Article Text

Statistics from Altmetric.com
Introduction
Upper limb (UL) paresis is a common poststroke outcome. Although rehabilitation can lead to improvements, the benefits are often inconsistent.1 The principles of motor learning may offer ways to increase the efficacy of rehabilitation. This is underpinned by two assumptions: these principles apply to motor recovery and patients retain the ability to learn.2 However, only a few studies have investigated the effect of stroke on motor learning, with mixed outcomes,3–8 and interventions based on motor learning principles are often no more effective than conventional rehabilitation.9
Motor adaptation is a specific form of learning that refers to gradual error reduction in response to a novel perturbation. Patients with stroke retain the ability to adapt, even if at a slower rate than healthy individuals.4 6 7 In particular, error-enhancing force fields (FF), that is, magnifying movement error, appear more beneficial than error-reducing ones, as they lead to after-effects which compensate for the original error.4 10 We focus on motor adaptation as a model process to investigate learning in a standardised way within a single session.
Reward and punishment-based feedback are candidate mechanisms to optimise motor adaptation.11–13 In young healthy participants, punishment was associated with faster adaptation, and reward with greater retention.13 These results point to dissociable effects of reward and punishment in motor adaptation. If these findings generalised to patients, they would provide a principled way for enhancing motor adaptation and retention in stroke survivors. This would be in line with previous research showing the benefits of rewards during ankle boot training in stroke survivors.14 Using a FF adaptation reaching task, we tested this in 45 patients with chronic stroke. We show that reward and punishment-based feedback enhance motor adaptation in patients with stroke, and that reward increases the retention of the new motor behaviour.
Materials and methods
Study population
We included patients meeting the following criteria: (1) first-ever unilateral chronic (>6 months) stroke; (2) Mini Mental Scale Examination (MMSE)15 >24; (3) ability to perform 45° shoulder flexion while UL supported; (4) ability to be active for an hour; (5) no UL therapy during the study duration; (6) ability to understand the task and give written informed consent. Patients were excluded if they met any one of the followings: (1) ataxia/cerebellar stroke; (2) alcohol/drug abuse; (3) peripheral motor problems; (4) major psychiatric/other neurological disorders; (5) vision/hearing impairment; (6) neglect (Bells test);16 (7) shoulder pain/musculoskeletal impairment preventing passive ranging to the workspace; (8) <18 years old.
We screened 75 stroke survivors, and included 45 (online supplementary figure 1). Patients were randomly allocated to one of three groups, according to the feedback given during adaptation (reward/punishment/neutral). Randomisation was stratified for age and time poststroke. Fifteen healthy controls, matched to the neutral group for age and performing arm, were also included.
All participants gave written informed consent. The study was approved by the Joint Ethics Committee of the Institute of Neurology, UCL and the National Hospital for Neurology and Neurosurgery and was conducted in accordance with the Declaration of Helsinki.
Experimental task
We used a FF adaptation paradigm.17 Participants sat with their forehead supported in front of a workstation while holding the handle of a two-joint robotic manipulandum with their paretic arm. The forearm was stabilised by straps to a moulded cast and the trunk was belted to a chair. A horizontal mirror, 2 cm above the hand, prevented direct vision of the arm, but showed a reflection of a screen mounted above. Visual feedback regarding hand position was provided by a white cursor (0.3 cm diameter) continuously projected onto the screen (figure 1A).

Task and protocol overview. (A) Experimental setup. (B) Experimental task. Participants moved the cursor from the starting point (central square) to a target on the screen. On day 1, they had to reach towards one of eight targets, appearing in a pseudorandom order (null field day 1). On days 2 and 3, participants reached towards two selected targets which were chosen based on minimising baseline error (null field days 2 and 3). The perturbation consisted of a velocity-dependent force field (FF, red arrow) in the direction which increased baseline error (clockwise vs counterclockwise). Reward and punishment feedback were represented by positive and negative points based on movement error, two uninformative zero instead of points appeared on the screen for the neutral group. (C) Experimental protocol. Participants were tested across three consecutive days. On day 1, they performed unperturbed reaching movements towards eight targets (baseline: 6 blocks of 80 trials). Day 2 began with unperturbed reaching movements towards two targets (baseline: 2 block x 50 trials). This was followed by movements that were perturbed by a FF (adaptation: 7 blocks x 50 trials) and in which participants received feedback according to their group (neutral, punishment or reward feedback). Finally, participants experienced another set of unperturbed trials (washout: 3 blocks x 50 trials). Day 3 was identical to day 2, except all groups received neutral feedback during the readaptation phase.
The task consisted of centre-out fast ballistic movements to targets. Subjects had to initially bring the cursor within a 1 cm2 starting box in front of the body’s midline. Once the cursor was within the starting point, a white 1 cm2 target appeared 6 cm from the starting position. Subjects were instructed that, when ready, they should make a fast, accurate, ‘shooting’ movement through the target, avoiding corrections. As the cursor crossed an imaginary 6 cm radius circle centred at the starting position, a green endpoint dot appeared. After 500 ms, the manipulandum returned the hand back to the start. For the main experiment, subjects were exposed to two targets. To encourage constant speed, the target turned red or blue if the movement was >500 or <100 ms, respectively (figure 1B).
For FF trials, the manipulandum produced a force proportional to the hand velocity. For a clockwise (CW) curl field (pushing to the right) the force was

For counterclockwise (CCW) curl fields, the force direction was mirrored.17
Reward and punishment feedback
The reward group accumulated positive points, the punishment accumulated negative points and the neutral received no points. Points were calculated based on angular error as follows:
Reward: 4 points: <1°; 3 points: 1°–5°; 2 points: 5°–10°; 1 point: 10°–15°; 0 points: ≥15°.
Punishment: 0 points: <1°; −1 point: 1°–5°; −2 points: 5°–10°; −3 points: 10°–15°; −4 points: ≥15°.
Neutral: points were replaced by two zeros.
Both the points received on a trial-by-trial basis and the cumulative score of the block were shown (figure 1B). Subjects were informed that points had monetary value (3.57 pence/point) and depended on performance. The reward group started from £0 and earned money based on the accumulated points (£24.7±2); the punishment group was initially given £50 and lost money based on the cumulative negative points (average lost £24.5±1.7). The neutral group received £25 on day 3.
Experimental protocol
The same examiner tested all subjects across three consecutive days (figure 1C). Each session lasted around 2.5 hours. As sleep can enhance memory consolidation,18 participants were encouraged to sleep > 6 hours every night, and sleep was assessed with a questionnaire.19
Day 1 (D1): individual calibration of targets and perturbation
To ensure relatively accurate behaviour across patients and to select an error-enhancing FF, on D1 participants familiarised with the task (six blocks, 80 trials each) with null trials (no FF) towards eight targets (25°, 65°, 115°, 155°, 205°, 245°, 295° or 335° CW from 0°, with 0° representing 12 on a clock). Based on performance, we selected for each subject the two targets in the same quadrant with the smallest average error and the FF direction (CW or CCW) enhancing this baseline error.
Day 2 (D2): adaptation under reward, punishment or neutral feedback
Participants were randomly allocated to the reward, punishment or neutral group (between-subject design) and performed 12 blocks (50 trials each) of reaching movements towards the two selected targets. Two baseline blocks were followed by seven adaptation (CW or CCW FF) blocks, with reward/punishment/neutral feedback according to group allocation. In the washout (three blocks), FF and reward/punishment/neutral feedback were removed to return performance to baseline. Participants were informed before beginning that they should expect the manipulandum to interfere with their performance, and that they should perform accurately while maintaining a constant speed. Short breaks were given after the second, fifth and tenth block. Participants could rest for a few minutes in between blocks if necessary.
Day 3 (D3): readaptation at 24 hours
Participants were exposed to the same blocks as D2, but received neutral feedback.
Cognitive tests and functional scales
To take into account possible confounding variables, subjects underwent a battery of validated tests and scales (online supplementary table 1). The MMSE and the Bells test were used to assess eligibility. We then assessed executive functions, apathy, depression, fatigue and sensitivity to reward and punishment. We used the Barthel Index to evaluate general functional level,20 the Fugl-Meyer Assessment,21 the Modified Ashworth Scale6 22 and the Medical Research Council Scale for strength6 23 for the paretic UL. Handedness was evaluated using the Edinburgh Inventory.24 At the end of each visit, participants scored alertness and fatigue on a visual analogue scale.
Data collection and analysis
The 2D (x,y) position of the hand was collected through custom C++ code (sampling rate=100 Hz). Data and statistical analysis were performed using Matlab (MathWorks, USA) and SPSS (IBM, version 21.0). Movement onset was defined as the point at which velocity crossed 10% of peak velocity. Movement endpoint was defined as the position where the cursor breached the 6 cm target perimeter. To compare between subjects, errors of subjects receiving the CW FF were flipped.
Performance was quantified using angular error at peak velocity (AEmaxV), that is, the difference between the target angle and the angular hand position at the peak outward velocity (o). This has been used as a measure of feedforward control while excluding feedback processes.25 To adjust for between-subjects baseline directional biases, AEmaxV on D2 and D3 were corrected by subtracting the average baseline AEmaxV of the corresponding day.26 27 Reaction time (RT, time between target appearance and movement onset); movement time (MT, time between movement onset and movement end); peak velocity (MaxV); maximum velocity percentage (MaxV%, time point in movement when MaxV occurred); within subject variability (SD of AEmaxV); and online corrections (difference between AEmaxV and angular endpoint error) were calculated for each trial. Trials in which angular error exceeded 60o 13 or MT or RT exceeded 1150 ms (representing the mean +2.5 SD for both MT and RT) were removed (6.8% of trials). Epochs of all kinematics were created by averaging across 10 consecutive movements.27 28
Differences between demographics, cognitive and functional scores were evaluated by one-way analysis of variance (ANOVA, quantitative data) or χ2 or Fisher’s exact test (proportions). Repeated-measures ANOVAs were used to compare MT, RT, MaxV, MaxV% and online corrections between groups (N,R,P) and phases (baseline,adaptation/readaptation,washout).
Due to the unfamiliarity with the manipulandum, unperturbed trials during D1 were also subject to a process of correction.29 30 To evaluate this, we computed average sum of squared AEmaxV during the first and last block of D1, and performed a repeated-measures ANOVA with group (N,R,P) and block (first,last). We used sum of square as we were interested in the absolute magnitude of the error, irrespective of direction.
To assess the amount of learning/adaptation independently from the co-contraction (ie, stiffening) of the arm, we computed an adaptation index (AI):29

We considered as ‘after-effect trials the ones representing the initial error after the removal of the FF. To select these, we performed an ANOVA across the average of every 2 trials for the first 10 trials (five levels). On both days, we found a significant effect of trials (D: F (4,144)=21, p<0.001; D3: F (4,148)=15.38, p<0.001). Post-hoc tests showed a significant difference between trials 1–2 and 3–4 (D2: p=0.004; D3: p<0.001), and 3–4 and 5–6 (D2: p<0.001, D3: p=0.033). Based on this, we selected as ‘after-effect trials’ the first six trials after FF removal. Results were qualitatively similar by using an average between two and six trials. We defined as ‘force-field trials’ the last block of the adaptation or readaptation. The AI could range 0, indicating no learning (but possibly co-contraction), to 1, indicating complete learning.29 This is based on the premise that learning is represented by zero error for FF trials but a large error in after-effect trials (AI=1); no learning will lead to a large error in FF but zero error in the after-effect trials (AI=0); and arm stiffening would cause zero error in both (AI=0).
To assess retention, that is, the strength of the new motor memory, we calculated the average AEmaxV across the last two washout blocks for D2 and D3 (AEretention).13
To account for differences in motor and cognitive functions, a principal component analysis was conducted on the functional and cognitive scores, with varimax orthogonal rotation. The Kaiser-Meyer-Olkin (KMO=0.72) measure verified the sampling adequacy, and all KMO values were >0.6. Bartlett’s test indicated that correlations were sufficiently large (χ2 (45)=136.36, p<0.001). Three components had eigenvalue over Kaiser’s criterion of 1 and explained 71% of the variance. We interpreted the first component as the motor level, the second as the psychomotor level and the third as the cogniti ve level (online supplementary table 2). We used these components as covariates in independent one-way analysis of covariance (ANCOVAs) to compare groups for AI D2, AI D3, AEretention D2 and AEretention D3.
To assess savings, that is, the presence of faster readaptation when re-exposed to the same perturbation,31 we calculated an average AEmaxV for the first two perturbation blocks and performed a repeated measure ANOVA with groups (N, R, P) and days (D2, D3).32
No statistical methods were used to predetermine the sample size, but this is in line with similar studies on motor learning in stroke.3–8 Data were tested for normality using the Shapiro-Wilk test. Homogeneity of variance was evaluated using Mauchly’s or Levene tests. When sphericity was violated, Greenhouse-Geisser (if epsilon, ε<0.75) or Huynh-Feldt (if ε>0.75) corrections or Brown-Forsythe tests were used. Significance level was set at p<0.05. Least Significant Difference (LSD) post hoc tests were conducted when warranted. Effect size are reported as partial eta (η2).
Results
Demographics and cognitive functions were similar between groups
Demographic and cognitive parameters were similar between groups (table 1 and online supplementary table 3). Healthy controls were similar to patients for age and main cognitive tests (online supplementary table 4).
Patients’ demographics and clinical characteristics
Day 1: baseline performance was similar across groups
MT, RT, MaxV, online corrections and variability on D1 were not significantly different across the patients groups (online supplementary tables 5 and 6). The average sum of squared AEmaxV in the first and last block of D1 was different across blocks (F (1,42)=17.57, p<0.001, η2=0.295), but not between groups (F (1,42)=0.62, p=0.541, η2=0.029), with no group×block interaction (F (2,42)=0.695, p=0.505, η2=0.032). This indicates similar baseline capability to correct for error across groups.29 30
For each participant, we then chose the target quadrant with the least amount of error, and the FF direction (CW vs CCW) that enhanced this error (online supplementary table 7).
Days 2 and 3: reward and punishment effects on adaptation and retention
Kinematics, baseline performance and initial perturbation were similar across groups
Movement kinematics were similar across groups (online supplementary tables 5 and 6). As expected, following target selection, variability was lower on D2 and D3 than D1 (F (1,42)=101.7, p<0.001, η2 =0.708), but with no differences between groups (F (2,42)=0.34, p=0.715, η2=0.016) (online supplementary table 8).
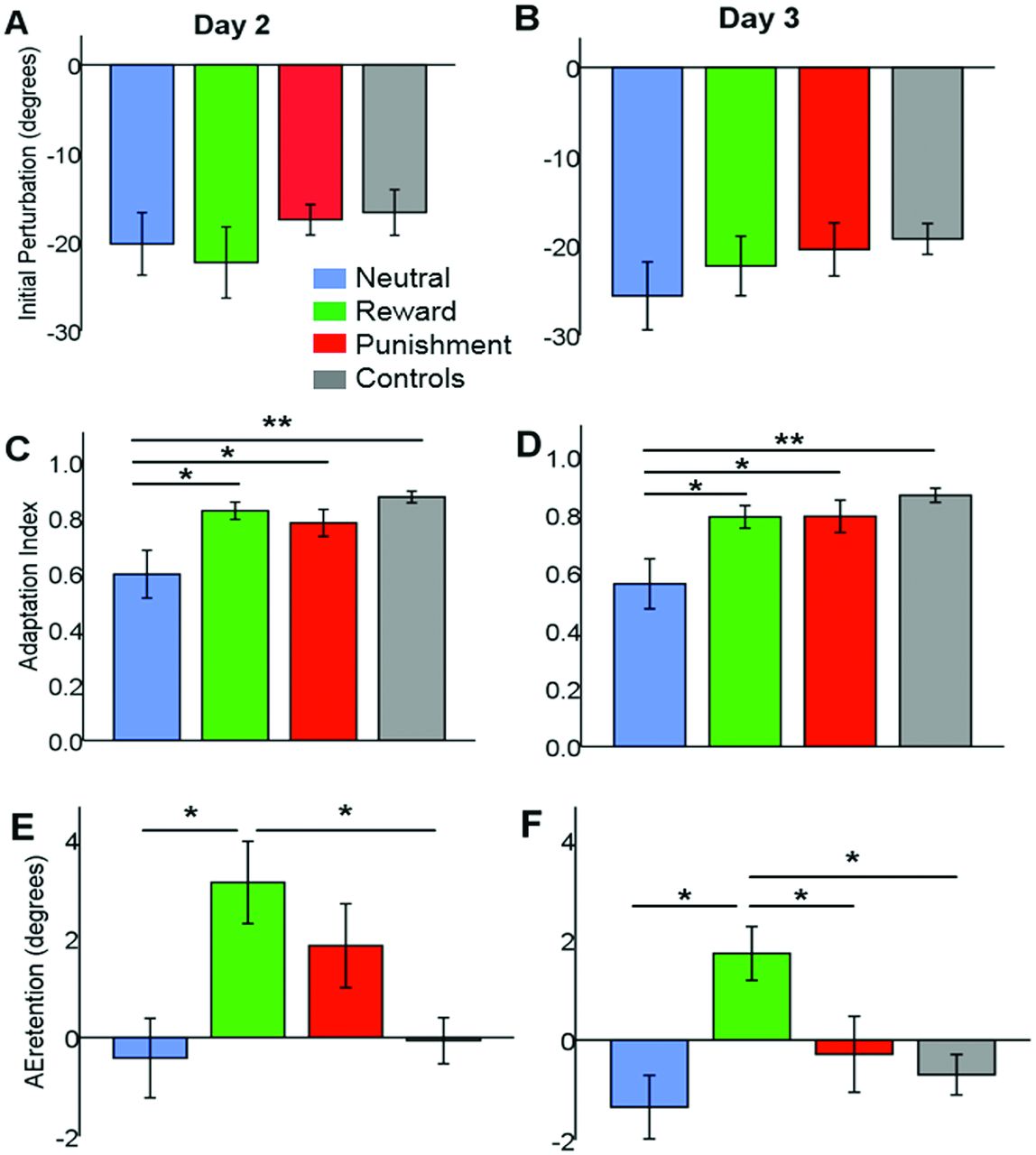
Baseline AEmaxV was similar across patients groups on both D2 (N:0.46±0.81°, R:−1.6±1°, P:−0.96±0.65°, F (2,42)=1.5, p=0.235, η2=0.067) and D3 (N:0.13±0.67°, R:−0.2±0.74°, P:1.1±0.94°, F (2,42)=0.7, p=0.497, η2=0.033; figure 2). The FF caused a similar initial perturbation across the three groups on both D2 (average AEmaxV across first two trials of FF, F (2,42)=0.5, p=0.577, η2=0.026; figure 3A) and D3 (F (2,42)=0.6, p=0.551, η2=0.028; figure 3B).

Average group data for day 2 (D2) and day 3 (D3). D2 and D3 angular error (degrees) at max velocity are shown during baseline, (re)adaptation and washout for the neutral stroke (blue), punishment stroke (red), reward stroke (green) and neutral healthy control (grey) groups. Values are mean (line)±SEM (shaded area) across epochs (average of 10 trials).
{kind=link}
{kind=link}
{kind=link}
The initial perturbation (average angular error at peak velocity across the first two trials under force field) was similar across groups on (A) day 2 (adaptation) and (B) day 3 (readaptation). (C) Adaptation index (AI)—ranging from 0 (no learning) to 1 (perfect learning) and evaluating learning independently from arm co-contraction—on day 2 (adaptation) was significantly lower in the neutral stroke group compared with the punishment stroke, the reward stroke and the neutral healthy controls groups. (D) AI on day 3 (readaptation) was significantly lower in the neutral stroke group relative to the punishment stroke, reward stroke and neutral healthy control groups. (E) AEretention on day 2—referring to the average angular error at peak velocity across last two washout blocks—was higher in the reward stroke group than in the neutral stroke group and the neutral healthy control group. No significant difference was found between the reward and punishment stroke groups. (F) AEretention on day 3 was significantly higher in the reward stroke group versus the neutral stroke, punishment stroke and neutral healthy control groups. *p<0.05, **p<0.001.
Reward and punishment were associated with greater adaptation and readaptation
Although all groups adapted, the reward and punishment group did to a greater extent (figure 2). After controlling for motor, psychomotor and cognitive functions, we found a significant effect of group on D2 AI (F (2,39)=3.422, p=0.043, η2=0.149; figure 3C), with lower adaptation in the neutral versus the reward (p=0.019) or punishment (p=0.050) groups.
Despite reward/punishment only being provided on D2, the improvements were maintained 24 hours later. Specifically, after controlling for the covariates, we found a main effect of group on D3 AI (F (2,39)=3.271, p=0.049, ηη2=0.144; figure 3D), once again with lower readaptation in neutral than either the reward (p=0.038) or punishment (p=0.029) groups.
Reward was associated with higher retention
All groups displayed substantial after-effects during washout on both D2 and D3 (figure 2), but the retention of this after-effect was different across patient groups (D2 AEretention; F (2,42)= 3.425, p=0.043, η2=0.149; figure 3E), with the neutral retaining less than the reward group (p=0.016). Interestingly, on D3 (F (2,42)=7.102, p=0.002, η2=0.267; figure 3F), the reward group displayed a greater amount of retention than either the neutral (p=0.001) or punishment (p=0.008) groups.
No savings were observed across the groups, with no effect of group (F (2,42)=1.8, p=0.179, η2=0.079) nor day (F (1,42)=0.37, p=0.544, η2=0.009).
Healthy controls adapted similarly to the reward and punishment groups but retained less
Although our focus was on patient groups, we also tested a group of age-matched healthy controls under neutral feedback. These showed less variability (overall variability: 6.1±0.2, F (3,56)= 7.17, p<0.001, η2=0.278) and faster RTs than patients but no differences in other kinematic parameters (online supplementary tables 9 and 10), nor baseline AEmaxV(D2: F (3,56)=1.3, p=0.284, η2=0.065; D3: F (3,56)= 0.67, p=0.575, η2=0.035) or initial perturbation (D2: F (3,56)=0.7, p=0.556, η2= 0.036; D3: F (3,56)=0.82, p=0.485, η2=0.042).
Healthy controls adapted and readapted. Adaptation was significantly different across groups (D2 AI: Brown-Forsythe F (3,28.5)=5.3, p=0.005; figure 3C), with controls performing similar to the reward (p=0.51) and punishment (p=0.217) groups but significantly better than the neutral stroke (p<0.001) group. The same was observed for readaptation (D3 AI: Brown-Forsythe F (3,33.2)=5.6, p=0.003, figure 3D), with controls adapting more than the neutral (p<0.001), but similarly to the reward (p=0.353) and punishment (p=0.365) stroke groups.
Interestingly, despite adapting and readapting as the reward and punishment groups, controls retained less than the reward group (D2: p=0.004; D3: p=0.006). Controls showed no savings (p=0.174).
Discussion
We show for the first time that providing reward or punishment-based feedback to patients with stroke during a motor adaptation task can bring their performance to the levels of healthy subjects of the same age range. More strikingly, reward increases the retention of the new motor behaviour to a level even higher than healthy subjects.
Reward and punishment increased learning
Although experiencing 350 trials, patients within the neutral group were unable to fully adapt. Remarkably, by providing reward or punishment, patients showed nearly full adaptation, similar to healthy controls. This was not explained by any differences in cognitive or functional scores between groups. Furthermore, day 1 performance was similar between patient groups, suggesting comparable baseline ability to correct for error. Finally, by individually tailoring the task on days 2 and 3, we further limited any possible influence of between-subject differences.
We previously showed in young healthy subjects that punishment led to faster adaptation, whereas reward caused greater retention.13 We partially replicated these results, but found both punishment and reward associated with increased adaptation. One could argue that this effect may have been partially triggered by the knowledge of results provided by the feedback.34 Nevertheless, our points system was unlikely to provide substantial amount of information in comparison to the visual feedback itself (ie, 1 point represented a range of at least 5°). Second, patients’ sensitivity to feedback could be different to young healthy subjects. However, although ageing is associated with reduced sensitivity to reward and punishment, the relative difference indicates an age-related hypersensitivity to reward.35 Therefore, if we assume that younger adults’ greater sensitivity to punishment during adaptation represents the expected difference (loss aversion), then the results of the patients with stroke (older adults) could demonstrate a hypersensitivity to reward. This also suggests that the specific effect of punishment on adaptation found in our previous work may be explained through loss aversion, rather than the hypothesised effect on cerebellar activity.13
The improvements observed in the reward and punishment groups were maintained 24 hours later despite no further motivational feedback being provided. However, across all groups, we observed no savings. This is most likely due to the 250 washout trials and the 24 hour gap between adaptation blocks, both of which are known to significantly impair savings.36 These results indicate that reward/punishment can enhance within-session adaptation in patients with stroke, and by making them learn better in the first place could have long-lasting benefits even when the feedback is no longer provided.
Reward increased retention
Motor adaptation paradigms are already being implemented in some rehabilitation settings, such as gait rehabilitation.10 Nevertheless, the acquired motor behaviour is quickly forgotten, thus limiting the use of these paradigms in clinical practice. We found here that rewarding patients during adaptation increased retention. Most importantly, this effect was still present after 24 hours, with patients who had been rewarded retaining even more than controls. This is in line with previous evidence,11 13 14 and is a promising step towards the use of reward and motor learning paradigms in rehabilitation.
One caveat of using the after-effect as measure of retention is that this is influenced by the forgetting of what has been previously learnt (true retention), and by simultaneous learning from movement errors.37 Retention can be assessed using error-clamp trials,38 but these provide additional reward because patients are always successful in these trials. Nevertheless, the size and persistence of an after-effect during washout trials with vision has been used numerous times as a proxy of retention.4 10
Implications
Clinically meaningful motor improvements in patients with chronic stroke generally appear possible only with a large amount of contact hours.39 Therefore, developing interventions that reduce the amount of hours required is crucial. This exploratory study highlights for the first time the potential of targeted motivational feedback as a tool to enhance the amount of learning and retention within and between sessions. Motor adaptation was used here as a model process, and further investigations on the effects of reward/punishment feedback over long-term training regimes are warranted. Robotic devices already in use in clinical rehabilitation could produce error-enhancing FFs although improvements from robot-assisted therapy may not generalise to everyday life activities.40 Therefore, how the improvements seen with motivational feedback could be administered within a setting where more practical behaviours are learnt remains a relevant question.
Conclusions
We showed that reward and punishment enhance motor adaptation in patients with stroke to similar level as controls. These improvements are maintained across 24 hours. Our findings suggest that the engagement of motivational processes during motor learning-based therapies could be a promising adjunct to rehabilitation. This will motivate further investigation about the long-term effects of motivational feedback, and thus avenues for translating these promising results into rehabilitation.
Acknowledgments
The authors thank Ulrike Hammerbeck for her comments on the study design, and the Stroke Association and Different Strokes for their help with recruitment. GQ would like to dedicate this work to the memory of Professor Francesco Le Pira.
References
Footnotes
Funding This work was supported by a European Research Council Starter Grant (ActSelectContext, 260424 to SB) and Starter Grant (MotMotLearn, 637488 to JG).
Competing interests None to be declared.
Provenance and peer review Not commissioned; externally peer reviewed.
Linked Articles
- Editorial commentary