaller and less asymmetric perceptual span than do younger college-aged readers (Rayner, Castelhano, & Yang, 2009) thus yielding smaller preview benefit (Rayner, Castelhano, & Yang, 2010); and (4) skilled deaf readers have a larger perceptual span than do hearing controls (Bélanger, Slattery, Mayberry, & Rayner, 2011).
The extent to which reading is disrupted when only foveal information is available (e.g., in the aforementioned moving-window experiments) can be compared with cases in which only parafoveal information is available. Rayner and Bertera (1979; see also Fine & Rubin, 1999a, 1999b, 1999c; Rayner, Inhoff, Morrison, Slowiaczek, & Bertera, 1981) used a variation of the moving-window paradigm, the moving-mask paradigm (see Fig. 5), to mask foveal letters while retaining the letters in the parafovea and periphery. When the mask was small enough to allow some information to reach the fovea (i.e., if it was only 1–5 letters wide, with 3 letters equaling 1° of visual angle), subjects read at a reduced rate but were still able to obtain information beyond the mask. As the size of the mask increased, reading efficiency dropped precipitously. When the mask was extremely wide (13–17 letters), subjects were able to report very little information about the sentence; in the intermediate conditions (7–11 letters), where the mask covered the entirety of the fovea but only some of the parafovea, readers made a large number of errors when reporting the sentences. The nature of these errors (e.g., reading pretty as priest or profits as politics) indicates that readers were struggling to guess the correct word mostly on the basis of low-level features such as word-initial letters and word length. Even though the manipulation is quite distinct from natural reading, this type of study clearly demonstrates the limits of parafoveal processing in reading and, consequently, the importance of foveal processing.

Example of the moving-mask experiment with an 11-character mask. On each fixation, the fixated letter and five letter spaces to the left and right are replaced with xs, while all other letters are revealed
Parafoveal information is still very important to reading, though. Rayner, Liversedge, and White (2006; see also Inhoff, Eiter, & Radach, 2005) found that readers’ performance declined markedly when, on each fixation, the word to the right of fixation disappeared or was masked 60 ms after fixation onset. This is in marked contrast to findings that readers were able to read sentences fairly normally when the fixated word disappeared or was masked 60 ms after fixation onset (Liversedge et al., 2004; Rayner et al., 1981; Rayner, Liversedge, White, & Vergilino-Perez, 2003; Rayner, Yang, Castelhano, & Liversedge, 2011). Furthermore, these “disappearing text” studies also demonstrated that there was still a word frequency effect when the fixated word disappeared; readers looked longer at low frequency words than at high frequency words. This provides very good evidence that lexical processing is the engine that drives the eyes through text (see also Staub, White, Drieghe, Holloway, & Rayner, 2010). These findings do not mean that readers are able to fully process and identify the fixated word in 60 ms but that 60 ms is the time that is needed to get the information into the processing system. It further suggests that readers fixate words much longer than necessary to obtain sufficient visual information to identify them. But, under normal circumstances, the extra time is not wasted, since readers can begin to process the upcoming word parafoveally. In the next two sections, we will discuss how parafoveal information influences where readers’ eyes move next and how it can facilitate subsequent foveal processing.
In general, discussions of eye movements during reading break down the influences of the words in the text into two decisions: where and when to move the eyes. Generally, parafoveal information is used to determine where to move the eyes, while information obtained foveally (i.e., word frequency, etc.) is the major determiner of when to move the eyes. As we noted briefly above, some research has suggested that information obtained parafoveally can influence fixation times on the foveal word (i.e., PoF effects) and the probability that the upcoming word will be skipped; these effects will be discussed in a separate sections below. Importantly, though, information about a word can be obtained before the eyes fixate it, and this parafoveal preprocessing facilitates the foveal processing of that word. As we will discuss below, these preview benefit effects can occur at many levels of processing. First, we discuss the influence of parafoveal information on where to move the eyes.
The use of parafoveal information to guide where the eyes move
Across many tasks, how to allocate visual attention is closely related to the problem of where to move the eyes; in fact, in most cases, an attention shift to a new location necessarily precedes an eye movement to that location (Deubel & Schneider, 1996; Rayner et al., 1978; Shepherd, Findlay, & Hockey, 1986). Because of this, we can assume that, in most cases, a viewer’s attentional focus coincides with the fovea and he/she constantly has to decide whether to maintain attention there or to shift attention to a location currently in the parafovea. In visual search, it has been argued that subjects use parafoveal information, represented in a saliency map, to guide their eye movements (Koch & Ullman, 1985). The majority of this review is concerned with the fact that parafoveal information is used for more than reading (i.e., to process information to some extent before the word is fixated), especially since, in reading, the direction of the next saccade is largely determined by the writing system. However, as in visual search (and scene perception), the decision of exactly where to move the eyes next in reading is greatly influenced by parafoveal information.
Readers rely on parafoveal information about word length to segment the text and plan saccades (Morris, Rayner, & Pollatsek, 1990; Paterson & Jordan, 2010; Perea & Acha, 2009; Pollatsek & Rayner, 1982; Rayner, 1979; Rayner, Fischer, & Pollatsek, 1998). This is possible since, in English, as well as in many other languages, words are separated by spaces in the text. In fact, for readers of English, normal spacing leads to the fastest processing of text; reading rate is fastest, mean fixation durations are shortest, and there are fewer regressions when the text contains normal spaces, as compared with when the spaces are replaced by the letter x (e.g., onexword), when the text contains spaces but the words are flanked by x (e.g., xonex xwordx), or when the spaces are removed entirely (e.g., oneword; Perea & Acha, 2009; Rayner et al., 1998). Furthermore, inserting two spaces between words may improve reading (Drieghe, Brysbaert, & Desmet, 2005). One reason why space information may be so important is that readers most frequently make saccades to a position slightly to the left of the center of a word—the preferred viewing location (PVL; Rayner, 1979).Footnote 4 Readers would not be able to make these saccades systematically without the ability to obtain parafoveal information about the word they intend to fixate next. Interestingly, although word predictability influences fixation time on a word and word skipping probability, it does not influence where in a word the eyes land (Rayner, Binder, Ashby, & Pollatsek, 2001; Vainio, Hyönä, & Pajunen, 2009).
There is one important exception that suggests that spacing or word length information may be less important than the previous studies suggest—namely, the existence of unspaced orthographies, such as Chinese. In Chinese, words are composed of one to four characters (morphemes) and written without spaces between words. Therefore, word boundaries in Chinese are more ambiguous (i.e., readers disagree sometimes as to where the boundaries between words are; Bai, Yan, Liversedge, Zang, & Rayner, 2008; Hoosain, 1992). While skilled Chinese readers do not show any benefit from reading text with spaces inserted between word boundaries (or with highlighting to mark word boundaries) over reading canonically unspaced text, they do show a deficit in processing text in which spaces are inserted between every character or between some characters, resulting in character combinations that produced nonwords (Bai et al., 2008). These data suggest that, although spaces between words may be advantageous (e.g., the nonword condition was most difficult), readers who are used to segmenting words on the basis of prior language exposure do not need the orthography (e.g., spaces between words) to help them do this.Footnote 5 Furthermore, because Chinese words are physically shorter (most consist of only two characters), the upcoming word may still fall in the fovea—in which case, word segmentation may be easier due to better acuity.Footnote 6
Despite the special case of Chinese, further evidence that word length information is processed parafoveally during reading comes from a boundary experiment in English in which the word length of the parafoveal preview was manipulated (Inhoff, Liu, Starr, & Wang, 1998). Readers made shorter saccades (e.g., to the PVL of a short word) when the preview was of two words separated by a space than when the preview was of a long word (where the PVL would be shifted to the right). Similarly, Inhoff, Radach, Eiter, and Juhasz (2003) provided previews for a target (e.g., subject) that had the same word length (e.g., subtect or mivtirp) or a different word length than the target (e.g., sub ect or miv irp); they also varied whether the preview word was orthographically similar to the target (e.g., subtect or sub ect) or a nonword that was not orthographically similar (e.g., mivtirp or miv irp). Inhoff et al. (2003) found that word length information was processed parafoveally (viewing times were shorter when preview word length was accurate) and the effects of word length and word/nonword status did not interact. They concluded that parafoveal word length information is used for saccade targeting but that this is a functionally autonomous process from word recognition processes (i.e., lexical access). Juhasz et al. (2008) and White, Rayner, and Liversedge (2005b) obtained results suggesting that word length information allows for the narrowing of lexical candidates. It has also been suggested that readers target certain groups of words (e.g., an article and the subsequent noun) as a single region (the word group hypothesis; Radach, 1996). However, Drieghe, Pollatsek, Staub, and Rayner (2008) found that the distribution of fixations on article–noun sequences could be approximated more closely with a model that assumes that readers target each word separately but sometimes miss their target, due to oculomotor error.
In addition to spacing information, there is evidence that unusual letter information in the parafovea can influence where readers move their eyes. Hyönä (1995) found that readers fixate closer to the beginning of words with unusual initial letters. He hypothesized that this was due to the reader’s attention being attracted by the infrequent letter sequences. In a series of experiments, White and Liversedge (2004, 2006a, 2006b) showed that unusual orthographic properties of a word influenced where readers initially fixated in the word (see also Radach, Inhoff, & Heller, 2004). Similarly, readers are less likely to make a second fixation on long words when half of the word is uninformative—that is, not unique to the particular word (Hyönä, Niemi, & Underwood, 1989; Underwood, Bloomfield, & Clews, 1988; Underwood, Clews, & Everatt, 1990; cf. Liversedge & Underwood, 1998). In these experiments, long words were used that were informative at the beginning (i.e., there are only a few words that share the beginning sequence of letters), informative at the end, redundant at the beginning (i.e., there are many words that share the beginning sequence of letters), or redundant at the end of the word. Underwood and colleagues argued that readers can selectively send their eyes to informative parts of words. However, Rayner and Morris (1992) found that readers did not skip uninformative word beginnings of long words, suggesting that they are able to determine which parts of a word are informative only once they fixate it.
The distinction between where and when to move the eyes could be viewed as somewhat artificial, since the two are highly related. For example, the decision to skip a word is both a decision to move past it (e.g., a where decision) and a decision to not spend time fixating it (e.g., a when decision). Since skipping, like fixation time, seems to be closely related to lexical identification of a word, we categorized it as the latter (see below). However, for the most part, the where and the when decision can be considered separate dimensions of the reading process, with a small degree of overlap. That is, visual properties such as word length have the largest effect on landing position, while cognitive/linguistic properties such as word frequency and predictability given prior context have a large effect on how long a word is fixated before moving on (see Rayner, 1998, 2009). We now turn to a discussion of how parafoveal information might facilitate subsequent foveal processing (i.e., via preview benefit) and, thus, influence the decision of when to move the eyes.
The use of parafoveal information to guide when the eyes move
Although it is clear that parafoveal information is limited, as compared with foveal information—as we noted above, in isolation, a word can be identified more quickly in the fovea than in the parafovea (Rayner & Morrison, 1981)—preview benefit effects demonstrate that the importance of parafoveal information to reading goes beyond the decision of where to fixate next. Obviously, these effects require that some parafoveal information obtained on a previous fixation persists during the saccade and is available during the subsequent fixation. What type of information can we assume to persist in this manner? We will review the evidence for parafoveal preprocessing (i.e., preview benefit) separately at each level at which words are represented in reading.
Orthographic processing
As was indicated above, spaces between words are quite easy to detect even at high eccentricities, and spacing information is likely to play a major role in saccade planning—at least in orthographies such as English that indicate word boundaries with spaces. Beyond mere word length, however, the identity of a word critically depends on the letters that make it up. Indeed, phonological, lexical, and semantic access hinges on the activation of letter codes in alphabetic orthographies. To what extent does activation of these letter codes occur for words in the parafovea? First, we address the importance of letter code activation in the fovea and then turn to orthographic processing in the parafovea.
When recognizing foveally presented words in isolation, orthographically related primes facilitate the identification and naming of target words (Evett & Humphreys, 1981). This facilitation is not mainly due to visual overlap, since the primes are presented in lowercase, while the target words are presented in uppercase (e.g., hand–HAND vs. city–HAND). Even nonword primes (e.g., stafe–STATE) provide this benefit, suggesting that this effect occurs on an orthographic (as opposed to lexical) level. Furthermore, this effect does not depend on phonological overlap: File is as good a prime for TILE as touch is for COUCH, even though the prime pairs differ in degree of phonological similarity.
Given that the outline of words can vary considerably depending on the presence or absence of ascending (t, d, f, h, k, l, b) and descending (q, y, p, g, j, p) letters, one might assume that readers routinely use information about the shape of upcoming words to constrain lexical candidates. Indeed, research by Rayner (1975b, 1978c) was initially taken to indicate that there was a preview benefit when word shapes were similar between the preview and target. However, Rayner, McConkie, and Zola (1980) subsequently showed that readers obtained no benefit from a preview that shared the shape of the target word but none of its letters. The benefit was much higher when the preview contained the same initial letters as the target word but did not have the same shape. Other evidence that word shape does not matter comes from a study in which subjects read sentences in alternating case (e.g., wOrD) and the case of every letter changed (e.g., wOrD to WoRd) on each saccade. Despite this massive change of word shape, readers’ performance was equivalent to that in a situation in which the case alternation was constant across saccades (McConkie & Zola, 1979). More recently, Slattery, Angele, and Rayner (2011) replicated this finding and found that, in a display change detection task (where, on each trial, subjects had to indicate whether they saw a display change and then answer a question about the sentence), readers were much better at detecting that a display change had taken place when letter identities changed than when only letter case changed during the saccade. Taken together, these findings imply that word shape plays little role in parafoveal processing and is not integrated across fixations.
There is now considerable evidence that orthographically related parafoveal previews yield a strong preview benefit (Balota, Pollatsek, & Rayner, 1985; Briihl & Inhoff, 1995; Drieghe, Rayner, & Pollatsek, 2005; Inhoff, 1987, 1989a, 1989b, 1990; Inhoff & Tousman, 1990; Lima & Inhoff, 1985; Rayner, 1975b; White, Johnson, Liversedge, & Rayner, 2008). Having the first two or three letters preserved in the preview facilitates processing of the target word. This is most likely due to the reader’s being able to use these letters to initiate the lexical access process. Of course, the beginning letters of a word are closer to the current fixation, but from an experiment by Inhoff (1989b; see also Inhoff, Pollatsek, Posner & Rayner, 1989), it is clear that this is not the cause of the facilitation. In this experiment, words were presented either normally from left to right or in reversed order from right to left (within each word, the letters were printed normally from left to right). Inhoff (1989b) found that readers obtained considerable facilitation when the first three letters of the parafoveal word were available when reading from left to right. More importantly, he also found facilitation reading right to left (where the first three letters of the word are further from fixation). Having the letters at the end of a word preserved does not as consistently yield preview benefit unless the length of a word is less than six letters (Johnson 2007; Johnson, Perea, & Rayner, 2007).
Clearly, letter identity is important, but how important is letter order? Johnson et al. (2007) found that readers obtained more benefit from transposed-letter previews (jugde as a preview for judge) than from previews with replacement letters (jupbe).Footnote 7 The same was true for longer (seven-letter) targets, except when the first or the last letters of the preview were transposed. The transposed letters do not even have to be adjacent; readers obtain more preview benefit from flewor than from flawur for the target word flower. Furthermore, transposed-letter preview benefits are obtained from both transpositions that produce words (clam–calm) and those that produce nonwords (clam–caml; Johnson & Dunne, in press), suggesting that these effects operate at the orthographic, and not the lexical, level.
Finally, experiments by Williams, Perea, Pollatsek, and Rayner (2006) used an identical preview (e.g., sleet), a word orthographic neighbor (sweet), or an orthographically matched nonword (speet) as a preview. In one experiment, low frequency words in orthographic pairs were targets, and high frequency words were previews; in the other experiment, the roles were reversed. When low frequency words were targets, neighbor previews provided as much preview benefit as identical words and greater preview benefit than nonwords; when high frequency words were targets, neighbor words provided no greater preview benefit than did nonwords. Overall, these results indicate that the frequency of a preview influences the extraction of letter information without setting up appreciable competition between previews and targets. This is consistent with the view that early stages of word recognition depend largely on excitation of letter information and competition between lexical candidates becomes important at a later stage. This letter activation can also cause inhibitory effects, as well. If a high frequency orthographic neighbor (blue) is read earlier in a sentence than a target word (blur), reading times are longer than if the target is preceded by a nonneighbor control word (Paterson, Liversedge, & Davis, 2009), because the neighbor will have been fully identified before the target is read. Also, if a word has another word embedded within it (hat in hatch), readers fixate it longer than a frequency matched word without an embedded word (Weingartner, Juhasz, & Rayner, in press).
Phonological processing
The main purpose of orthographic information in alphabetic languages is to visually represent the phonological codes of a word so that they can be used to access its lexical and semantic representations. In foveal single-word recognition, Humphreys, Evett, and Taylor (1982) found that phonological overlap facilitated target identification when the prime was a word (made–MAID), but not when it was a nonword (brane–BRAIN; cf. Perfetti & Bell, 1991). However, this phonological priming effect emerged only at prime durations greater than 45 ms (Ferrand & Grainger, 1992, 1993). This is consistent with the assumption that the onset of phonological processing occurs slightly later than the onset of orthographic processing; research using a fast priming paradigm (Sereno & Rayner, 1992), discussed below, also showed evidence for orthographic codes being activated prior to phonological codes (Lee, Binder, Kim, Pollatsek & Rayner, 1999; Lee, Rayner & Pollatsek, 1999). Despite the later onset of phonological information, it plays an important role in identifying a word. Although there are different models that account for how single words are identified, it is generally accepted that successfully identifying a word is often supported by activating a phonological representation of it. Because of this, phonological information may be more important than orthographic information. In masked priming experiments, subjects showed improved performance when the stimuli were both orthographically and phonologically similar (bribe and TRIBE), but not when they were only orthographically similar (couch and TOUCH; Meyer, Schvaneveldt, & Ruddy, 1974).
Phonological preview benefit effects show that readers can use phonological information about a parafoveal word to help guide processing when the word is subsequently fixated (Ashby & Rayner, 2004; Ashby, Treiman, Kessler, & Rayner, 2006; Chace, Rayner, & Well, 2005; Liu, Inhoff, Ye, & Wu, 2002; Miellet & Sparrow, 2004; Pollatsek, Lesch, Morris, & Rayner, 1992; Rayner, Sereno, Lesch, & Pollatsek, 1995; Sparrow & Miellet, 2002; Tsai, Lee, Tzeng, Hung, & Yen, 2004). Specifically, a parafoveal preview of a phonologically related (homophone) word facilitates processing of the target (Pollatsek et al., 1992; cf. Chace et al., 2005, for a lack of facilitation for less skilled readers). Additionally, there is a preview benefit from homophone and pseudohomophone previews, demonstrated in French (Miellet & Sparrow, 2004), English (Ashby et al., 2006), and even Chinese (Liu et al., 2002; Pollatsek, Tan, & Rayner, 2000; Tsai et al., 2004), which is not an alphabetic language and, therefore, does not always code phonology as transparently through orthography. Henderson et al. (1995) found that previews containing phonologically regular initial trigrams (e.g., button) lead to a larger preview benefit effect than do those containing phonologically irregular initial trigrams (e.g., butane). Parafoveal previews of targets (Ashby & Rayner, 2004) with the first two or three initial letters of CV (consonant–vowel) or CVC (consonant–vowel–consonant) syllable-initial words provide better preview benefits when the syllable structure is similar between the preview and target (i.e., de_πxw as a preview for device) than when it is dissimilar (i.e., ba_πxwx as a preview for balcony).
In the section above, studies using alternating case as a manipulation to test orthographic parafoveal processing suggest that typographical information (e.g., capitalization) does not affect processing. However, in some situations, typographical information obtained parafoveally can be used to guide phonological processing once the word is ultimately fixated. Slattery, Schotter, Berry, and Rayner (2011) conducted a boundary experiment with abbreviations as target words that were presented in normal, mostly lowercase sentences or all-capital sentences. They manipulated whether the target abbreviation (which is always printed in all capitals in English) was an acronym (i.e., pronounced as a word, such as NASA) or an initialism (i.e., pronounced as a series of letter names, such as NCAA). They found that, when abbreviations were presented in mostly lowercase sentences, so that the abbreviations were typographically distinct, readers were biased to process these abbreviations as initialisms. On the other hand, when they were presented in all-capital sentences and were not typographically distinct, readers defaulted to processing these strings as words. These data indicate that, in some ways, typographical information obtained parafoveally can bias phonological processing once a word is fixated.
Morphological processing
Clearly, orthographic and phonological properties of words contribute to the identification of words. Some words, though, are made up of two or more meaning units (morphemes), and readers may be able to split a polymorphemic word into its constituents and process them separately (Taft, 1981; Taft & Forster, 1975, 1976). Even though morphology seems to be important for foveal processing, there is mixed evidence for a parafoveal preview benefit of morphological information in reading in alphabetic languages. While there is no evidence for parafoveal morphological processing in English (Juhasz et al., 2008; Kambe, 2004; Lima, 1987) or Finnish (Bertram & Hyönä, 2007), there is evidence that morphological information is processed parafoveally in Hebrew (Deutsch, Frost, Pelleg, Pollatsek, & Rayner, 2003; Deutsch, Frost, Pollatsek, & Rayner, 2000; 2005). In English, Kambe (2004) found that a nonword preview that shared a prefix (rehsxc) or stem (zvduce) with the target (reduce) provided no facilitation above and beyond a standard orthographic preview benefit, indicating that readers of English do not obtain morphological information in the parafovea (see also Lima, 1987).
Some morphemes can stand alone as words and occur in compound words such as cowboy. In contrast, pseudocompound words appear to be composed of multiple morphemes but are actually monomorphemic (e.g., carpet). The extent to which identifying the constituent morphemes facilitates recognizing the whole word more in compound than in pseudocompound words suggests how much morphological information is processed. Inhoff (1989a) manipulated the preview that readers received for compound words and pseudocompound words. He found that there was no difference in preview benefit between cases where the letters available in the preview corresponded to the morpheme structure (e.g., cowxxx for cowboy) or not (e.g., cowbxx for cowboy), nor was there a difference between the effect of such previews on the preprocessing of compound and pseudocompound words.
Similarly, Juhasz et al. (2008) showed no effect of the morphological relationship between a parafoveal preview and a target that was either a compound word or a monomorphemic word for which some of the letters created a word. Replacing one of the letters with a space, they created previews in which the first letter string either constituted a word (e.g., pop orn or dip oma) or did not (e.g., popc rn or dipl ma). In the compound words, the first word was a constituent of the compound, but in the long monomorphemic word, the first word of the preview was unrelated to the whole word. Juhasz et al. (2008) found no difference in the amount of preview benefit for a constituent of a compound word, as compared with an orthographically contained but semantically unrelated word. These data indicate that morphological information was not processed parafoveally. Similarly, Bertram and Hyönä (2007) found no parafoveal processing of morphological information in Finnish. They manipulated preview of the first three or four letters of compound words with either long or short first constituents so that the manipulated text either comprised the whole constituent or just the first part of it. They found no more benefit if the letters comprised a whole constituent than when they comprised only part of one.
One interesting aspect of compound words is that they vary greatly in terms of how they are composed. In effect, many carry twice the information (i.e., two constituent words) contained within the area of one word. Furthermore, some long compound words may be so long that the second constituent may lie quite far into the parafovea (more so than a noncompound word). Finally, some compound words in English can be written either spaced or unspaced. To what extent do word length and the spaces between words and within spaced compound words affect the extent to which they are processed parafoveally? Hyönä, Bertram, and Pollatsek (2004) conducted a boundary experiment in which the boundary was located between two morphemes constituting an unspaced Finnish compound word. They found large preview benefits on the second morpheme, yet the availability of preview of the second morpheme did not affect fixation times on the first morpheme. This suggests that readers do not process the morphemes in parallel. Interestingly, the preview benefit for the second morpheme was 80 ms—much larger than the usual effect size (30–40 ms) observed for between-word boundary paradigms. Similarly, Juhasz, Pollatsek, Hyönä, Drieghe, and Rayner (2009) found larger-than-normal preview benefits for spaced compound words in English (e.g., tennis ball) and speculated that these effects were mostly due to predictability and transitional probabilities between compound constituents.
Drieghe, Pollatsek, Juhasz, and Rayner (2010) replicated Hyönä et al.’s (2004) finding for compound words but found that readers fixated longer on the first part of a monomorphemic word when preview for its second part was denied. This suggests that the presence of a morpheme boundary causes readers to process the constituents of compound words serially but, when they first encounter a word, they do not know whether it is a monomorphemic word or a compound word. As a consequence, there likely is a very early stage of processing during which all letters in a word can be accessed at the same time. Once readers detect the morpheme boundary, they focus their attention on morphemes separately.
Although English and Finnish readers do not seem to process morphological information parafoveally, some studies have shown evidence for parafoveal morphological processing in Hebrew. For example, Deutsch et al. (2005) conducted a boundary experiment in which a target word had an identical, morphologically related, or orthographically related control word preview. They found larger preview benefit in the morphological preview condition, as compared with the orthographic preview condition. The discrepancy between the Hebrew and English/Finnish studies may be due to differences in the morphological structure of the languages. In Hebrew, all verbs and many nouns and adjectives are marked semantically (by a word root, generally consisting of three consonants) and morphologically (by a word pattern, consisting of vowels or a mixture of vowels and consonants; Deutsch et al., 2003). The word root and the word pattern are interleaved instead of concatenated, so there is no spatial separation between them (i.e., it is not the case that the word root is the beginning of the word and the word pattern is the end or vice versa). Furthermore, in this interleaved structure, the positions of the constituent letters of the word root or the word pattern are not fixed, so the orthographic or phonological structure of the word does not transparently indicate morphology. For this reason, any preview benefit provided in the morphologically related preview condition above and beyond that for the orthographically related preview condition is due to morphology being processed parafoveally, not to a stronger relationship between the morphological preview and the target.
Why might there be differences across languages with respect to parafoveal morphological processing? Multimorphemic Finnish and English words are concatenated instead of interleaved, and words (especially compound words) are generally long: Targets were, on average, more than 12 characters long in Bertram and Hyönä (2007). From the aforementioned data, it seems that a language where morphological constituents need to be separated and processed in order to identify the word may exhibit morphological parafoveal processing, whereas languages where morphological constituents are spatially separated may not. Additionally, long compound words may result in the second constituent’s lying farther away from fixation, in the parafovea or even periphery, as compared with Hebrew, where both constituents may, partly, be accessible in foveal vision. The differences between the structures of the languages may account for why there does not seem to be parafoveal processing of morphological information in Finnish and English, while there is evidence for it in Hebrew.
Chinese may be similar to Hebrew in that morphological structure plays a more important role in word identification than in English or Finnish. In Chinese, the morpheme that a character represents can differ, depending on the word in which it is embedded. Yen et al. (2008) found that preview benefits were larger when the preview and target shared a character that represented the same morpheme, as compared with a condition in which the character was the same (orthographically) but the morpheme it represented differed between the preview word and the target word. Recently, Yang (2010) reported a preview benefit for two-character (i.e., bimorphemic) Chinese compound words. Readers obtained the same amount of preview benefit from a reverse character order preview as from the identical, correct character order preview, as long as the transposition fit into the sentence context. In Chinese, therefore, the characters making up two-character words seem to be processed in parallel by default (note, also, that two characters in Chinese are quite close together and may lie well within the fovea). Similarly, Angele and Rayner (in press) found that, in English, readers obtained a greater preview benefit when the preview presented morphemes in the correct order than when their order was reversed. Additionally, gaze durations were influenced by availability of the preview for both morphemes, and there was even a preview benefit when the previews were in reverse order. These findings suggest that readers can obtain a preview benefit from both constituents of a short compound word, even when the preview does not reflect the correct morpheme order in English.
Lexical processing
What constitutes a lexical property of a word is not completely agreed upon by researchers. The single most studied predictor of lexical processing performance is word frequency. Subjects need less time to identify a briefly presented word that is high frequency than a word that is low frequency (Becker, 1979; Broadbent, 1967; Forster & Chambers, 1973; Howes & Solomon, 1951; Whaley, 1978). Furthermore, naming and lexical decision times are shorter for high frequency words than for low frequency words (Schilling, Rayner, & Chumbley, 1998).
In addition to affecting foveal single-word recognition, there is a wealth of evidence that word frequency has a strong influence on how long a word will be fixated during silent reading (Inhoff, 1984; Inhoff & Rayner, 1986; Just & Carpenter, 1980; Kliegl, Grabner, Rolfs, & Engbert, 2004; Kliegl, Olson, & Davidson, 1982; Rayner, 1977; Rayner, Ashby, Pollatsek, & Reichle, 2004; Rayner & Duffy, 1986; Rayner et al., 1996; Staub, 2011b; Vitu, 1991; White, 2008; for a full review, see Rayner, 2009). Furthermore, ambiguous nouns whose meanings are equally frequent (e.g., palm) are fixated longer in neutral contexts than are biased ambiguous nouns (e.g., port) for which one meaning is more common (Duffy, Morris, & Rayner, 1988; Rayner & Frazier, 1989; Sereno, O’Donnell, & Rayner, 2006). Readers also fixate for less time on words that are predictable from the prior context than on words that are not predictable (Ehrlich & Rayner, 1981; Gollan et al., 2011; Rayner, Ashby, et al., 2004; Rayner & Well, 1996; Staub, 2011a). This brings up an interesting issue regarding whether or not frequency and predictability interact to influence fixation time on a word. For example, the frequency of a word might matter less if it is easily predictable from the sentence context. A number of studies examining this issue have failed to find such an interaction (see Rayner, Ashby, et al., 2004). More recently, Hand, Miellet, O’Donnell, and Sereno (2010) reported that when the launch site of the incoming saccade was taken into account, there was a frequency × predictability interaction. As in prior research, Hand et al. found no interaction when fixation time on the target word was considered. However, they rightly reasoned that launch sites close to the target word (one to three character spaces from the word) should yield better preview information. They found that the predictability effect was larger for low frequency words, but when the saccade was launched from a medium distance (four to six character spaces), the predictability effect was larger for high frequency words. Hand et al. argued for the importance of including launch site in analyses of target word fixation durations. However, Slattery, Staub, and Rayner (in press) examined two large data sets and found no frequency × predictability interaction. Furthermore, they documented a number of problems with the analyses reported by Hand et al.
Since parafoveal lexical processing is necessarily preceded by orthographic, phonological, and morphological processing, differentiating between these influences is quite difficult. In particular, foveal and parafoveal influences are confounded in preview benefit effects, since they can be measured only after a word has been fixated. As a consequence, most of the evidence for lexical parafoveal processing comes from skipping and PoF effects. Because these effects are qualitatively different from the preview benefit effects discussed so far and evidence for or against them comes from both experimental manipulations and corpus analyses, we will discuss them in their own sections below.
Semantic processing
Ultimately, the goal of using orthographic, phonological, and morphological information to access a word’s lexical representation is to activate the word’s meaning. Priming paradigms have been used widely to investigate semantic processing in the fovea. Semantically related primes (nurse) facilitate the recognition of a target word (doctor) more than do unrelated words (Meyer & Schvaneveldt, 1971; Neely, 1977). As was mentioned above, the fast priming technique developed by Sereno and Rayner (1992) allowed researchers to manipulate the duration of a prime in foveal vision during sentence reading (see Fig. 6). Sereno and Rayner found a significant semantic priming effect only at short durations and hypothesized that this was due to related primes disrupting processing of the target word more at longer prime durations. Because activation of a node in a semantic network can inhibit activation of competitors, longer durations may activate the prime so much that activation of the target may be inhibited. At shorter durations, however, the prime may be only partially activated, leading to facilitation via spreading activation.

Example of the fast priming paradigm. When the subject’s eyes cross an invisible boundary before a critical word in the sentence, it changes from random letters to the prime. After 30–50 ms, the prime changes to the target
In gaze-contingent naming, when parafoveal processing occurs in the absence of concurrent foveal processing, as was noted above, there is little evidence for a semantic preview benefit (Rayner, McConkie, & Zola, 1980). In reading, there is some evidence corroborating this lack of semantic information being obtained from the parafovea, although there is disagreement between results in different languages. Most studies of alphabetic languages (such as English, Finnish, and Spanish) have not yielded evidence for semantic preview benefits (Altarriba, Kambe, Pollatsek, & Rayner, 2001; Hyönä & Häikiö, 2005; Rayner, Balota, & Pollatsek, 1986; White, Bertram, & Hyönä, 2008); however, such an effect has been reported for readers of German (Hohenstein, Laubrock, & Kliegl, 2010). Additionally, readers of character-based languages such as Chinese may obtain semantic information parafoveally (Pollatsek et al., 2000; Yan, Richter, Shu, & Kliegl, 2009; cf. Yang, Wang, Xu, & Rayner, 2009).
In English, Rayner et al. (1986), in a study using the boundary paradigm, found that a target word (song) did not yield a preview benefit from a semantically related word (tune), as compared with an unrelated word (door). However, they found that readers did gain a preview benefit from an orthographically similar nonword (sorp). When a standard priming experiment (in which the target followed the prime in foveal vision) was conducted using the same target words, semantic priming was obtained. Similar results suggesting no semantic preview benefit were found in a study with Spanish–English bilinguals (Altarriba et al., 2001). Bilinguals provide a good test for the semantic preview benefit because one can systematically vary the effects of orthographic similarity and semantic similarity between the bilingual’s two languages (although see Hohenstein et al., 2010, for a different view). Altarriba et al. had Spanish–English bilinguals read English sentences in a boundary experiment. The previews were identical to the target (e.g., sweet–sweet), cognates of the target (words that are similar orthographically and semantically between the two languages; e.g., crema–cream), pseudocognates of the target (words that are orthographically similar but semantically unrelated across languages; e.g., grasa–grass), noncognate translations of the target (words that are semantically similar but orthographically different across languages; e.g., dulce–sweet), or a control word that was both orthographically and semantically unrelated (e.g., torre–cream). Altarriba et al. reported that the identical previews, cognates, and pseudocognates provided preview benefit but the noncognate translation words did not. These data provide evidence that preview benefit is due to orthographic–phonological processing, not semantic processing.
Hyönä and Häikiö (2005) conducted a boundary experiment in Finnish in which the previews were identical to the target, orthographically similar emotional words (sex or threat related), or orthographically similar but semantically unrelated and emotionally neutral words. They found that emotional previews were no different from neutral previews, both for fixation measures on the target word when it was ultimately fixated and for fixations on the word prior to the target. They argued that if semantic information were obtained parafoveally, the eyes would move to the emotional word sooner. But they did not find a difference in the gaze on the prior word, indicating that semantic information was not obtained from the emotional word prior to fixation.
One reason there is, thus far, little evidence for parafoveal semantic processing is that it may be that there are trade-offs between orthographic and semantic information that nullify potential semantic preview benefit effects. Thus, while a semantically related word may potentially yield a preview benefit, any such advantage will be washed out by the fact that the preview and target words would be orthographically very different. Another reason could be that it is not advantageous to process the meanings of words out of order. However, in compound words, processing of both constituents simultaneously may not be disadvantageous, and we may actually see parafoveal processing of the second constituent while the eyes are on the first. To test this, White, Bertram, & Hyönä (2008) conducted a boundary experiment in which the second constituent of compound words in Finnish (which tend to be long) was the target. Therefore, the word (vaniljakastike–vanilla sauce) had a semantically related preview (e.g., vaniljakasinappi–vanilla mustard), a semantically unrelated preview (e.g., vaniljarovasti–vanilla priest), or a nonword preview (e.g., vaniljaseoklii–vanilla nonword). They found no difference in reading measures on both the first and second constituents when the preview was semantically related, as compared with semantically unrelated. However, when the whole compound word was considered, the semantically related preview condition resulted in shorter go-past times (the time from fixating the word for the first time until leaving it to the right, including regressions), indicating that some amount of semantic information can be obtained within a word when the word is a long compound. Due to the nature of the whole-word measure, it is not clear whether this qualifies as a preview benefit or a PoF effect.
All of the studies above that showed no evidence for parafoveal processing of semantic information across word boundaries were conducted in alphabetic languages. Yan et al. (2009) found different results when they conducted a boundary experiment in Chinese. The previews were identical, orthographically similar, phonologically similar, semantically similar, and unrelated controls. They found parafoveal preview benefits of semantically related words, indicating that the subjects had obtained semantic information parafoveally. As Yan et al. (2009) noted, the words in their study were highly constrained, and the conclusions may not be generalizable. In the study, the previews were the first character in a two-character compound word, and the identical condition was the only condition in which the preview character formed a real word with the following character. Furthermore, Yan et al. (2009) selected only noncompound characters in order to avoid sublexical/radical activation. Both of these restrictions exclude characters that would otherwise be commonly encountered in normal Chinese reading.Footnote 8 Yan et al. (2009) suggested that Chinese readers obtain a semantic preview benefit when readers of alphabetic languages seem not to because there is a stronger relationship between orthography and semantics in Chinese than in alphabetic languages, where the route from orthography to semantics is mediated by phonology. Indeed, the effects of phonology, which are quite strong in alphabetic languages, have been reported to be comparatively smaller in Chinese (Feng, Miller, Shu, & Zhang, 2001), although, as was noted above, phonological preview benefits have been observed in Chinese. Furthermore, as was mentioned before, because words in Chinese are physically smaller than those in alphabetic languages, the upcoming word in Chinese may actually fall in the fovea, leading to faster activation of semantics.
Recently, Hohenstein et al. (2010) reported semantic preview benefits in German, using a variation of the fast priming technique (Sereno & Rayner, 1992) to make a parafoveal prime available during the first 35, 80, or 125 ms of the fixation on the previous word. After this time, the prime was replaced by the target word. Hohenstein et al. found a significant effect of semantic relatedness of the prime in the 125-ms condition, but not in the shorter conditions (unless the prime was in boldface, increasing its saliency). Despite the fact that there were noticeable display changes on every trial, the study can be considered the strongest evidence for the existence of semantic preview benefit effects so far. Hohenstein et al. argued that the lack of conclusive evidence for such effects in earlier studies was due to disruption caused by parafoveal primes that were presented for more than 125 ms.Footnote 9 In contrast, Yen, Radach, Tzeng, Hung, and Tsai (2009), in a similar experiment in Chinese, using a preview mask for the first 140 ms of fixation on the pretarget word or a mask from 140 ms after pretarget fixation until the following saccade, found a preview benefit in both early and late preview conditions. However, it is not clear whether these effects are semantic or orthographic in nature.
In summary, there is now some evidence that readers can obtain semantic information from the parafovea, but the conditions under which these effects appear and whether they are limited to specific languages, writing systems, or experimental manipulations are still unclear; further research is obviously needed.
Interactions between foveal and parafoveal processing
As the preceding review suggests, there is a lot of information that can be obtained in the parafovea while foveal processing is still ongoing. Therefore, the reading process is quite complex, and it is necessary to consider how these two types of processing—foveal and parafoveal—may interact with each other.
The effect of foveal load on parafoveal processing
Henderson and Ferreira (1990; see also Kennison & Clifton, 1995) provided important evidence that parafoveal processing is affected by concurrent foveal processing (e.g., foveal processing load—word frequency). A low frequency foveal word effectively eliminated any benefit from the preview of the upcoming word. The same was true when the foveal word was difficult to integrate into the sentence structure (e.g., in a garden-path sentence). White, Rayner, and Liversedge (2005a) showed that these effects depended on the extent to which the reader noticed the display change. The results held for readers who did not notice the display change, but not for those who were aware of the display changes, possibly because noticing the display change disrupted processing (see Slattery, Angele, & Rayner, 2011). Furthermore, foveal load effects might extend over more than one word, because preview benefit is diminished when preview for a preceding nonadjacent word is denied (Wang, Inhoff, & Radach, 2009; see the discussion of n + 2 preview benefit effects, below).
Reingold and Rayner (2006) investigated the extent to which the type of processing difficulty modulates these effects. They found that, when the foveal word (word n) was presented with reduced contrast, only fixation times on word n were affected. However, when the foveal word was presented in alternating case, fixation times on both word n and word n + 1 were longer than in the control condition. Reingold and Rayner argued that this dissociation corresponds to the distinction between an early and late stage of word identification. These findings clearly demonstrate that the amount of information that readers obtain from the parafovea is dependent on current foveal processing.
Parafoveal processing depends on attention
The findings above suggest that parafoveal processing depends on the amount of resources left over from requisite foveal processing. Additionally, as was described above, less information is obtained from the parafovea than from the fovea, due to decreasing acuity. How can we truly distinguish between restrictions on parafoveal processing that are due to acuity and those that are due to attention? Miellet, O’Donnell, and Sereno (2009) used a clever variation of the moving-window paradigm that involved magnifying each letter by its eccentricity to compensate for the decline in visual acuity at higher eccentricities. They still found a window size of 14–15 letter spaces to the right of fixation (i.e., not different from the nonmagnified control condition), demonstrating that attention, not visual acuity, determines how much information can be extracted from the parafovea (see also Rayner, 1975a). The asymmetry of the perceptual span, as well as the findings noted above that the asymmetry is reversed for Hebrew readers, also reinforces the view that attention is the primary determinant of the perceptual span, as does the finding that in vertical reading of Japanese, the span is asymmetric in the direction of reading (Osaka, 2003).
In the previous sections, we reviewed evidence for parafoveal processing that is well established and not controversial (aside from semantic preview benefits). The following sections address aspects of parafoveal processing that are still fairly contentious and actively debated in the field of eye movements during reading. These effects include word skipping, PoF effects, and word n + 2 preview benefit effects.
Skipping and PoF effects in experimental manipulations and corpus analyses
As was mentioned above, it is quite difficult to study parafoveal processing of the lexical representations of words via preview benefit effects. Therefore, we have reserved the discussion of lexical parafoveal processing for a separate section. This section is separated from the others because it regards qualitatively different types of effects and how they provide evidence for and against parafoveal lexical (and syntactic/semantic) processing. It is important to note that these two effects (skipping and PoF effects) can be observed in both corpus analyses and experimental manipulations, although much of the evidence for PoF effects comes from corpus analyses only.
Lexical identification and word skipping
As was noted above, one indication that readers can identify parafoveal words to some extent is the phenomenon of word skipping. While some word skipping can be explained by mislocated fixations (i.e., the saccade intended for the word overshoots and lands on the next word), there are some indications that word skipping is, at least partly, influenced by parafoveal processing (for a review, see Brysbaert et al., 2005). For example, three-letter function (closed-class) words such as articles or prepositions are more likely to be skipped than three-letter content (open-class) words such as verbs (O’Regan, 1979, 1980), and these effects are present even when the closed-class words are not predictable (Drieghe, Pollatsek, et al., 2008; Gautier, O’Regan, & Le Gargasson, 2000). As we will document in more detail below, contextual constraint has a strong influence on skipping. However, word frequency also has an effect (although not as strong as predictability) in that readers are more likely to skip high than low frequency words, even when length is controlled (Gollan et al., 2011; Rayner et al., 1996). Also, the number of syllables a word contains influences skipping; readers are more likely to skip a monosyllabic word than a disyllabic word with length controlled (Fitzsimmons & Drieghe, 2011).
While skipping effects are quite likely caused by lexical processing, it is also possible that orthographic information about an upcoming article may automatically trigger skipping (Saint-Aubin & Klein, 2001). This would seem an effective strategy, since fixating an article in English is not likely to provide much information about the sentence, other than confirming that the word is, indeed, the (highly predictable) article. Conversely, in languages such as German or French, where articles encode more information (e.g., grammatical number and gender), fixating them might be more beneficial. Angele and Rayner (2010) tested whether skipping articles in English is automatically triggered by orthographic information. They found that readers were likely to skip a three-letter verb for which the preview was the even when the preceding sentence context did not allow for an article in that position. These data suggest that orthographic, not syntactic, processing has a strong influence on skipping articles (even though sentence context affects skipping rates for open-class words).
Contextual effects
Parafoveal processing is not the only influence on word skipping, though; contextual constraint also has a strong effect. Highly predictable words are skipped more often than less predictable words (Balota et al., 1985; Ehrlich & Rayner, 1981; Gollan et al., 2011; Hyönä, 1993; O’Regan, 1979; Rayner, Slattery, et al., 2011; Rayner & Well, 1996; Vitu, 1991; for a review, see Brysbaert et al., 2005), except when the word is low frequency (Rayner, Ashby, et al., 2004) or a nonword (Drieghe, Rayner, & Pollatsek, 2005), suggesting that, at least before word skipping, readers can process parafoveal words beyond the letter level. Alternatively (or in addition), word skipping could be caused by readers’ anticipating or guessing what the upcoming word might be and confirming that guess with orthographic input. Thus far, these two possibilities have not been teased apart and are still of great general interest. The effects of predictability (or contextual constraint) go beyond just word skipping; it can also affect how long a word is fixated. A number of studies have shown that, when words are not skipped, fixation times on words are influenced by the predictability of a word, given its preceding context (Balota et al., 1985; Carroll & Slowiaczek, 1986; Duffy & Rayner, 1990; Ehrlich & Rayner, 1981; Inhoff, 1984; Kliegl et al., 2004; Rayner et al., 2001; Schustack, Ehrlich, & Rayner, 1987; Slattery, 2009; Zola, 1984). Furthermore, transitional probability (i.e., the conditional probability of a word, given the preceding word) has been reported to be a significant predictor of fixation times in both corpus analyses (McDonald & Shillcock, 2003b) and experimental manipulations (McDonald & Shillcock, 2003a). However, Frisson, Rayner, and Pickering (2005) argued that this effect is, in reality, based on predictability given the entire preceding context. The exact mechanism through which contextual constraint works and which level of representation it corresponds to are not clearly agreed upon. It is most likely, though, that contextual constraint operates by narrowing the set of lexical candidates. Therefore, while not a standard lexical effect, it is undoubtedly related to lexical processing in some way.
Orthographic parafoveal-on-foveal effects
As was discussed in the previous section on word skipping effects, the presence of unusual letters in the parafovea clearly has an effect on ongoing processing. This was demonstrated by Pynte, Kennedy, and Ducrot (2004), who conducted a gaze-contingent boundary experiment where word previews embedded in sentences could contain several different kinds of typographical errors, while the actual target words were always spelled correctly. They found shorter fixation times when the parafovea contained a typographical error, as well as a lower skipping rate of the short pretarget word, suggesting that readers slow down and make shorter saccades in the presence of parafoveal typographical errors. In an additional experiment, Pynte et al. found that this effect was due to the unusual initial characters of the preview. A similar result was reported by White (2008), who found that orthographic familiarity of a target word affected fixation duration on the preceding word. In general, it may be that unusual initial trigrams of parafoveal words (the initial trigram informativeness) can influence not only the probability that it is skipped (as described above), but also fixation times on the preceding word. However, not all of the findings are consistent: While some studies reported that informative parafoveal trigrams led to shorter fixations on the foveal word (Kennedy, 1998, 2000; Pynte et al., 2004), others found that an informative parafoveal trigram led to longer fixations on the foveal word (Kennedy, 2008; Kennedy & Pynte, 2005; Underwood, Binns, & Walker, 2000).
In summary, orthographic PoF effects are consistently found both in experimental designs and in corpus analyses. They were found in the first gaze-contingent boundary experiment involving random-letter masks by Rayner (1975b) and continue to be found in such experiments. There is evidence for PoF effects in boundary experiments when the parafoveal word was masked (Blanchard et al., 1989) or in all-capital letters (Inhoff, Starr, & Shindler, 2000; cf. Slattery et al., 2011) or when it contained random letter strings (e.g., qvtcqp; Angele, Slattery, Yang, Kliegl, & Rayner, 2008; Inhoff, Starr, & Shindler 2000; Rayner, 1975b) and orthographically irregular nonwords, but not regular pseudowords (Starr & Inhoff, 2004). Thus, orthographic PoF effects most likely reflect disruption caused by unusual letter combinations in the parafovea, rather than lexical word identification (as the term “informativeness” would imply). The consistency with which they are found indicates that readers are quite sensitive to unusual orthography and can detect such problems well ahead of fixating a misspelled word.
Lexical parafoveal-on-foveal effects
While the existence of orthographic PoF effects is largely undisputed, much research has been focused on whether lexical (or even semantic) properties of a parafoveal word can influence ongoing processing as well (for in-depth summaries, see Drieghe, 2011; Hyönä, 2011). Many of the studies that have reported finding lexical PoF effects have not used reading tasks but, rather, tasks that approximate, but are not, reading (Kennedy, 1998, 2000; Kennedy, Pynte, & Ducrot, 2002; Schad, Nuthmann, & Engbert, 2010; Schroyens, Vitu, Brysbaert & d'Ydewalle, 1999; Vitu, Brysbasert, & Lancelin, 2004). Bradshaw (1974) reported semantic PoF effects in a task in which subjects identified a briefly presented ambiguous foveal word (e.g., palm) that was surrounded by two other parafoveal words, one of which was semantically related to one of the meanings of the foveal word (see also Abad, Noguera, & Ortells, 2003; Ortells, Abad, Noguera, & Lupiáñez, 2001; Ortells & Tudela, 1996). However, Inhoff and Rayner (1980; Inhoff, 1982) were unable to replicate these effects when they controlled for fixation position. This may be because, in Bradshaw’s and other studies, subjects may have moved their eyes to the parafoveal word and, therefore, processed it foveally.
Most positive evidence for lexical PoF effects comes from corpus analyses, which, as was mentioned above, have problems ensuring precise experimental control. Kennedy and Pynte (2005; see also Kennedy, 1998; Kliegl, 2007; Kliegl et al., 2006) used corpus analyses that suggested that fixations near the end of a long foveal word exhibited lexical PoF effects. But alternative explanations for such PoF effects have been offered. Rayner et al. (2007) argued that lexical PoF effects, given their small effect size and the fact that they are stronger for fixations on the last few letters of a word, could be due to mislocated fixations. Due to saccadic range error (Kapoula, 1985), long saccades often tend to undershoot—fall short of their targets (McConkie, Kerr, Reddix, & Zola, 1988). It is therefore possible that lexical PoF effects are due to readers’ intending to skip a word but undershooting their target and, instead, landing on the word before it. In this case, the fixation during which the lexical PoF effects are observed may reflect processing of the upcoming word that was the actual saccade target. Drieghe, Rayner, and Pollatsek (2008, cf. Kennedy, 2008) showed that orthographic PoF effects do not depend on the frequency of the foveal word. Furthermore, they are more likely to appear on fixations near the end of the foveal word and on those that occur after a long saccade, suggesting failed skipping.
In contrast to corpus analyses that claim positive evidence for lexical PoF effects, studies employing experimental manipulations generally have not shown support (Angele & Rayner, 2011; Angele et al., 2008; Carpenter & Just, 1983; Henderson & Ferreira, 1993; Inhoff, Starr, & Shindler, 2000; Rayner et al., 1998; Rayner, Juhasz, & Brown, 2007), with the exception of some studies in which the foveal word was constrained to be a short word (Glover, Vorstius, & Radach, in press; Kliegl, Risse, & Laubrock, 2007; Risse & Kliegl, 2011). Inhoff, Starr, and Shindler (2000) conducted a boundary experiment in which the preview of a target word (light) was identical, an uppercase version (LIGHT), an orthographically illegal letter string (qvtqp), or an unrelated word that did not make sense in the sentence context (smoke). Fixation measures on the preceding word (i.e., PoF effects) were inflated in the uppercase condition and the illegal letter string condition, but not in the identical or unrelated word condition, indicating the PoF effects are solely orthographic, and not lexical or semantic in nature (but see Inhoff, Radach, Starr, & Greenberg, 2000).
Evidence that contextual information can induce PoF effects is also tenuous, coming mostly from nonreading tasks (Kennedy, Murray, & Boissiere, 2004; Murray, 1998; Murray & Rowan, 1998). In a same/different sentence-matching task, Murray and Rowan found PoF effects of an implausible relationship between the subject and verb of a sentence (e.g., The uranium smacked the child vs. The savages smacked the child). Kennedy et al. (2004) replicated this effect and showed that it did not occur when the verb was masked, suggesting that it was, in fact, due to parafoveal processing of the word. However, these studies involved a rather unusual task that may not be entirely comparable to normal reading (Rayner et al., 2003).
In reading tasks using experimental manipulations, evidence for PoF effects of plausibility have not been found. Rayner, Warren, Juhasz, and Liversedge (2004) had subjects read sentences that were plausible, implausible (used an axe to chop the carrots), or anomalous (used a pump to inflate the carrots). Although first-pass reading times on carrots were quite long in the implausible and anomalous conditions, there was little clear evidence for PoF effects. Staub, Rayner, Pollatsek, Hyönä, and Majewski (2007) had subjects read sentences with noun–noun compounds in which the first noun was either a plausible (the new principal visited the cafeteria . . .) or implausible (the new principal talked to the cafeteria . . .) continuation of the sentence before getting to the following word (manager). Before a reader processes the word manager, cafeteria is likely to be interpreted as the object of the verbs visited or talked. If syntactic information were obtained from the parafoveal word, reading times should not be longer in the implausible condition than in the plausible condition, because the first noun would be disambiguated as the modifier in the noun–noun compound (i.e., there should be a PoF effect of plausibility). Staub et al. (2007) found longer reading times in first-pass measures on the modifier noun in the compound, indicating that there was no use of semantic or syntactic information from the parafoveal word. It is important to note, however, that the first noun in the compound was not a short word (mean length was over six characters), and this meant that the majority of the parafoveal word (the disambiguating word in the noun–noun compound) may have been too far into the parafovea to be well identified. Both the Rayner et al. (2004) and the Staub et al. (2007) studies are consistent with the view that readers generally do not obtain semantic information from the words to the right of fixation (except in certain conditions in which the fixated word and/or the word to the right of fixation is relatively short).
There is a possibility that PoF effects may be more prevalent in nonalphabetic languages such as Chinese (which, as was noted above, allows for more text to fit into the fovea than do alphabetic languages). Yang et al. (2009) had subjects read Chinese sentences in a boundary experiment. When the boundary was placed between the first and second characters in a two-character word, there were apparent lexical PoF effects. However, when the preboundary character constituted a word on its own (i.e., when the gaze-contingent boundary was located at a word boundary), there was no lexical PoF effect. Therefore, from these data and the Inhoff, Starr, & Shindler (2000) data, it is unclear whether these PoF effects are truly lexical or orthographic. Thus, the only PoF effects that are consistently found are those that are orthographically based. There is evidence for PoF effects when the parafoveal word was masked (Blanchard et al., 1989) or in all-capital letters (Inhoff, Starr, & Shindler 2000; cf. Slattery et al., 2011) or when it contained random letter strings (e.g., qvtcqp; Angele et al., 2008; Inhoff, Starr, & Shindler 2000; Rayner, 1975b) and orthographically irregular nonwords, but not regular pseudowords (Starr & Inhoff, 2004).
In summary, there is currently no conclusive evidence that lexical or syntactic/semantic information from the parafovea is available before readers have finished processing a foveal word. There is a great deal of evidence that PoF effects are driven by orthography, and not lexical status, syntactic role, or meaning. However, the consistency with which apparent lexical PoF effects are found in corpus analyses is striking and does warrant further study. Drieghe (2011) pointed out that there are a number of potential problems with interpreting such results. First, as was mentioned above, mislocated fixations may explain some of the findings of PoF effects. Second, eyetracker machine error and poor calibration may cause fixations on a word to be erroneously assigned to the preceding word, creating an apparent PoF effect. This is a concern especially in corpus analyses, since in many cases, recalibrations are performed less frequently in such studies than in experimental manipulations. Third, binocular disparity (Kirkby, Webster, Blythe, & Liversedge, 2008) may lead to situations where the right eye is fixating on one word while the left eye is fixating on the subsequent word. Since, in most studies, only the gaze position of the right eye is recorded, this could again lead to apparent PoF effects. Finally, the correlational nature of corpus studies may lead to confounds; in effect, it may be impossible to account for all the systematic influences on fixation times on a particular word within a statistical model. This may limit the interpretability of effects without replication in an experimental study.
A recent study by Angele, Slattery, Chaloukian, Schotter, and Rayner (2011) made an attempt to test this. Angele et al. used a linear mixed effect model and found an effect of the frequency of word n + 1 on fixation times on word n—an apparent lexical PoF effect—under a normal reading situation. However, they also found an effect of word n + 1 frequency on fixation times even when the two words to the right of fixation were masked (and hence, readers could not have processed those words). Thus, PoF effects that have been attributed to lexical identification of the upcoming word may actually be due to an unrelated effect that is currently being misattributed to lexical processing. One possibility is that the preceding sentence context contains some cues as to the processing difficulty of the upcoming words (which would likely be correlated with n + 1 word frequency). Such an effect could be subtle enough to become apparent only in corpus analyses, especially since in experimental manipulations, great care is taken to keep the context preceding a target word as similar between conditions.
Preview benefit from word n + 2
If, as Briihl and Inhoff (1995) found, readers can use information from all the letters in a parafoveal word, there is the possibility that they might also be able to obtain letter information from words further to the right in the parafovea, provided it is within the perceptual span. To investigate this, Rayner, Juhasz, and Brown (2007) performed a boundary experiment in which the boundary was located in front of the word to the left of the target, instead of in front of the target itself. They found no effects of preview for the second word to the right of fixation (word n + 2). Furthermore, McDonald (2006) found that preview of the parafoveal (n + 1) word is obtained only when that word is the target of the current saccade with a boundary experiment in which the boundary was either at the end of the pretarget word or in the middle of it. The pretarget word was long enough (9–10 letters) that there was a high probability that it was refixated, allowing McDonald (2006) to compare preview benefit when the saccade landed on the target word with when it was a refixation on the preceding word. He found a preview benefit only when the saccade that triggered the display change landed on the target word (e.g., when attention was shifted to it because a saccade was programmed to it). McDonald (2005) also demonstrated that there was no cumulative preview benefit across successive saccades and that the degree of preview benefit was inversely related to the distance of the prior fixation from the target. These data further contradict the possibility that information is obtained from words beyond the currently- and next-to-be-fixated words.
However, other studies have reported preview effects of word n + 2. Although Kliegl et al. (2007) did not find an n + 2 preview benefit effect on the word itself, they observed an effect of n + 2 preview availability on gaze durations on the word before it (word n + 1; a delayed PoF effect), which they interpreted as evidence of parafoveal preprocessing (see also Risse & Kliegl, 2011). These findings might, however, be explained by mislocated fixations (Drieghe, Rayner, & Pollatsek, 2008; Nuthmann et al., 2005; see the discussion above), where fixation times on n + 1 actually reflect processing of word n + 2. In order to test this hypothesis, Angele et al. (2008) conducted a boundary experiment in which they manipulated the availability of preview for word n + 1 and word n + 2 orthogonally. Since readers should be unlikely to skip word n + 1 if they did not receive a valid preview of it, any effect of n + 2 should be independent of mislocated fixations. Thus, an n + 2 preview effect should be apparent in the comparison between the condition in which preview for n + 1 was denied but preview for n + 2 was available and the condition in which preview for both words was denied. Importantly, no such effect was found, nor was there an n + 2 preview benefit when preview for n + 1 had been available (cf. Glover et al., in press). One explanation for the discrepancy between these studies may be in the length of the words used. While the n + 1 words in studies that provide positive evidence (Glover et al., in press; Kliegl et al., 2007) exclusively used three-letter words, other studies (Angele et al., 2008) used n + 1 words that were, on average, six letters long. However, in a more recent study, Angele and Rayner (2011) found that there was no evidence of effects of parafoveal n + 2 even when n + 1 word length was short and word n was manipulated to be of either high or low frequency.
Given the argument above, it might be more likely to observe a preview benefit of n + 2 in Chinese, because words subtend a smaller physical space. Wang et al. (2009) conducted a boundary change study in Chinese where words n and/or n + 2 were masked. They found that the n + 2 preview benefit was diminished when word n was masked. Similarly, Yan, Kliegl, Shu, Pan, and Zhou (2010) manipulated the preview of word n + 2 (masked vs. unmasked) while the eyes were on word n and manipulated the frequency of the intervening word (n + 1). They found a preview benefit of word n + 2 only when word n + 1 was high in frequency (easy to process).
In summary, evidence for processing multiple words simultaneously is mixed at best: Under some circumstances, a preview benefit of word n + 2 has been observed; however, the conditions under which this is possible may be very constrained. It is important to keep in mind that any such effects, if they exist, are likely to be quite small, which makes their detection difficult and limits their impact on normal reading.
The role of parafoveal processing in models of eye movements during reading
In the preceding sections, we summarized what is known about the foveal and parafoveal processing of words. While subjects are clearly able to determine the identity, pronunciation, and meaning of single words that are presented parafoveally, this is not always the case when there is information to be processed foveally at the same time, as in reading. While results from reading research are critical in order to provide evidence for how parafoveal information and foveal information interact, models of eye movements during reading are particularly illustrative for a better understanding of the nature of this interaction. The two most prominent models are the E-Z Reader (Rayner, Li, & Pollatsek, 2007; Reichle, Liversedge, Pollatsek, & Rayner, 2009; Reichle, Pollatsek, Fisher, & Rayner, 1998; Reichle, Pollatsek, & Rayner, 2006, 2007; Reichle, Warren, & McConnell, 2009) and SWIFT (Engbert, Longtin, & Kliegl, 2002; Engbert, Nuthmann, Richter, & Kliegl, 2005) models.Footnote 10 They have been highly successful in the sense that they have generated a considerable amount of research to test aspects of each model (for examples, see Inhoff et al., 2005; Inhoff, Greenberg, Solomon, & Wang, 2009; Inhoff, Radach, & Eiter, 2006; Inhoff, Starr, & Shindler 2000; Miellet, Sparrow, & Sereno, 2007; Pollatsek, Reichle, & Rayner, 2006a, 2006b; Rayner et al., 2007; Reingold & Rayner, 2006; Reingold, Yang, & Rayner, 2010; Risse & Kliegl, 2011; Warren, White, & Reichle, 2009) and some counterintuitive findings have been explained (Pollatsek, Juhasz, Reichle, Machacek, & Rayner, 2008) by appealing to aspects of a model. It is probably fair to say that more research has been generated to test predictions of E-Z Reader than SWIFT, perhaps due to the fact that the model is highly transparent.
The E-Z reader model
The E-Z Reader model posits that eye movements during reading are determined by two phases of word recognition. The first stage, called L1, is a cursory processing of the word. Once this stage is completed, a more thorough stage of processing, called L2, commences. Once L2 is completed, attention shifts to the next word, provided that a saccade has not yet been triggered. This attention shift is what accounts for word skipping and parafoveal preview benefits. L1 and L2 may not be two distinct stages but, rather, may be two different thresholds of identification of the word (Rayner, Li, & Pollatsek 2007). The lexical identification stages are preceded by a stage of visual analysis (V), which occurs in parallel over all the words within the perceptual span. This stage accounts for why odd spacing manipulations or inappropriate word length information in boundary experiments cause disruption in processing. Another important aspect of the model is that processing depends on eccentricity from fixation. For this reason, foveal words are processed more quickly than parafoveal words, gaze duration is influenced by landing position on the word, and (controlling for other factors) short words will be processed faster than long words.
In concert with the lexical processing stages, the model posits two saccade-programming stages, M1 and M2. M1 is a labile stage, which means that the saccade that is programmed during this stage can be canceled. The second stage, M2, follows M1 and triggers the saccade when it finishes and is a nonlabile stage; it cannot be canceled. The system probabilistically programs a refixation of the foveal word once the eyes land on it; the probability that this happens is determined by the word’s length. When L1 on word n ends, a new saccade to word n + 1 is programmed, canceling the refixation program if it has previously been initiated and is still in stage M1. This aspect of the model accounts for the fact that longer words that are harder to identify (i.e., have a long L1 stage) are refixated more often. If stage L2 on word n terminates before the saccade to word n + 1 is executed, word n + 1 is preprocessed parafoveally (that is, E-Z Reader predicts parafoveal preprocessing whenever L2 < M1 + M2). If, during preprocessing, stage L1 on word n + 1 is completed before the labile stage M1 for the saccade to word n + 1 ends, this program will be canceled, and a new saccade to word n + 2 will be programmed—in which case word n + 1 will be skipped.
Because the saccade has already begun to be programmed when attention shifts, processing of the parafoveal word should not influence fixation times on the foveal word. Therefore, it has been argued that the E-Z Reader model cannot explain PoF effects (e.g., Risse, Engbert, & Kliegl, 2008). However, there are certain circumstances in which an unusual letter string in the parafovea can lead to longer fixation durations on the foveal word due to mislocated fixations, which would be compatible with E-Z Reader (Drieghe, Rayner, & Pollatsek, 2008; see above). The E-Z Reader model does predict that word n + 2 can be processed in one specific case. Attention shifts in E-Z Reader are based on the completion of L2, and saccade executions are based on the completion of M2. Therefore, if L2 is completed on word n and both L1 and L2 are completed on word n + 1 before M2 has finished, attention will have shifted to word n + 2, and n + 2 can be preprocessed, leading to an n + 2 preview benefit effect (diminished by poorer visual acuity at further eccentricities). However, in this case, the completion of L1 on word n + 1 will trigger the programming of a saccade to n + 2 (provided that that saccade program is still in the labile M1 stage), skipping n + 1. Indeed, Angele and Rayner (2011) found an n + 2 preview effect only after word n + 1 had been skipped. Additionally, there is the possibility that the intended skipping saccade falls short of its target due to saccadic range error and lands on word n + 1 instead. In this case, word n + 1 would show effects of word n + 2 preview, as was found by Kliegl et al. (2007).
The SWIFT model
The SWIFT model is based on dynamic field theory; simplistically put, the model assumes that each word in a sentence has a level of activation that simultaneously represents the degree to which it is identified and its saliency. More precisely, saccade targets are selected in a biased-random fashion, so that a word’s level of activation determines the probability that it will be targeted. Because the activation level of every word in the sentence is updated on every iteration of the model, it is implied that processing is spatially distributed and, therefore, happens in parallel over several words. Like E-Z Reader, SWIFT assumes that, during word identification, a preprocessing stage (implemented as the word’s activation rising from zero to a maximum activation level that is determined by the word’s frequency and predictability) is followed by a lexical completion stage (implemented as activation falling from the maximum back to zero). Importantly, this means that once a word is identified, it is no longer a possible saccade target.
As was stated above, SWIFT posits that, after a random time interval, a saccade is planned to one of the words with nonzero activation, which is not necessarily word n + 1. High activation of the foveal word can inhibit the saccade and make the fixation longer, thereby accounting for foveal load effects. SWIFT assumes that there are separate pathways for saccade timing and targeting, implying that the decision of when to move the eyes is decoupled from the decision of where to move the eyes. When to move the eyes is determined by a random timer with foveal inhibition. In contrast, where to move the eyes is determined by levels of activation, which accumulate over time.
Like E-Z Reader, there are two stages of saccade programming: a labile stage and a nonlabile stage. Error in the saccadic execution system leads to saccades sometimes missing their exact goal location (the center of the targeted word). This error can be broken down into random (Gaussian) error and systematic error. The systematic error is a function of launch site distance, so that long saccades tend to undershoot and short saccades tend to overshoot the target location. Because there is error in saccade targeting and worse processing of words at further eccentricities from the center of the word, the SWIFT model posits that saccade errors can be quickly corrected with a short, corrective saccade. Moreover, these corrective saccades are more likely to happen at word boundaries. Because of this, SWIFT posits that saccade latency is modulated by intended saccade length; with a longer intended saccade, there is longer saccade latency (i.e., preceding fixation).
With regard to the effects of parafoveal processing discussed above, SWIFT predicts n + 1 preview benefit effects, as well as their modulation by foveal load. SWIFT also predicts preview effects of word n + 2 on the basis of the assumption that processing is distributed over multiple words. Since there is no mechanism of parafoveal inhibition in SWIFT, the model cannot, in its current state, explain PoF effects, although it is often assumed that it can. However, the activation of parafoveal words can influence the probability that the foveal word is refixated. Because of this, the properties of parafoveal words may be reflected in fixation time measures that include the duration of refixations (Risse et al., 2008).
In essence, the aforementioned models are driven by lexical access in reading. In both models, foveal processing is quite important and a major factor in determining the duration of fixations. Importantly, both models also assume that lexical processing can take place parafoveally (i.e., a word can be identified using parafoveal information). While E-Z Reader postulates that a reader’s attention (i.e., the focus of lexical processing) can be allocated only to one word at a time, SWIFT allows for a more dynamic allocation of attention. Specifically, SWIFT is based on the assumption that readers are able to distribute visual attention (as an attentional gradient) over several words in the perceptual span and process multiple words at the same time. As a consequence, SWIFT implies that readers can achieve lexical access for several words simultaneously and that readers can identify words out of order.
The notion that readers can identify words out of order has been criticized as unrealistic (Rayner, Pollatsek, Liversedge, & Reichle, 2009; Reichle et al., 2009). In a language like English, where syntactic and thematic role information are almost exclusively encoded by word order, not having access to it makes it impossible to understand some sentences. For example, a sentence containing the words bit, cat, dog, the, and the could read either The cat bit the dog or The dog bit the cat. If readers cannot ascertain word order from the order in which lexical access occurs for each word, they must possess a separate system that keeps track of word order. This has the potential of greatly increasing the complexity of syntactic and semantic processing. As was argued earlier, the availability of parafoveal information gives the reader a chance to start processing the upcoming word before making an eye movement to it, improving reading speed and efficiency. Mechanisms that account for this aspect of parafoveal processing have been described in detail in the current eye movement models.
Summary
The experiments discussed in this article show that foveal and parafoveal information can interact in a variety of ways. In a situation in which there is no foveal information to process, viewers can extract a great deal of information from the parafovea, subject to acuity limitations. On the other hand, if complex foveal information has to be processed at the same time, the amount of information that can be obtained from the parafovea is reduced drastically. It is important to note, however, that these two scenarios are extreme situations. During most natural tasks, viewers process both foveal and parafoveal information. Out of those natural tasks, reading stands out as being highly structured, because the possible visual properties of the text are strongly limited by the writing system. Despite the relative visual simplicity of written characters, the task of reading is complicated by the fact that characters and words encode different aspects of language—most notably, phonology, morphology, syntax, and semantics according to orthographic rules of the language. In the preceding sections, we showed that readers are sensitive to these properties of both foveal and parafoveal words. Also, it is clear that readers can identify parafoveal words (i.e., access their entry in the mental lexicon) at least in some cases, as evidenced by word skipping.
What is less clear is whether readers sometimes identify (or even extract meaning from) two words at the same time or identify words out of order. This question is closely related to the problem of how attention is allocated during reading; models such as E-Z Reader do not allow the simultaneous lexical processing of two words or word identification that goes against the reading order, while models such as SWIFT do. The possibility of identifying words out of order presents a great problem for SWIFT, while E-Z Reader appears to have a relatively simple way of maintaining the correct order.
In conclusion, there is a great deal we know about how foveal information is integrated with parafoveal information: Parafoveal information can disrupt, limit, or even facilitate subsequent foveal processing. There still remain some questions regarding parafoveal processing. For example, how many words can readers process at the same time? If readers can obtain semantic information from the upcoming word, what conditions are necessary for that semantic preprocessing to occur? How do readers process compound words, where a constituent of the word may fall in the parafovea? How does context influence parafoveal and foveal processing? How should effects found in corpus studies be interpreted? The answers to these questions, as well as others regarding parafoveal processing, are central to moving forward our understanding of parafoveal processing and eye movements in reading.
Notes
Letter spaces are typically used as the metric for how far the eyes move, because the number of letters traversed by saccades is relatively invariant when the same text is read at different viewing distances, even though the letter spaces subtend different visual angles (Morrison & Rayner, 1981; O’Regan, 1983).
It is important to note that skipping provides a complication for corpus analyses because of a lack of data in certain cells. These missing data points are not evenly distributed, being overrepresented for words that are high frequency, predictable, or closed-class words. See the discussion of skipping effects.
See Binder, Pollatsek, and Rayner (1998) for further discussion of processing information to the left of fixation when reading English.
Word recognition performance is highest when subjects fixate near the center of a word, typically called the optimal viewing position, or OVP (O’Regan, 1981; O’Regan & Jacobs, 1992). A distinction has been made between the PVL, where they eyes actually land on a word in reading, and the OVP, the place in a word that is optimal for word recognition (see Rayner, 1998, for further discussion). For research on the PVL for readers of Hebrew, see Deutsch and Rayner (1999), and for Chinese, see Li, Liu, and Rayner (2011).
There are now numerous transposed letter studies in isolated word recognition demonstrating that transposed letter primes are more effective than primes with replacement letters (see Perea & Lupker, 2003).
See also Yang, Wang, Tong and Rayner (2010) for some further evidence of semantic preview benefit in Chinese.
Hohenstein et al. (2010) argued that the lack of a semantic preview benefit in most studies is due to the previews’ appearing for longer than 125 ms and that such studies do not precisely control for preview duration. This is because in the standard boundary paradigm, the preview is available for the duration of the fixation prior to crossing the boundary.
In addition to E-Z Reader and SWIFT, other models of eye movement control include Glenmore (Reilly & Radach, 2006), Mr. Chips (Legge, Klitz, & Tjan, 1997), EMMA (Salvucci, 2001), SERIF (McDonald, Carpenter, & Shillcock, 2005), competition/activation (Yang, 2006; Yang & McConkie, 2001), and SHARE (Feng, 2006). For a comparison of many of these models, see Reichle, Rayner, and Pollatsek (2003).
References
Abad, M. J. F., Noguera, C., & Ortells, J. J. (2003). Influence of prime–target relationship on semantic priming effects from words in a lexical-decision task. Acta Psychologica, 113, 283–295.
Altarriba, J., Kambe, G., Pollatsek, A., & Rayner, K. (2001). Semantic codes are not used in integrating information across eye fixations in reading: Evidence from fluent Spanish–English bilinguals. Perception & Psychophysics, 63, 875–890.
Angele, B., & Rayner, K. (2010). Skipping of “the“ is not fully automatic. Paper presented at the 10th Biannual Metting of the German Society for Cognitive Science, Potsdam, Germany.
Angele, B., & Rayner, K. (2011). Parafoveal processing of word n + 2 during reading: Do the preceding words matter? Journal of Experimental Psychology: Human Perception and Performance, 37, 1210–1220.
Angele, B., & Rayner, K. (in press). Eye movements and parafoveal preview of compound words: Does morpheme order matter? Quarterly Journal of Experimental Psychology.
Angele, B., Slattery, T. J., Chaloukian, T. L., Schotter, E. R., & Rayner, K. (2011). Dissociating effects of parafoveal preprocessing from effects of the sentence context. Paper presented at CUNY 2011: The 24th Annual Conference on Human Sentence Processing, Palo Alto, CA.
Angele, B., Slattery, T. J., Yang, J., Kliegl, R., & Rayner, K. (2008). Parafoveal processing in reading: Manipulating n + 1 and n + 2 previews simultaneously. Visual Cognition, 16, 697–707.
Ashby, J., & Rayner, K. (2004). Representing syllable information during silent reading: Evidence from eye movements. Language and Cognitive Processes, 19, 391–426.
Ashby, J., Treiman, R., Kessler, B., & Rayner, K. (2006). Vowel processing during silent reading: Evidence from eye movements. Journal of Experimental Psychology: Learning, Memory, and Cognition, 32, 416–424.
Bai, X., Yan, G., Zang, C., Liversedge, S. P., & Rayner, K. (2008). Reading spaced and unspaced Chinese text: Evidence from eye movements. Journal of Experimental Psychology: Human Perception and Performance, 34, 1277–1287.
Balota, D. A., Pollatsek, A., & Rayner, K. (1985). The interaction of contextual constraints and parafoveal visual information in reading. Cognitive Psychology, 17, 364–390.
Balota, D. A., & Rayner, K. (1983). Parafoveal visual information and semantic contextual constraints. Journal of Experimental Psychology: Human Perception and Performance, 9, 726–738.
Becker, C. A. (1979). Semantic context and word frequency effects in visual word recognition. Journal of Experimental Psychology: Human Perception and Performance, 5, 252–259.
Bélanger, N. N., Slattery, T. J., Mayberry, R. I., & Rayner, K. (2011). Skilled deaf readers have an enhanced perceptual span in reading. Manuscript submitted for publication.
Bertram, R., & Hyönä, J. (2007). The interplay between parafoveal preview and morphological processing in reading. In R. P. G. van Gompel, M. H. Fischer, W. S. Murray, & R. L. Hill (Eds.), Eye movements: A window on mind and brain (pp. 391–407). Oxford: Elsevier.
Blanchard, H. E., Pollatsek, A., & Rayner, K. (1989). The acquisition of parafoveal word information in reading. Perception & Psychophysics, 46, 85–94.
Bouma, H. (1970). Interaction effects in parafoveal letter recognition. Nature, 226, 177–178.
Bouma, H. (1973). Visual interference in the parafoveal recognition of initial and final letters of words. Vision Research, 13, 767–782.
Bradshaw, J. L. (1974). Peripherally presented and unreported words may bias the perceived meaning of a centrally fixated homograph. Journal of Experimental Psychology, 103, 1200–1202.
Briihl, D., & Inhoff, A. W. (1995). Integrating information across fixations during reading: The use of orthographic bodies and of exterior letters. Journal of Experimental Psychology: Learning, Memory, and Cognition, 21, 55–67.
Broadbent, D. E. (1967). Word-frequency effect and response bias. Psychological Review, 74, 1–15.
Brysbaert, M., Drieghe, D., & Vitu, F. (2005). Word skipping: Implications for theories of eye movement control in reading. In G. Underwood (Ed.), Cognitive processes in eye guidance (pp. 53–77). Oxford: Oxford University Press.
Brysbaert, M., & Vitu, F. (1998). Word skipping: Implications for theories of eye movement control in reading. In G. Underwood (Ed.), Eye guidance in reading and scene perception (pp. 125–147). Amsterdam: Elsevier.
Carpenter, P. A., & Just, M. A. (1983). What your eyes do while your mind is reading. In K. Rayner (Ed.), Eye movements in reading: Perceptual and language processes (pp. 275–307). Hillsdale: Academic Press.
Carroll, P., & Slowiaczek, M. L. (1986). Constraints on semantic priming in reading: A fixation time analysis. Memory & Cognition, 14, 509–522.
Chace, K. H., Rayner, K., & Well, A. D. (2005). Eye movements and phonological parafoveal preview: Effects of reading skill. Canadian Journal of Experimental Psychology, 59, 209–217.
Deubel, H., & Schneider, W. X. (1996). Saccade target selection and object recognition: Evidence for a common attentional mechanism. Vision Research, 36, 1827–1837.
Deutsch, A., Frost, R., Pelleg, S., Pollatsek, A., & Rayner, K. (2003). Early morphological effects in reading: Evidence from parafoveal preview benefit in Hebrew. Psychonomic Bulletin & Review, 10, 415–422.
Deutsch, A., Frost, R., Pollatsek, A., & Rayner, K. (2000). Early morphological effects in word recognition in Hebrew: Evidence from parafoveal preview benefit. Language and Cognitive Processes, 15, 487–506.
Deutsch, A., Frost, R., Pollatsek, A., & Rayner, K. (2005). Morphological parafoveal preview benefit effects in reading: Evidence from Hebrew. Language and Cognitive Processes, 20, 341–371.
Deutsch, A., & Rayner, K. (1999). Initial fixation location effects in reading Hebrew words. Language and Cognitive Processes, 14, 393–421.
Drieghe, D. (2011). Parafoveal-on-foveal effects in eye movements during reading. In S. P. Liversedge, I. D. Gilchrist, & S. Everling (Eds.), Oxford handbook on eye movements (pp. 839–855). Oxford: Oxford University Press.
Drieghe, D., Brysbaert, M., & Desmet, T. (2005). Parafoveal-on-foveal effects on eye movements in text reading: Does an extra space make a difference? Vision Research, 45, 1693–1706.
Drieghe, D., Brysbaert, M., Desmet, T., & De Baecke, C. (2004). Word skipping in reading: On the interplay of linguistic and visual factors. European Journal of Cognitive Psychology, 16, 79–103.
Drieghe, D., Pollatsek, A., Juhasz, B. J., & Rayner, K. (2010). Parafoveal processing during reading is reduced across a morphological boundary. Cognition, 116, 136–142.
Drieghe, D., Pollatsek, A., Staub, A., & Rayner, K. (2008). The word grouping hypothesis and eye movements during reading. Journal of Experimental Psychology: Learning, Memory, and Cognition, 34, 1552–1560.
Drieghe, D., Rayner, K., & Pollatsek, A. (2005). Eye movements and word skipping during reading revisited. Journal of Experimental Psychology: Human Perception and Performance, 31, 954–969.
Drieghe, D., Rayner, K., & Pollatsek, A. (2008). Mislocated fixations can account for parafoveal-on-foveal effects in eye movements during reading. Quarterly Journal of Experimental Psychology, 61, 1239–1249.
Duffy, S. A., Morris, R. K., & Rayner, K. (1988). Lexical ambiguity and fixation times in reading. Journal of Memory and Language, 27, 429–446.
Duffy, S. A., & Rayner, K. (1990). Eye movements and anaphor resolution: Effects of antecedent typicality and distance. Language and Speech, 33, 103–119.
Ehrlich, S. F., & Rayner, K. (1981). Contextual effects on word perception and eye movements during reading. Journal of Verbal Learning and Verbal Behavior, 20, 641–655.
Engbert, R., Longtin, A., & Kliegl, R. (2002). A dynamical model of saccade generation in reading based on spatially distributed lexical processing. Vision Research, 42, 621–636.
Engbert, R., Nuthmann, A., Richter, E. M., & Kliegl, R. (2005). SWIFT: A dynamical model of saccade generation during reading. Psychological Review, 112, 777–813.
Evett, L. J., & Humphreys, G. W. (1981). The use of abstract graphemic information in lexical access. Quarterly Journal of Experimental Psychology, 33A, 325–350.
Feng, G. (2006). Eye movements as time-series random variables: A stochastic model of eye movement control in reading. Cognitive Systems Research, 7, 70–95.
Feng, G., Miller, K., Shu, H., & Zhang, H. (2001). Rowed to recovery: The use of phonological and orthographic information in reading Chinese and English. Journal of Experimental Psychology: Learning, Memory, and Cognition, 27, 1079–1100.
Ferrand, L., & Grainger, J. (1992). Phonology and orthography in visual word recognition: Evidence from masked non-word priming. Quarterly Journal of Experimental Psychology, 45A, 353–372.
Ferrand, L., & Grainger, J. (1993). The time course of orthographic and phonological code activation in the early phases of visual word recognition. Bulletin of the Psychonomic Society, 31, 119–122.
Fine, E. M., & Rubin, G. S. (1999a). The effects of simulated cataract on reading with normal vision and simulated central scotoma. Vision Research, 39, 4274–4285.
Fine, E. M., & Rubin, G. S. (1999b). Reading with a central field loss: Number of letters masked is more important than the size of the mask in degrees. Vision Research, 39, 747–756.
Fine, E. M., & Rubin, G. S. (1999c). Reading with simulated scotomas: Attending to the right is better than attending to the left. Vision Research, 39, 1039–1048.
Fitzsimmons, G., & Drieghe, D. (2011). The influence of number of syllables on word skipping during reading. Psychonomic Bulletin & Review, 18, 736–741.
Forster, K. I., & Chambers, S. M. (1973). Lexical access and naming time. Journal of Verbal Learning and Verbal Behavior, 12, 627–635.
Frisson, S., Rayner, K., & Pickering, M. J. (2005). Effects of contextual predictability and transitional probability on eye movements during reading. Journal of Experimental Psychology: Learning, Memory, and Cognition, 31, 862–877.
Gautier, V., O’Regan, J. K., & Le Gargasson, J. F. (2000). “The-skipping”revisited in French: Programming saccades to skip the article ‘les. Vision Research, 40, 2517–2531.
Glover, L., Vorstius, C., & Radach, R. (in press). Exploring the limits of distant parafoveal processing during reading: A new look at n + 2 preview effects. Journal of Eye Movement Research.
Gollan, T. H., Slattery, T. J., Goldenberg, D., Van Assche, E., Duyck, W., & Rayner, K. (2011). Frequency drives lexical access in reading but not in speaking: The frequency-lag hypothesis. Journal of Experimental Psychology: General, 140, 186–209.
Häikiö, T., Bertram, R., Hyönä, J., & Niemi, P. (2009). Development of the letter identity span in reading: Evidence from the eye movement moving window paradigm. Journal of Experimental Child Psychology, 102, 167–181.
Hand, C. J., Miellet, S., O’Donnell, P. J., & Sereno, S. C. (2010). The frequency-predictability interaction in reading: It depends where you’re coming from. Journal of Experimental Psychology: Human Perception and Performance. 36, 1294–1313.
Henderson, J. M., Dixon, P., Petersen, A., Twilley, L. C., & Ferreira, F. (1995). Evidence for the use of phonological representations during transsaccadic word recognition. Journal of Experimental Psychology: Human Perception and Performance, 21, 82–97.
Henderson, J. M., & Ferreira, F. (1990). Effects of foveal processing difficulty on the perceptual span in reading: Implications for attention and eye movement control. Journal of Experimental Psychology: Learning, Memory and Cognition, 16, 417–429.
Henderson, J. M., & Ferreira, F. (1993). Eye movement control during reading: Fixation measures reflect foveal but not parafoveal processing difficulty. Canadian Journal of Experimental Psychology, 47, 201–221.
Hohenstein, S., Laubrock, J., & Kliegl, R. (2010). Semantic preview benefit in eye movements during reading: A parafoveal fast-priming study. Journal of Experimental Psychology: Learning, Memory, and Cognition, 36, 1150–1170.
Hoosain, R. (1992). Psychological reality of the word in Chinese. In H.-C. Chen & O. J. L. Tzeng (Eds.), Language processing in Chinese (pp. 111–130). Amsterdam: North-Holland.
Howes, D. H., & Solomon, R. L. (1951). Visual duration threshold as a function of word-probability. Journal of Experimental Psychology, 41, 401–410.
Humphreys, G. W., Evett, L. J., & Taylor, D. E. (1982). Automatic phonological priming in visual word recognition. Memory & Cognition, 10, 576–590.
Hyönä, J. (1993). Effects of thematic and lexical priming on readers’ eye movements. Scandinavian Journal of Psychology, 34, 293–304.
Hyönä, J. (1995). Do irregular letter combinations attract readers’ attention? Evidence from fixation locations in words. Journal of Experimental Psychology: Human Perception and Performance, 21, 68–81.
Hyönä, J. (2011). Foveal and parafoveal processing during reading. In S. P. Liversedge, I. D. Gilchrist, & S. Everling (Eds.), Oxford handbook on eye movements (pp. 819–838). Oxford: Oxford University Press.
Hyönä, J., & Bertram, R. (2004). Do frequency characteristics of non-fixated words influence the processing of fixated words during reading? European Journal of Cognition Psychology, 16, 104–127.
Hyönä, J., Bertram, R., & Pollatsek, A. (2004). Are long compound words identified serially via their constituents? Evidence from an eye-movement-contingent display change study. Memory & Cognition, 32, 523–532.
Hyönä, J., & Häikiö, T. (2005). Is emotional content obtained from parafoveal words during reading? An eye movement analysis. Scandinavian Journal of Psychology, 46, 475–483.
Hyönä, J., Niemi, P., & Underwood, G. (1989). Reading long words embedded in sentences: Informativeness of word halves affects eye movements. Journal of Experimental Psychology: Human Perception and Performance, 15, 142–152.
Ikeda, M., & Saida, S. (1978). Span of recognition in reading. Vision Research, 18, 83–88.
Inhoff, A. W. (1982). Parafoveal word perception: A further case against semantic preprocessing. Journal of Experimental Psychology: Human Perception and Performance, 8, 137–145.
Inhoff, A. W. (1984). Two stages of word processing during eye fixations in the reading of prose. Journal of Verbal Learning and Verbal Behavior, 23, 612–624.
Inhoff, A. W. (1987). Parafoveal word perception during eye fixations in reading: Effects of visual salience and word structure. In M. Coltheart (Ed.), Attention and performance XII (pp. 403–418). Hillsdale: Erlbaum.
Inhoff, A. W. (1989a). Lexical access during eye fixations in reading: Are word access codes used to integrate lexical information across interword fixations? Journal of Memory and Language, 28, 444–461.
Inhoff, A. W. (1989b). Parafoveal processing of words and saccade computation during eye fixations in reading. Journal of Experimental Psychology: Human Perception and Performance, 15, 544–555.
Inhoff, A. W. (1990). Integrating information across eye fixations in reading: The role of letter and word units. Acta Psychologica, 73, 281–297.
Inhoff, A. W., Eiter, B. M., & Radach, R. (2005). Time course of linguistic information extraction from consecutive words during eye fixations in reading. Journal of Experimental Psychology: Human Perception and Performance, 31, 979–995.
Inhoff, A. W., Greenberg, S. N., Solomon, M., & Wang, C.-A. (2009). Word integration and regression programming during reading: A test of the E-Z reader 10 model. Journal of Experimental Psychology: Human Perception and Performance, 35, 1571–1584.
Inhoff, A. W., & Liu, W. (1998). The perceptual span and oculomotor activity during the reading of Chinese sentences. Journal of Experimental Psychology: Human Perception and Performance, 24, 20–34.
Inhoff, A. W., Liu, W., Starr, M., & Wang, J. (1998). Eye-movement-contingent display changes are not compromised by flicker and phosphor persistence. Psychonomic Bulletin & Review, 5, 101–106.
Inhoff, A. W., Pollatsek, A., Posner, M. I., & Rayner, K. (1989). Covert attention and eye movements during reading. Quarterly Journal of Experimental Psychology, 41A, 63–89.
Inhoff, A. W., Radach, R., & Eiter, B. M. (2006). Temporal overlap in the linguistic processing of consecutive words in reading: Reply to Pollatsek, Reichle, and Rayner (2006a). Journal of Experimental Psychology: Human Perception and Performance, 32, 1490–1495.
Inhoff, A. W., Radach, R., Eiter, B. M., & Juhasz, B. (2003). Distinct subsystems for the parafoveal processing of spatial and linguistic information during eye fixations in reading. Quarterly Journal of Experimental Psychology, 56A, 803–827.
Inhoff, A. W., Radach, R., & Heller, D. (2000). Complex compounds in German: Interword spaces facilitate segmentation but hinder assignment of meaning. Journal of Memory and Language, 42, 23–50.
Inhoff, A. W., Radach, R., Starr, M., & Greenberg, S. (2000). Allocation of visuospatial attention and saccade programming during reading. In A. Kennedy, R. Radach, D. Heller, & J. Pynte (Eds.), Reading as a perceptual process (pp. 221–246). Oxford: North-Holland/Elsevier.
Inhoff, A. W., & Rayner, K. (1980). Parafoveal word perception: A case against semantic preprocessing. Perception & Psychophysics, 27, 457–464.
Inhoff, A. W., & Rayner, K. (1986). Parafoveal word processing during eye fixations in reading: Effects of word frequency. Perception & Psychophysics, 40, 431–439.
Inhoff, A. W., Starr, M., & Shindler, K. L. (2000). Is the processing of words during eye fixations in reading strictly serial? Perception & Psychophysics, 62, 1474–1484.
Inhoff, A. W., & Tousman, S. (1990). Lexical priming from partial-word previews. Journal of Experimental Psychology: Learning, Memory, and Cognition, 16, 825–836.
Johnson, R. L. (2007). The flexibility of letter coding: Nonadjacent letter transposition effects in the parafovea. In R. P. G. van Gompel, M. H. Fischer, W. S. Murray, & R. L. Hill (Eds.), Eye movements: A window on mind and brain (pp. 425–440). Oxford: Elsevier.
Johnson, R. L., & Dunne, M. (In press). Parafoveal processing of transposed-letter words and nonwords: Evidence against parafoveal lexical activation. Journal of Experimental Psychology: Human Perception and Performance.
Johnson, R. L., Perea, M., & Rayner, K. (2007). Transposed-letter effects in reading: Evidence from eye movements and parafoveal preview. Journal of Experimental Psychology: Human Perception and Performance, 33, 209–229.
Juhasz, B. J., Pollatsek, A., Hyönä, J., Drieghe, D., & Rayner, K. (2009). Parafoveal processing within and between words. Quarterly Journal of Experimental Psychology, 62, 1356–1376.
Juhasz, B. J., White, S. J., Liversedge, S. P., & Rayner, K. (2008). Eye movements and the use of parafoveal word length information in reading. Journal of Experimental Psychology: Human Perception and Performance, 34, 1560–1579.
Just, M. A., & Carpenter, P. A. (1980). A theory of reading: From eye fixations to comprehension. Psychological Review, 87, 329–354.
Kambe, G. (2004). Parafoveal processing of prefixed words during eye fixations in reading: Evidence against morphological influences on parafoveal preprocessing. Perception & Psychophysics, 66, 279–292.
Kapoula, Z. (1985). Evidence for a range effect in the saccadic system. Vision Research, 25, 1155–1157.
Kennedy, A. (1998). The influence of parafoveal words on foveal inspection time: Evidence for a processing trade-off. In G. Underwood (Ed.), Eye guidance in reading and scene perception (pp. 149–179). Oxford: Elsevier.
Kennedy, A. (2000). Parafoveal processing in word recognition. Quarterly Journal of Experimental Psychology, 53A, 429–455.
Kennedy, A. (2008). Parafoveal-on-foveal effects are not an artifact of mislocated saccades. Journal of Eye Movement Research, 2, 1–10.
Kennedy, A., Murray, W., & Boissiere, C. (2004). Parafoveal pragmatics revisited. European Journal of Cognitive Psychology, 16, 128–153.
Kennedy, A., & Pynte, J. (2005). Parafoveal-on-foveal effects in normal reading. Vision Research, 45, 153–168.
Kennedy, A., Pynte, J., & Ducrot, S. (2002). Parafoveal-on-foveal interactions in word recognition. Quarterly Journal of Experimental Psychology, 55A, 1307–1337.
Kennison, S. M., & Clifton, C. (1995). Determinants of parafoveal preview benefit in high and low working memory capacity readers: Implications for eye movement control. Journal of Experimental Psychology: Learning, Memory, and Cognition, 21, 68–81.
Kirkby, J. A., Webster, L. A. D., Blythe, H. I., & Liversedge, S. P. (2008). Binocular coordination during reading and non-reading tasks. Psychological Bulletin, 134, 742–763.
Kliegl, R. (2007). Toward a perceptual-span theory of distributed processing in reading: A reply to Rayner, Pollatsek, Drieghe, Slattery, and Reichle (2007). Journal of Experimental Psychology: General, 136, 530–537.
Kliegl, R., & Engbert, R. (2005). Fixation durations before word skipping in reading. Psychonomic Bulletin & Review, 12, 132–138.
Kliegl, R., Grabner, E., Rolfs, M., & Engbert, R. (2004). Length, frequency, and predictability effects of words on eye movements in reading. European Journal of Cognitive Psychology, 16, 262–284.
Kliegl, R., Nuthmann, A., & Engbert, R. (2006). Tracking the mind during reading: The influence of past, present, and future words on fixation durations. Journal of Experimental Psychology: General, 135, 12–35.
Kliegl, R., Olson, R. K., & Davidson, B. J. (1982). Regression analyses as a tool for studying reading processes: Comment on just and carpenter’s eye fixation theory. Memory & Cognition, 10, 287–296.
Kliegl, R., Risse, S., & Laubrock, J. (2007). Preview benefit and parafoveal-on-foveal effects from word n + 2. Journal of Experimental Psychology: Human Perception and Performance, 33, 1250–1255.
Koch, C., & Ullman, S. (1985). Shifts in selective visual attention: Towards the underlying neural circuitry. Human Neurobiology, 4, 219–227.
Lee, Y. A., Binder, K. S., Kim, J. O., Pollatsek, A., & Rayner, K. (1999a). Activation of phonological codes during eye fixations in reading. Journal of Experimental Psychology: Human Perception and Performance, 25, 948–964.
Lee, H. W., Rayner, K., & Pollatsek, A. (1999b). The time course of phonological, semantic, and orthographic coding in reading: Evidence from the fast-priming technique. Psychonomic Bulletin & Review, 6, 624–634.
Lee, H., Legge, G. E., & Ortiz, A. (2003). Is word recognition different in central and peripheral vision? Vision Research, 43, 2837–2846.
Legge, G. E., Klitz, T. S., & Tjan, B. S. (1997). Mr. Chips: An ideal-observer model of reading. Psychological Review, 104, 524–553.
Li, X., Liu, P., & Rayner, K. (2011). Eye movement guidance in Chinese reading: Is there a preferred viewing location? Vision Research, 51, 1146–1156.
Lima, S. D. (1987). Morphological analysis in sentence reading. Journal of Memory and Language, 26, 84–99.
Lima, S. D., & Inhoff, A. W. (1985). Lexical access during eye fixations in reading: Effects of word-initial letter sequence. Journal of Experimental Psychology: Human Perception and Performance, 11, 272–285.
Liu, W., Inhoff, A. W., Ye, Y., & Wu, C. (2002). Use of parafoveally visible characters during the reading of Chinese sentences. Journal of Experimental Psychology: Human Perception and Performance, 28, 1213–1227.
Liversedge, S. P., Rayner, K., White, S. J., Vergilino-Perez, D., Findlay, J. M., & Kentridge, R. W. (2004). Eye movements when reading disappearing text: Is there a gap effect in reading? Vision Research, 44, 1013–1024.
Liversedge, S. P., & Underwood, G. (1998). Foveal processing load and landing position effects in reading. In G. Underwood (Ed.), Eye guidance in reading and scene perception (pp. 201–221). Oxford: North-Holland/Elsevier.
Matin, E. (1974). Saccadic suppression: A review and an analysis. Psychological Bulletin, 81, 899–917.
McConkie, G. W., Kerr, P. W., Reddix, M. D., & Zola, D. (1988). Eye movement control during reading: I. The location of initial eye fixations on words. Vision Research, 28, 1107–1118.
McConkie, G. W., & Rayner, K. (1975). The span of the effective stimulus during a fixation in reading. Perception & Psychophysics, 17, 578–587.
McConkie, G. W., & Rayner, K. (1976). Asymmetry of the perceptual span in reading. Bulletin of the Psychonomic Society, 8, 365–368.
McConkie, G. W., & Zola, D. (1979). Is visual information integrated across successive fixations in reading? Perception & Psychophysics, 25, 221–224.
McDonald, S. A. (2005). Parafoveal preview benefit in reading is not cumulative across multiple saccades. Vision Research, 45, 1829–1834.
McDonald, S. A. (2006). Parafoveal preview benefit in reading is only obtained from the saccade goal. Vision Research, 46, 4416–4424.
McDonald, S. A., Carpenter, R. H. S., & Shillcock, R. C. (2005). An anatomically constrained, stochastic model of eye movement control in reading. Psychological Review, 112, 814–840.
McDonald, S. A., & Shillcock, R. C. (2003a). Eye movements reveal the on-line computation of lexical probabilities during reading. Psychological Science, 14, 648–652.
McDonald, S. A., & Shillcock, R. C. (2003b). Low-level predictive inference in reading: The influence of transitional probabilities on eye movements. Vision Research, 43, 1735–1751.
Meyer, D. E., & Schvaneveldt, R. W. (1971). Facilitation in recognizing pairs of words: Evidence of a dependence between retrieval operations. Journal of Experimental Psychology, 90, 227–234.
Meyer, D. E., Schvaneveldt, R. W., & Ruddy, M. G. (1974). Functions of graphemic and phonemic codes in visual word recognition. Memory & Cognition, 2, 309–321.
Miellet, S., O’Donnell, P. J., & Sereno, S. C. (2009). Parafoveal magnification: Visual acuity does not modulate the perceptual span in reading. Psychological Science, 20, 721–728.
Miellet, S., & Sparrow, L. (2004). Phonological codes are assembled before word fixation: Evidence from boundary paradigm in sentence reading. Brain and Language, 90, 299–310.
Miellet, S., Sparrow, L., & Sereno, S. C. (2007). Word frequency and predictability effects in reading French: An evaluation of the E-Z reader model. Psychonomic Bulletin & Review, 14, 762–769.
Morris, R. K., Rayner, K., & Pollatsek, A. (1990). Eye movement guidance in reading: The role of parafoveal letter and space information. Journal of Experimental Psychology: Human Perception and Performance, 16, 268–281.
Morrison, R. E., & Rayner, K. (1981). Saccade size in reading depends upon character spaces and not visual angle. Perception & Psychophysics, 30, 395–396.
Murray, W. S. (1998). Parafoveal pragmatics. In G. Underwood (Ed.), Eye guidance in reading and scene perception (pp. 181–199). Oxford: North-Holland/Elsevier.
Murray, W. S., & Rowan, M. (1998). Early, mandatory, pragmatic processing. Journal of Psycholinguistic Research, 27, 1–22.
Neely, J. H. (1977). Semantic priming and retrieval from lexical memory: Roles of inhibitionless spreading activation and limited-capacity attention. Journal of Experimental Psychology: General, 106, 226–254.
Nuthmann, A., Engbert, R., & Kliegl, R. (2005). Mislocated fixations during reading and the inverted optimal viewing position effect. Vision Research, 45, 2201–2217.
O’Regan, J. K. (1979). Eye guidance in reading: Evidence for the linguistic control hypothesis. Perception & Psychophysics, 25, 501–509.
O’Regan, J. K. (1980). The control of saccade size and fixation duration in reading: The limits of linguistic control. Attention, Perception, & Psychophysics, 28, 112–117.
O’Regan, J. K. (1981). The convenient viewing position hypothesis. In D. F. Fisher, R. A. Monty, & J. W. Senders (Eds.), Eye movements: Cognition and visual perception (pp. 289–298). Hillsdale: Erlbaum.
O’Regan, J. K. (1983). Elementary perceptual and eye movement control processes in reading. In K. Rayner (Ed.), Eye movements in reading: Perceptual and language processes (pp. 121–140). San Diego: Academic Press.
O’Regan, J. K., & Jacobs, A. M. (1992). Optimal viewing position effect in word recognition: A challenge to current theory. Journal of Experimental Psychology: Human Perception and Performance, 18, 185–197.
Ortells, J. J., Abad, M. J. F., Noguera, C., & Lupiáñez, J. (2001). Influence of prime–probe stimulus onset asynchrony and prime precuing manipulations on semantic priming effects with words in a lexical-decision task. Journal of Experimental Psychology: Human Perception and Performance, 27, 75–91.
Ortells, J. J., & Tudela, P. (1996). Positive and negative semantic priming of attended and unattended parafoveal words in a lexical decision task. Acta Psychologica, 94, 209–226.
Osaka, N. (2003). Asymmetry of the effective visual field in vertical reading as measured with a moving window. In G. d'Ydewalle & J. Van Rensbergen (Eds.), Perception and cognition: Advances in eye movement research (pp. 275–283). Amsterdam: North-Holland.
Osaka, N., & Osaka, M. (2002). Individual differences in working memory during reading with and without parafoveal information: A moving-window study. The American Journal of Psychology, 115, 501–513.
Paterson, K. B., & Jordan, T. R. (2010). Effects of increased letter spacing on word identification and eye guidance during reading. Memory & Cognition, 38, 502–512.
Paterson, K. B., Liversedge, S. P., & Davis, C. J. (2009). Inhibitory neighbor priming effects in eye movements during reading. Psychonomic Bulletin & Review, 16, 43–50.
Perea, M., & Acha, J. (2009). Space information is important for reading. Vision Research, 49, 1994–2000.
Perea, M., & Lupker, S. (2003). Does jugde activate COURT? Transposed-letter similarity effects in masked associative priming. Memory & Cognition, 31, 829–841.
Perfetti, C. A., & Bell, L. (1991). Phonemic activation during the first 40 ms of word identification: Evidence from backward masking and priming. Journal of Memory and Language, 30, 473–485.
Pollatsek, A., Bolozky, S., Well, A. D., & Rayner, K. (1981). Asymmetries in the perceptual span for Israeli readers. Brain and Language, 14, 174–180.
Pollatsek, A., Juhasz, B. J., Reichle, E. D., Machacek, D., & Rayner, K. (2008). Immediate and delayed effects of word frequency and word length on eye movements during reading: A reversed delayed effect of word length. Journal of Experimental Psychology: Human Perception and Performance, 34, 726–750.
Pollatsek, A., Lesch, M., Morris, R. K., & Rayner, K. (1992). Phonological codes are used in integrating information across saccades in word identification and reading. Journal of Experimental Psychology: Human Perception and Performance, 18, 148–162.
Pollatsek, A., & Rayner, K. (1982). Eye movement control in reading: The role of word boundaries. Journal of Experimental Psychology: Human Perception and Performance, 8, 817–833.
Pollatsek, A., Reichle, E. D., & Rayner, K. (2006a). Attention to one word at a time is still a viable hypothesis: Rejoinder to Inhoff, Radach, and Eiter. Journal of Experimental Psychology: Human Perception and Performance, 32, 1496–1500.
Pollatsek, A., Reichle, E. D., & Rayner, K. (2006b). Serial processing is consistent with the time course of linguistic information extraction from consecutive words during eye fixations in reading: A response to Inhoff, Eiter, and Radach (2005). Journal of Experimental Psychology: Human Perception and Performance, 32, 1485–1489.
Pollatsek, A., Tan, L. H., & Rayner, K. (2000). The role of phonological codes in integrating information across saccadic eye movements in Chinese character identification. Journal of Experimental Psychology: Human Perception and Performance, 26, 607–633.
Pynte, J., & Kennedy, A. (2006). An influence over eye movements in reading exerted from beyond the level of the word: Evidence from English and French. Vision Research, 46, 3786–3801.
Pynte, J., Kennedy, A., & Ducrot, S. (2004). The influence of parafoveal typographical errors on eye movements in reading. European Journal of Cognitive Psychology, 16, 178–202.
Radach, R. (1996). Blickbewegungen beim lesen: Psychologische aspekte der determination von fixationspositionen [Eye movements in reading: Psychological factors that determine fixation locations]. Münster: Waxmann.
Radach, R., Inhoff, A., & Heller, D. (2004). Orthographic regularity gradually modulates saccade amplitude in reading. European Journal of Cognitive Psychology, 16, 27–51.
Rayner, K. (1975a). Parafoveal identification during a fixation in reading. Acta Psychologica, 39, 271–282.
Rayner, K. (1975b). The perceptual span and peripheral cues in reading. Cognitive Psychology, 7, 65–81.
Rayner, K. (1977). Visual attention in reading: Eye movements reflect cognitive processes. Memory & Cognition, 5, 443–448.
Rayner, K. (1978a). Eye movement latencies for parafoveally presented words. Bulletin of the Psychonomic Society, 11, 13–16.
Rayner, K. (1978b). Eye movements in reading and information processing. Psychological Bulletin, 85, 618–660.
Rayner, K. (1978c). Foveal and parafoveal cues in reading. In J. Requin (Ed.), Attention and performance VII (pp. 149–162). Hillsdale: Erlbaum.
Rayner, K. (1979). Eye guidance in reading: Fixation locations within words. Perception, 8, 21–30.
Rayner, K. (1986). Eye movements and the perceptual span in beginning and skilled readers. Journal of Experimental Child Psychology, 41, 211–236.
Rayner, K. (1998). Eye movements in reading and information processing: 20 years of research. Psychological Bulletin, 124, 372–422.
Rayner, K. (2009). The thirty fifth Sir Frederick Bartlett lecture: Eye movements and attention in reading, scene perception, and visual search. Quarterly Journal of Experimental Psychology, 62, 1457–1506.
Rayner, K., Ashby, J., Pollatsek, A., & Reichle, E. D. (2004). The effects of frequency and predictability on eye fixations in reading: Implications for the E-Z reader model. Journal of Experimental Psychology: Human Perception and Performance, 30, 720–732.
Rayner, K., Balota, D. A., & Pollatsek, A. (1986). Against parafoveal semantic preprocessing during eye fixations in reading. Canadian Journal of Psychology, 40, 473–483.
Rayner, K., & Bertera, J. H. (1979). Reading without a fovea. Science, 206, 468–469.
Rayner, K., Binder, K. S., Ashby, J., & Pollatsek, A. (2001). Eye movement control in reading: Word predictability has little influence on initial landing positions in words. Vision Research, 41, 943–954.
Rayner, K., Castelhano, M. S., & Yang, J. (2009). Eye movements and the perceptual span in older and younger readers. Psychology and Aging, 24, 755–760.
Rayner, K., Castelhano, M. S., & Yang, J. (2010). Eye movements and preview benefit in older and younger readers. Psychology and Aging, 25, 714–718.
Rayner, K., & Duffy, S. A. (1986). Lexical complexity and fixation times in reading: Effects of word frequency, verb complexity, and lexical ambiguity. Memory & Cognition, 14, 191–201.
Rayner, K., Fischer, M. H., & Pollatsek, A. (1998). Unspaced text interferes with both word identification and eye movement control. Vision Research, 38, 1129–1144.
Rayner, K., & Frazier, L. (1989). Selection mechanisms in reading lexically ambiguous words. Journal of Experimental Psychology: Learning, Memory, and Cognition, 15, 779–790.
Rayner, K., Inhoff, A. W., Morrison, R. E., Slowiaczek, M. L., & Bertera, J. H. (1981). Masking of foveal and parafoveal vision during eye fixations in reading. Journal of Experimental Psychology: Human Perception and Performance, 7, 167–179.
Rayner, K., Juhasz, B. J., & Brown, S. J. (2007). Do readers obtain preview benefit from word n + 2? A test of serial attention shift versus distributed lexical processing models of eye movement control in reading. Journal of Experimental Psychology: Human Perception and Performance, 33, 230–245.
Rayner, K., Li, X., & Pollatsek, A. (2007). Extending the E-Z reader model of eye movement control to Chinese readers. Cognitive Science, 31, 1021–1033.
Rayner, K., Liversedge, S. P., & White, S. J. (2006). Eye movements when reading disappearing text: The importance of the word to the right of fixation. Vision Research, 46, 310–323.
Rayner, K., Liversedge, S. P., White, S. J., & Vergilino-Perez, D. (2003). Reading disappearing text. Psychological Science, 14, 385–388.
Rayner, K., & McConkie, G. W. (1976). What guides a reader’s eye movements? Vision Research, 16, 829–837.
Rayner, K., McConkie, G. W., & Ehrlich, S. (1978). Eye movements and integrating information across fixations. Journal of Experimental Psychology: Human Perception and Performance, 4, 529–544.
Rayner, K., McConkie, G. W., & Zola, D. (1980). Integrating information across eye movements. Cognitive Psychology, 12, 206–226.
Rayner, K., & Morris, R. K. (1992). Eye movement control in reading: Evidence against semantic preprocessing. Journal of Experimental Psychology: Human Perception and Performance, 18, 163–172.
Rayner, K., & Morrison, R. E. (1981). Eye movements and identifying words in parafoveal vision. Bulletin of the Psychonomic Society, 17, 135–138.
Rayner, K., Murphy, L., Henderson, J. M., & Pollatsek, A. (1989). Selective attentional dyslexia. Cognitive Neuropsychology, 6, 357–378.
Rayner, K., Pollatsek, A., Drieghe, D., Slattery, T. J., & Reichle, E. D. (2007). Tracking the mind during reading via eye movements: Comments on Kliegl, Nuthmann, and Engbert (2006). Journal of Experimental Psychology: General, 136, 520–529.
Rayner, K., Pollatsek, A., Liversedge, S. P., & Reichle, E. D. (2009). Eye movements and non-canonical reading: Comments on Kennedy and Pynte (2008). Vision Research, 49, 2232–2236.
Rayner, K., Sereno, S. C., Lesch, M. F., & Pollatsek, A. (1995). Phonological codes are automatically activated during reading: Evidence from an eye movement priming paradigm. Psychological Science, 6, 26–32.
Rayner, K., Sereno, S. C., & Raney, G. E. (1996). Eye movement control in reading: A comparison of two types of models. Journal of Experimental Psychology: Human Perception and Performance, 22, 1188–1200.
Rayner, K., Slattery, T. J., & Bélanger, N. N. (2010). Eye movements, the perceptual span, and reading speed. Psychonomic Bulletin & Review, 17, 834–839.
Rayner, K., Slattery, T. J., Drieghe, D., & Liversedge, S. P. (2011). Eye movements and word skipping during reading: Effects of word length and predictability. Journal of Experimental Psychology: Human Perception and Performance, 37, 514–528.
Rayner, K., Warren, T., Juhasz, B. J., & Liversedge, S. P. (2004). The effect of plausibility on eye movements in reading. Journal of Experimental Psychology: Learning, Memory, and Cognition, 30, 1290–1301.
Rayner, K., & Well, A. D. (1996). Effects of contextual constraint on eye movements in reading: A further examination. Psychonomic Bulletin & Review, 3, 504–509.
Rayner, K., Well, A. D., & Pollatsek, A. (1980). Asymmetry of the effective visual field in reading. Perception & Psychophysics, 27, 537–544.
Rayner, K., Well, A. D., Pollatsek, A., & Bertera, J. H. (1982). The availability of useful information to the right of fixation in reading. Perception & Psychophysics, 31, 537–550.
Rayner, K., White, S. J., Kambe, G., Miller, B., & Liversedge, S. P. (2003). On the processing of meaning from parafoveal vision during eye fixations in reading. In J. Hyönä, R. Radach, & H. Deubel (Eds.), The mind’s eye: Cognitive and applied aspects of eye movement research (pp. 213–234). Oxford: Elsevier.
Rayner, K., Yang, J., Castelhano, M. S., & Liversedge, S. P. (2011). Eye movements of older and younger readers when reading disappearing text. Psychology and Aging, 26, 214–223.
Reichle, E. D., Liversedge, S. P., Pollatsek, A., & Rayner, K. (2009). Encoding multiple words simultaneously in reading is implausible. Trends in Cognitive Sciences, 13, 115–119.
Reichle, E. D., Pollatsek, A., Fisher, D. L., & Rayner, K. (1998). Toward a model of eye movement control in reading. Psychological Review, 105, 125–157.
Reichle, E. D., Pollatsek, A., & Rayner, K. (2006). E-Z reader: A cognitive-control, serial-attention model of eye-movement behavior during reading. Cognitive Systems Research, 7, 4–22.
Reichle, E. D., Pollatsek, A., & Rayner, K. (2007). Modeling the effects of lexical ambiguity on eye movements during reading. In R. P. G. van Gompel, M. H. Fischer, W. S. Murray, & R. L. Hill (Eds.), Eye movements: A window on mind and brain (pp. 271–292). Amsterdam: Elsevier.
Reichle, E. D., Rayner, K., & Pollatsek, A. (2003). The E-Z reader model of eye-movement control in reading: Comparisons to other models. The Behavioral and Brain Sciences, 26, 445–476.
Reichle, E. D., Warren, T., & McConnell, K. (2009). Using E-Z reader to model the effects of higher-level language processing on eye movements during reading. Psychonomic Bulletin & Review, 16, 1–20.
Reilly, R. G., & Radach, R. (2006). Some empirical tests of an interactive activation model of eye movement control in reading. Cognitive Systems Research, 7, 34–55.
Reingold, E. M., & Rayner, K. (2006). Examining the word identification stages hypothesized by the E-Z reader model. Psychological Science, 17, 742–746.
Reingold, E. M., Reichle, E. D., Glaholt, M. G., & Sheridan, H. (in press). Direct lexical control of eye movements in reading: Evidence from a survival analysis of fixation durations. Cognitive Psychology.
Reingold, E. M., Yang, J., & Rayner, K. (2010). The time course of word frequency and case alternation effects on fixation times in reading: Evidence for lexical control of eye movements. Journal of Experimental Psychology: Human Perception and Performance, 36, 1677–1683.
Risse, S., Engbert, R., & Kliegl, R. (2008). Eye-movement control in reading: Experimental and corpus-analytic challenges for a computational model. In K. Rayner, D. Shen, X. Bai, & G. Yan (Eds.), Cognitive and cultural influences on eye movements (pp. 65–92). Tianjin: Tianjin People's Publishing House/Psychology Press.
Risse, S., & Kliegl, R. (2011). Adult age differences in the perceptual span during reading. Psychology and Aging, 26, 451–460.
Saint-Aubin, J., & Klein, R. M. (2001). Influence of parafoveal processing on the missing-letter effect. Journal of Experimental Psychology: Human Perception and Performance, 27, 318–334.
Salvucci, D. D. (2001). An integrated model of eye movements and visual encoding. Cognitive Systems Research, 1, 201–220.
Schad, D. J., Nuthmann, A., & Engbert, R. (2010). Eye movements during reading of randomly shuffled text. Vision Research, 50, 2600–2616.
Schilling, H. E. H., Rayner, K., & Chumbley, J. I. (1998). Comparing naming, lexical decision, and eye fixation times: Word frequency effects and individual differences. Memory & Cognition, 26, 1270–1281.
Schroyens, W., Vitu, F., Brysbaert, M., & d'Ydewalle, G. (1999). Eye movement control during reading: Foveal load and parafoveal processing. Quarterly Journal of Experimental Psychology, 52A, 1021–1046.
Schustack, M. W., Ehrlich, S. F., & Rayner, K. (1987). Local and global sources of contextual facilitation in reading. Journal of Memory and Language, 26, 322–340.
Sereno, S. C., O’Donnell, P. J., & Rayner, K. (2006). Eye movements and lexical ambiguity resolution: Investigating the subordinate-bias effect. Journal of Experimental Psychology: Human Perception and Performance, 32, 335–350.
Sereno, S. C., & Rayner, K. (1992). Fast priming during eye fixations in reading. Journal of Experimental Psychology: Human Perception and Performance, 18, 173–184.
Shepherd, M., Findlay, J. M., & Hockey, R. J. (1986). The relationship between eye movements and spatial attention. Quarterly Journal of Experimental Psychology, 38A, 475–491.
Shu, H., Zhou, W., Yan, M., & Kliegl, R. (2010). Font size modulates saccade-target selection in Chinese reading. Attention, Perception, & Psychophysics, 73, 482–490.
Slattery, T. J. (2009). Word misperception, the neighbor frequency effect, and the role of sentence context: Evidence from eye movements. Journal of Experimental Psychology: Human Perception and Performance, 35, 1969–1975.
Slattery, T. J., Angele, B., & Rayner, K. (2011). Eye movements and display change detection during reading. Journal of Experimental Psychology: Human Perception and Performance. Advance online publication. doi:10.1037/a0024322
Slattery, T. J., Schotter, E. R., Berry, R. W., & Rayner, K. (2011). Parafoveal and foveal processing of abbreviations during eye fixations in reading: Making a case for case. Journal of Experimental Psychology: Learning, Memory, and Cognition, 37, 1022–1031.
Slattery, T. J., Staub, A., & Rayner, K. (in press). Saccade launch site as a predictor of fixation durations in reading: Comments on Hand, Miellet, O’Donnell, and Sereno (2010). Journal of Experimental Psychology: Human Perception and Performance.
Sparrow, L., & Miellet, S. (2002). Activation of phonological codes during reading: Evidence from errors detection and eye movements. Brain and Language, 81, 509–516.
Starr, M., & Inhoff, A. (2004). Attention allocation to the right and left of a fixated word: Use of orthographic information from multiple words during reading. European Journal of Cognitive Psychology, 16, 203–225.
Staub, A. (2011a). The effect of lexical predictability on distributions of eye fixation durations. Psychonomic Bulletin & Review, 18, 371–376.
Staub, A. (2011b). Word recognition and syntactic attachment in reading: Evidence for a staged architecture. Journal of Experimental Psychology: General, 140, 407–433.
Staub, A., Rayner, K., Pollatsek, A., Hyönä, J., & Majewski, H. (2007). The time course of plausibility effects on eye movements in reading: Evidence from noun-noun compounds. Journal of Experimental Psychology: Learning, Memory, and Cognition, 33, 1162–1169.
Staub, A., White, S. J., Drieghe, D., Hollway, E. C., & Rayner, K. (2010). Distributional effects of word frequency on eye movements in reading. Journal of Experimental Psychology: Human Perception and Performance, 36, 1280–1293.
Taft, M. (1981). Prefix stripping revisited. Journal of Verbal Learning and Verbal Behavior, 20, 289–297.
Taft, M., & Forster, K. I. (1975). Lexical storage and retrieval of prefixed words. Journal of Verbal Learning and Verbal Behavior, 14, 638–647.
Taft, M., & Forster, K. I. (1976). Lexical storage and retrieval of polymorphemic and polysyllabic words. Journal of Verbal Learning and Verbal Behavior, 15, 607–620.
Tsai, J. L., Lee, C. Y., Tzeng, O. J. L., Hung, D. L., & Yen, N. S. (2004). Use of phonological codes for Chinese characters: Evidence from processing of parafoveal preview when reading sentences. Brain and Language, 91, 235–244.
Underwood, G., Binns, A., & Walker, S. (2000). Attentional demands on the processing of neighbouring words. In A. Kennedy, R. Radach, D. Heller, & J. Pynte (Eds.), Reading as a perceptual process (pp. 247–268). Oxford: Elsevier.
Underwood, G., Bloomfield, R., & Clews, S. (1988). Information influences the pattern of eye fixations during sentence comprehension. Perception, 17, 267–278.
Underwood, G., Clews, S., & Everatt, J. (1990). How do readers know where to look next? Local information distributions influence eye fixations. Quarterly Journal of Experimental Psychology, 42A, 39–65.
Vainio, S., Hyönä, J., & Pajunen, A. (2009). Lexical predictability exerts robust effects on fixation duration, but not on initial landing position during reading. Experimental Psychology, 56, 66–74.
Vitu, F. (1991). The influence of parafoveal processing and linguistic context on the optimal landing position effect. Perception & Psychophysics, 50, 58–75.
Vitu, F., Brysbaert, M., & Lancelin, D. (2004). A test of parafoveal-on-foveal effects with pairs of orthographically related words. European Journal of Cognitive Psychology, 16, 154–177.
Wang, C. A., Inhoff, A. W., & Radach, R. (2009). Is attention confined to one word at a time? the spatial distribution of parafoveal preview benefits during reading. Attention, Perception, & Psychophysics, 71, 1487–1494.
Warren, T., White, S. J., & Reichle, E. D. (2009). Investigating the causes of wrap-up effects: Evidence from eye movements and E-Z reader. Cognition, 111, 132–137.
Weingartner, K. M., Juhasz, B. J., & Rayner, K. (in press). Lexical embeddings produce interference when they are morphologically unrelated to the words in which they are contained: Evidence from eye movements. Journal of Cognitive Psychology.
Whaley, C. P. (1978). Word–nonword classification time. Journal of Verbal Learning and Verbal Behavior, 17, 143–154.
White, S. J. (2008). Eye movement control during reading: Effects of word frequency and orthographic familiarity. Journal of Experimental Psychology: Human Perception and Performance, 34, 205–223.
White, S. J., Bertram, R., & Hyönä, J. (2008). Semantic processing of previews within compound words. Journal of Experimental Psychology: Learning, Memory, and Cognition, 34, 988–993.
White, S. J., Johnson, R. L., Liversedge, S. P., & Rayner, K. (2008). Eye movements when reading transposed text: The importance of word-beginning letters. Journal of Experimental Psychology: Human Perception and Performance, 34, 1261–1276.
White, S. J., & Liversedge, S. (2004). Orthographic familiarity influences initial eye fixation positions in reading. European Journal of Cognitive Psychology, 16, 52–78.
White, S. J., & Liversedge, S. P. (2006a). Foveal processing difficulty does not modulate non-foveal orthographic influences on fixation positions. Vision Research, 46, 426–437.
White, S. J., & Liversedge, S. P. (2006b). Linguistic and nonlinguistic influences on the eyesʼ landing positions during reading. Quarterly Journal of Experimental Psychology, 59, 760–782.
White, S. J., Rayner, K., & Liversedge, S. P. (2005a). Eye movements and the modulation of parafoveal processing by foveal processing difficulty: A reexamination. Psychonomic Bulletin & Review, 12, 891–896.
White, S. J., Rayner, K., & Liversedge, S. (2005b). The influence of parafoveal word length and contextual constraint on fixation durations and word skipping in reading. Psychonomic Bulletin & Review, 12, 466–471.
White, S. J., Warren, T., & Reichle, E. D. (2011). Parafoveal preview during reading: Effects of sentence position. Journal of Experimental Psychology: Human Perception and Performance, 37, 1221–1238.
Williams, C. C., Perea, M., Pollatsek, A., & Rayner, K. (2006). Previewing the neighborhood: The role of orthographic neighbors as parafoveal previews in reading. Journal of Experimental Psychology: Human Perception and Performance, 32, 1072–1082.
Winskel, H., Radach, R., & Luksaneeyanawin, S. (2009). Eye movements when reading spaced and unspaced Thai and English: A comparison of Thai–English bilinguals and English monolinguals. Journal of Memory and Language, 61, 339–351.
Yan, M., Kliegl, R., Richter, E. M., Nuthmann, A., & Shu, H. (2010). Flexible saccade-target selection in Chinese reading. Quarterly Journal of Experimental Psychology, 63, 705–725.
Yan, M., Kliegl, R., Shu, H., Pan, J., & Zhou, X. (2010). Parafoveal load of word N + 1 modulates preprocessing effectiveness of word N + 2 in Chinese reading. Journal of Experimental Psychology: Human Perception and Performance, 36, 1669–1676.
Yan, M., Richter, E. M., Shu, H., & Kliegl, R. (2009). Readers of Chinese extract semantic information from parafoveal words. Psychonomic Bulletin & Review, 16, 561–566.
Yang, J. (2010). Word recognition in the parafovea: An eye movement investigation of Chinese reading. Unpublished doctoral dissertation. Amherst: University of Massachusetts.
Yang, J., Wang, S., Tong, X., & Rayner, K. (2010). Semantic and plausibility effects on preview benefit during eye fixations in Chinese reading. Reading and Writing. Advance online publication. doi:10.1007/s11145-010-9281-8
Yang, J., Wang, S., Xu, Y., & Rayner, K. (2009). Do Chinese readers obtain preview benefit from word n + 2? Evidence from eye movements. Journal of Experimental Psychology: Human Perception and Performance, 35, 1192–1204
Yang, S. N. (2006). An oculomotor-based model of eye movements in reading: The competition/interaction model. Cognitive Systems Research, 7, 56–69.
Yang, S. N., & McConkie, G. W. (2001). Eye movements during reading: A theory of saccade initiation times. Vision Research, 41, 3567–3585.
Yen, M., Radach, R., Tzeng, O. J., Hung, D. L., & Tsai, J. (2009). Early parafoveal processing in reading Chinese sentences. Acta Psychologica, 131, 24–33.
Yen, M.-H., Tsai, J.-L., Tzeng, O. J.-L., & Hung, D. L. (2008). Eye movements and parafoveal word processing in reading Chinese. Memory & Cognition, 36, 1033–1045.
Zola, D. (1984). Redundancy and word perception during reading. Perception & Psychophysics, 36, 277–284.
Acknowledgments
Preparation of this article was supported by Grant HD26765 from the National Institute of Child Health and Human Development. We thank Marc Brysbaert and Kevin Paterson for their helpful comments on a prior draft. Much of this article is based on the qualifying papers for doctoral candidacy by the first two authors at UCSD. The first two authors contributed equally to the present article.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Schotter, E.R., Angele, B. & Rayner, K. Parafoveal processing in reading. Atten Percept Psychophys 74, 5–35 (2012). https://doi.org/10.3758/s13414-011-0219-2
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13414-011-0219-2