

Article Figures & Data
Figures
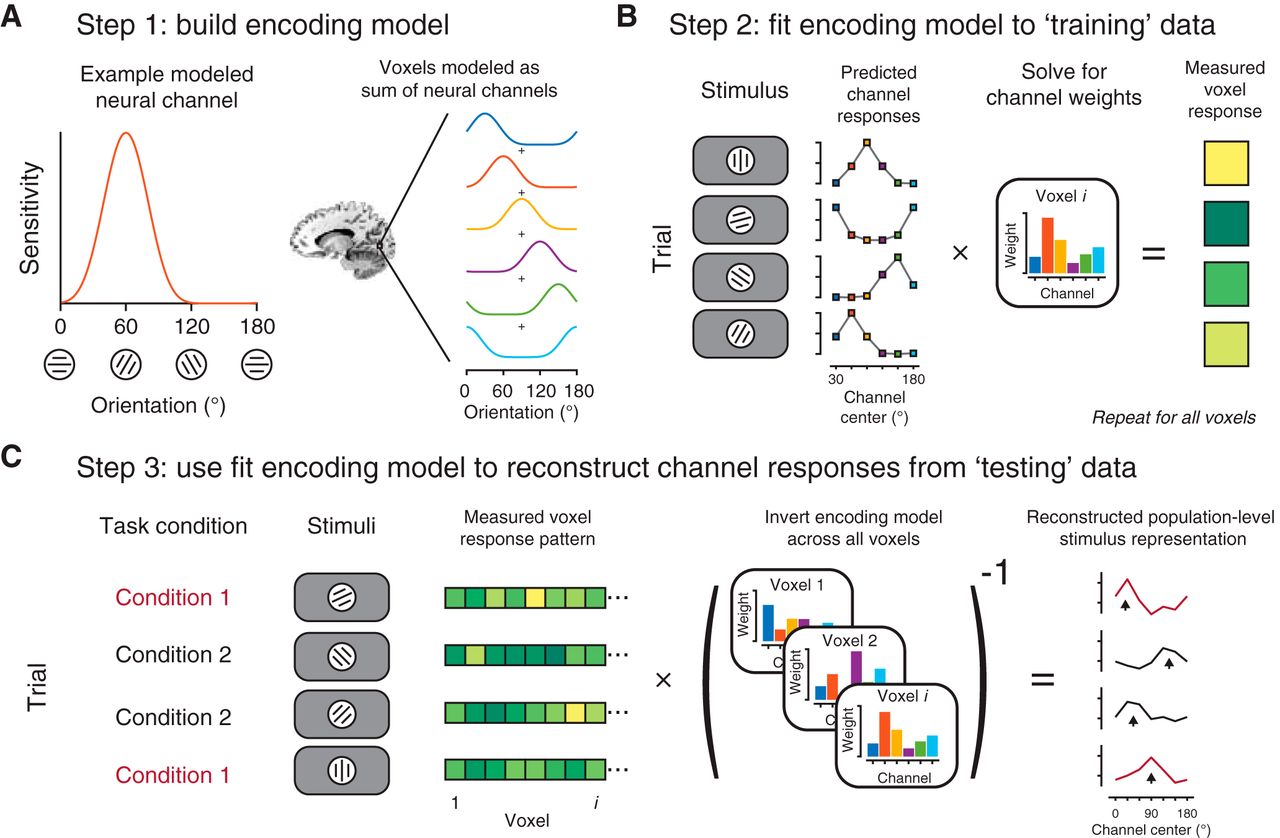
- Figure 1.
IEM: use neural tuning as an assumption to estimate population-level representations. A, The IEM framework assumes that aggregate neural responses (e.g., voxels) can be modeled as a combination of feature-selective information channels (i.e., orientation-selective neural populations). Tuning properties of modeled information channels are experimenter defined and often based on findings in the single-unit physiology literature. B, Once an encoding model (A) is defined, it can be used to predict how each information channel should respond to each stimulus in the experiment. These predicted channel responses are used to fit the encoding model to each voxel’s activation across all trials in a “training” dataset, often balanced across experimental conditions, or derived from a separate “localizer” or “mapping” task. C, By inverting the encoding models estimated across all voxels (typically, within an independently-defined region), new activation patterns can be used to compute the response of each modeled neural information channel. This step transforms activation patterns from measurement space (one number per measurement dimension, e.g., voxel) to information space (one number per modeled information channel, A). These computed channel response functions can be aligned based on the known stimulus feature value on each trial (black arrowheads), and quantified and compared across conditions (e.g., manipulations of stimulus contrast, spatial attention, etc.), especially when a fixed encoding model is used for reconstruction (as schematized here). Cartoon data shown throughout figure.
In this issue

{kind=link}



