

Article Figures & Data
Figures
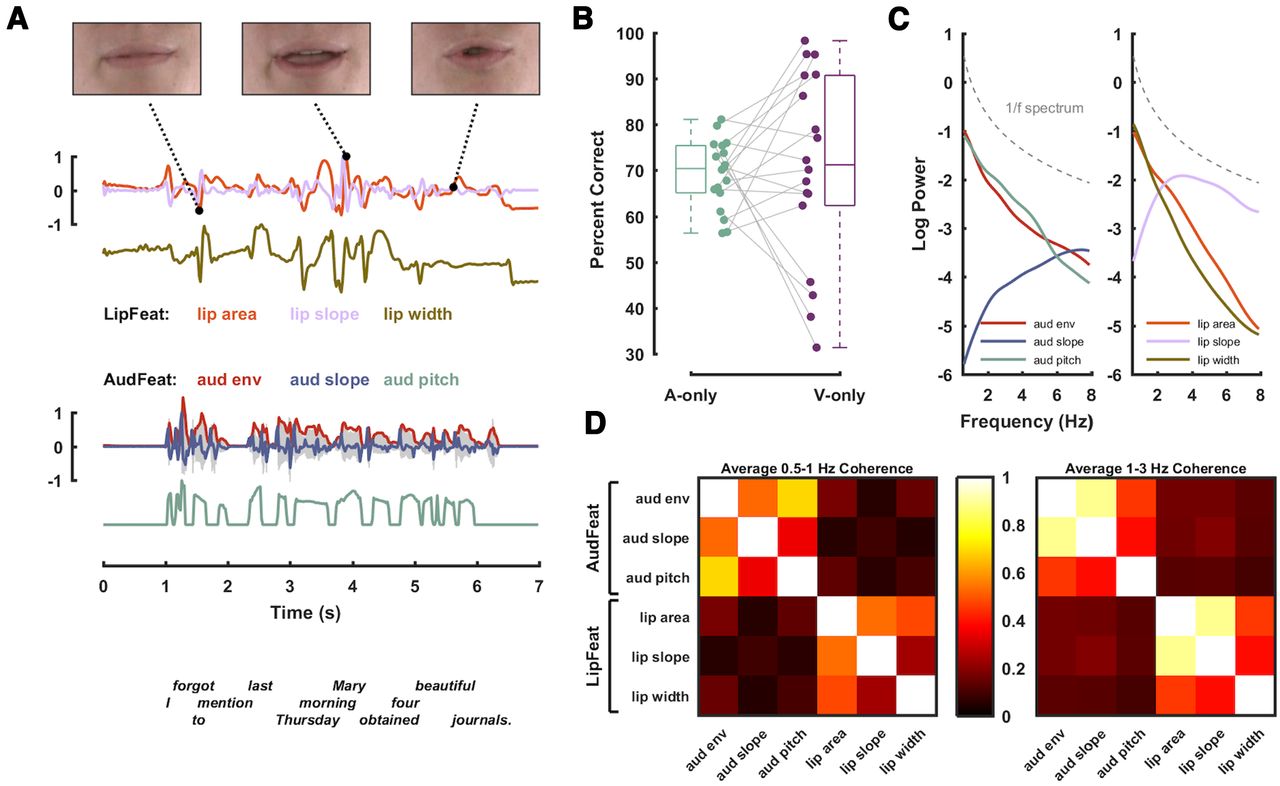
- Figure 1.
Stimulus material and experimental methodology. Acoustic and visual features were extracted from audiovisual speech material and were used to quantify their cerebral tracking during audio-only and visual-only presentations. A, The stimulus material consisted of 180 audiovisual recordings of a trained actor speaking individual English sentences. For visualization, here only the mouth is shown, but participants were presented with the entire face. From the video recordings, we extracted three features describing the dynamics of the lip aperture: the area of lip opening (lip area), its slope (lip slope), and the width of lip opening (lip width); collectively termed LipFeat. From the audio waveform, we extracted three acoustic features: the broadband envelope (aud env), its slope (aud slope), and a measure of dominant pitch (aud pitch), collectively termed AudFeat. B, Trial-averaged percent correctly (PC) reported target words in auditory (A-only) and visual-only (V-only) conditions, with dots representing individual participants. C, Logarithmic power spectra for individual stimulus features. For reference, a 1/f spectrum is shown as a dashed gray line. D, Coherence between pairs of features averaged within two predefined frequency bands (0.5–1 Hz left; 1–3 Hz right; for details, see Materials and Methods).
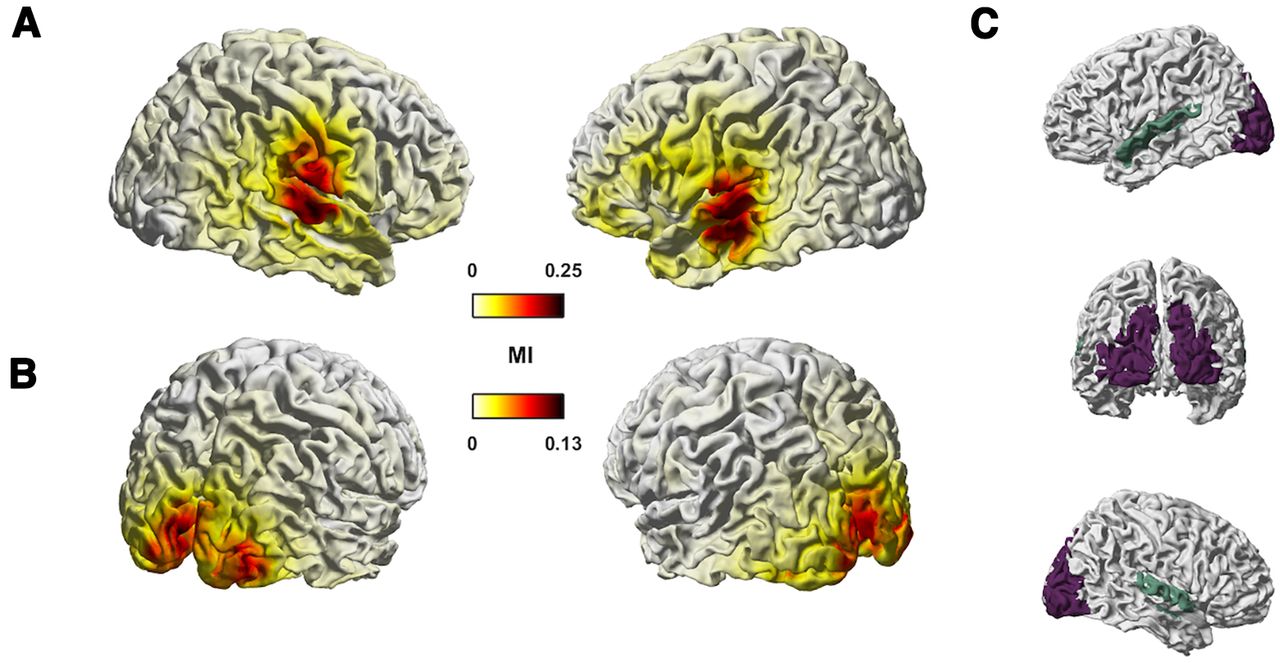
- Figure 2.
Tracking of auditory and visual features in MEG source space. The figure shows group-level median MI values for auditory (AudFeat; A) and lip features (LipFeat; B) in the frequency range from 0.5 to 8 Hz (n = 18 participants). C, Colored shading indicates ROIs: temporal region in mint includes Brodmann area 41/42, caudal area 22 (A22c), rostral area 22 (A22r), and TE1.0 and TE1.2; occipital region in purple includes middle occipital gyrus (mOccG), occipital polar gyrus (OPC), inferior occipital gyrus (iOccG), and medial superior occipital gyrus (msOccG). Unit for MI is in bits.
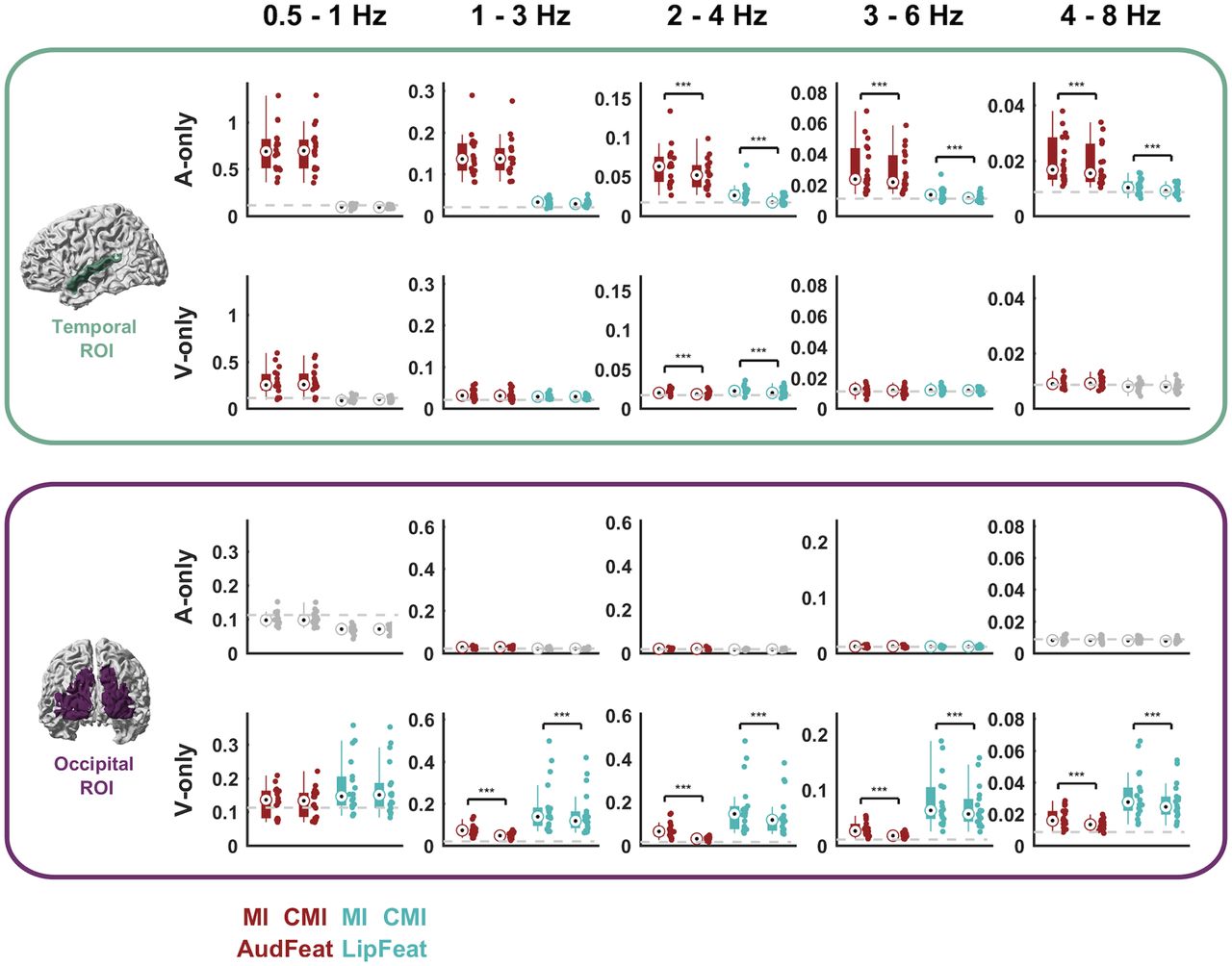
- Figure 3.
Feature tracking across ROIs and conditions. For both conditions (A-only and V-only) and ROIs (temporal and occipital) the figure illustrates the strength of feature tracking for presented and physically not-present features (MI values) and the strength of tracking after partialling out the respective other feature group (CMI values). Each panel depicts (from left to right) the MI for AudFeat, the CMI for AudFeat partialling out LipFeat, the MI for LipFeat, and the CMI for LipFeat partialling out AudFeat. Dots represent individual participants (n = 18). Bars indicate the median, 25th and 75th percentiles. The gray dashed line indicates the 99th percentile of the frequency-specific randomized maximum distribution correcting for all other dimensions. Conditions below a group-level significance threshold of 0.01 are greyed out. Brackets with asterisks indicate significant differences between MI and CMI values, based on a Wilcoxon signed-rank test (*p < 0.01, **p < 0.005, ***p < 0.001). Units for MI and CMI are in bits.
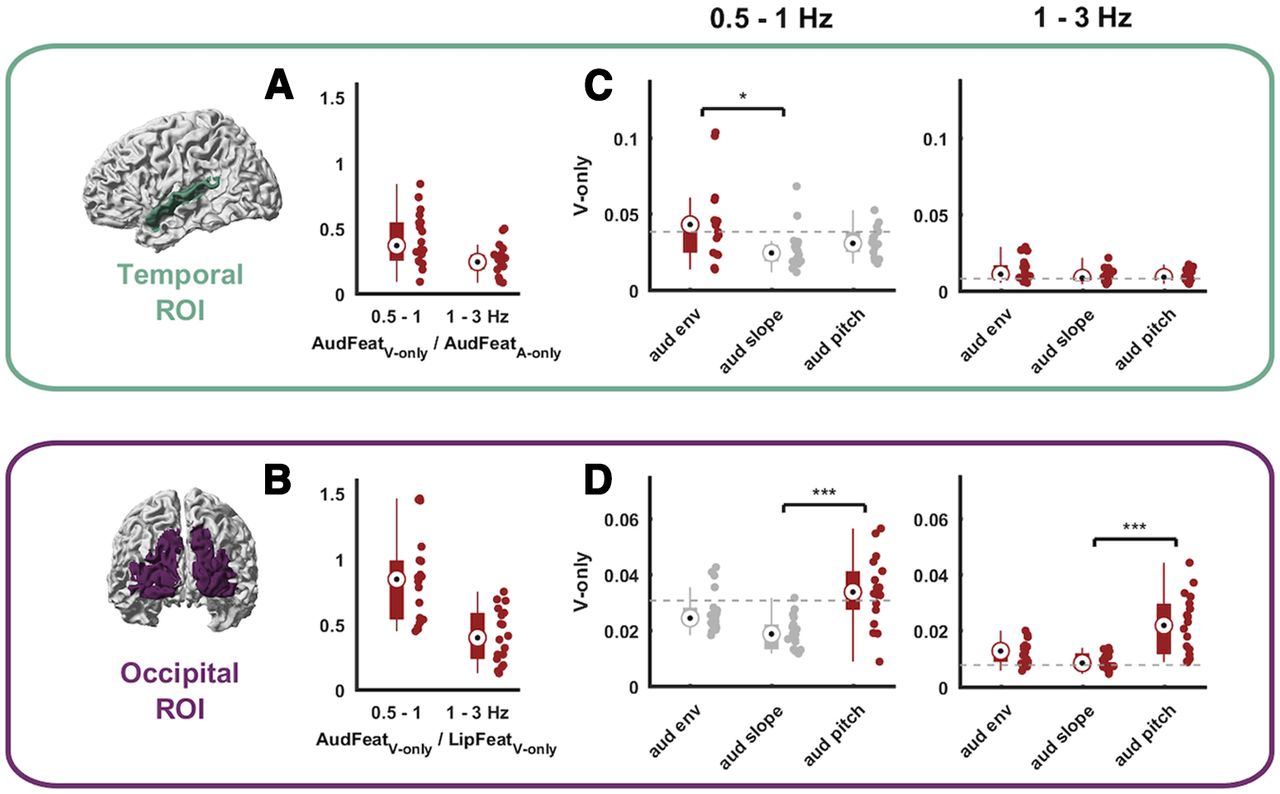
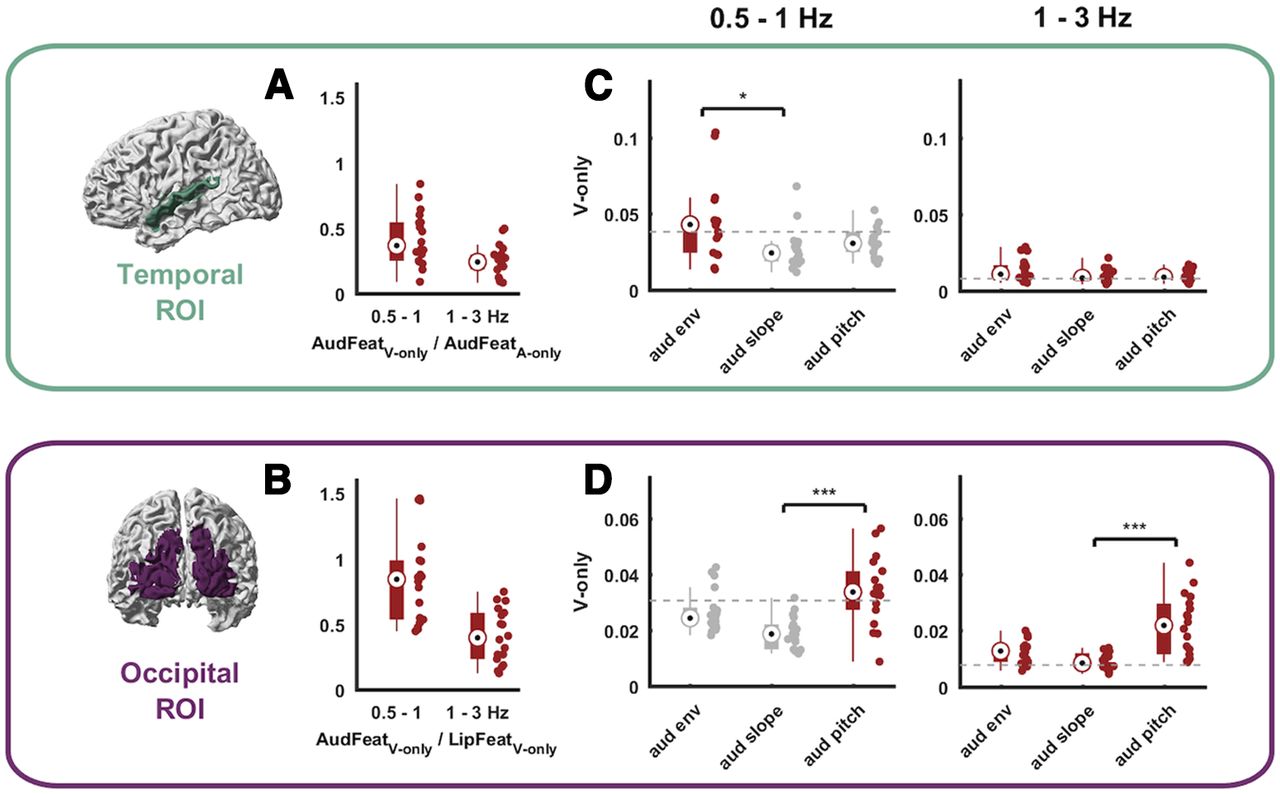
- Figure 4.
Modality dominance and tracking of individual auditory features during lip reading. A, B, Comparison of the tracking of unheard AudFeat over the tracking of the modality-preferred sensory input in each ROI (i.e., AudFeat during A-only trials in the temporal ROI; LipFeat during V-only trials in the occipital ROI). C, D, Tracking of individual auditory features during V-only trials conditioned on all other auditory and lip features in temporal (C) and occipital (D) ROIs. Brackets with asterisks indicate levels of significance from one-way Kruskal–Wallis rank test with post hoc Tukey–Kramer testing (*p < 0.01, **p < 0.005, ***p < 0.001). Dots represent individual data points. Bars indicate the median, 25th and 75th percentiles. The gray dashed line indicates the 99th percentile of the frequency-specific randomized maximum distribution correction for all other features. Units in A, B are a ratio; in C and D, units are in bits.
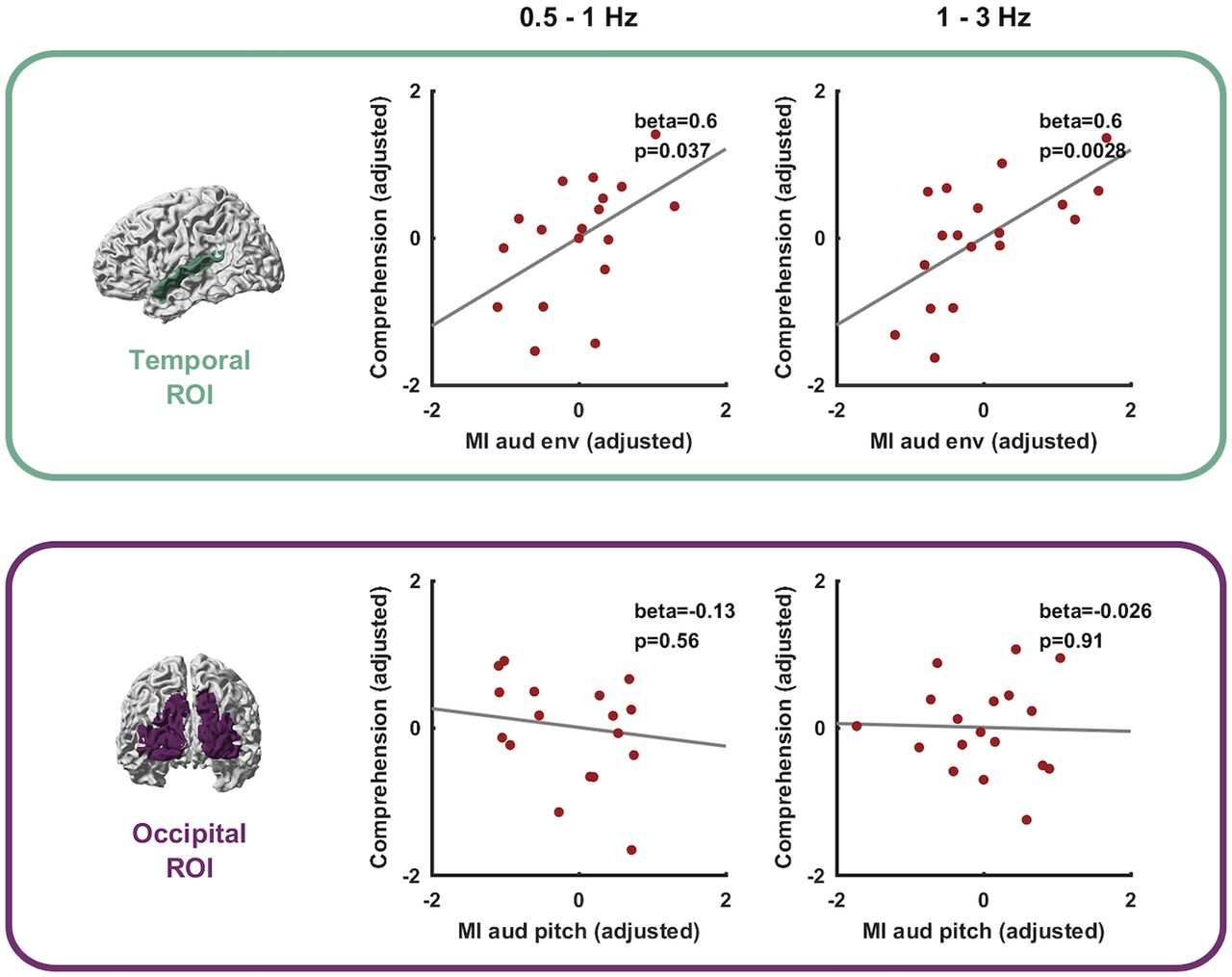
- Figure 5.
Association between lip-reading performance and tracking of auditory features. Across participants the tracking of aud env during V-only trials in the temporal ROI but not the tracking of aud pitch in the occipital ROI was significantly associated with word recognition performance (PC). Graphs show partial residual plots, dots represent individual data points and the line indicates the linear fit to the target variable from the full regression model.



Tables
0.5–1 Hz 1–3 Hz ROI Anatomical area AudCMI Chisq; pval LipCMI Chisq; pval AudCMI Chisq; pval LipCMI Chisq; pval A-only trials Temporal A41/42 0.97 27.02; 4.7e-05 0.096 2.47; 0.59 0.19 29.62; 2.7e-05 0.032 5.14; 0.32 TE1.0/1.2 0.56 0.099 0.11 0.028 A22c 0.86 0.098 0.18 0.033 A22r 0.5 0.093 0.095 0.029 Occipital mOccG 0.1 3.50; 0.47 0.073 0.66; 0.88 0.025 2.71; 0.58 0.02 1.97; 0.66 OPC 0.09 0.069 0.025 0.02 iOccG 0.11 0.068 0.027 0.021 msOccG 0.11 0.074 0.029 0.021 V-only trials Temporal A41/42 0.33 4.59; 0.36 0.1 5.14; 0.32 0.034 5.24; 0.32 0.027 1.00; 0.85 TE1.0/1.2 0.25 0.088 0.031 0.028 A22c 0.34 0.1 0.035 0.027 A22r 0.22 0.085 0.028 0.029 Occipital mOccG 0.13 3.90; 0.44 0.17 12.30; 0.026 0.045 8.20; 0.13 0.15 14.57; 0.012 OPC 0.14 0.19 0.06 0.2 iOccG 0.14 0.2 0.048 0.17 msOccG 0.11 0.11 0.039 0.082 The table lists CMI values of either set of features (AudCMI, LipCMI) and a statistical comparison between the individual atlas-defined areas of the temporal and occipital ROIs [Kruskal–Wallis tests, reporting chi-squares (Chisq) and p-values (pval)]. Bold numbers indicate statistically significant results. P-values are FDR-corrected within this table.
0.5–1 Hz 1–3 Hz ROI Hemisphere AudCMI z; pval LipCMI z; pval AudCMI z; pval LipCMI z; pval A-only trials Temporal Left 0.8 1.20; 0.59 0.094 −0.33; 0.74 0.13 −0.81; 0.59 0.028 −1.11; 0.59 Right 0.64 0.099 0.15 0.031 Occipital Left 0.1 −0.37; 0.74 0.07 −0.33; 0.74 0.027 0.81; 0.59 0.021 0.63; 0.65 Right 0.1 0.072 0.025 0.02 V-only trials Temporal Left 0.31 0.89; 0.59 0.098 0.76; 0.59 0.035 0.85; 0.59 0.025 −1.85; 0.26 Right 0.26 0.091 0.03 0.03 Occipital Left 0.11 −2.24; 0.2 0.14 −2.98; 0.046 0.043 −1.68; 0.3 0.13 −2.07; 0.21 Right 0.15 0.2 0.054 0.18 The table lists CMI values of either set of features (AudCMI, LipCMI) and a statistical comparison between hemispheres of each ROI [Wilcoxon signed-rank tests, reporting z values (z) and p-values (pval)]. P-values are FDR-corrected within this table.
In this issue

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}



